Computer Science/Machine learning
7. Support Vector Machine
- -
728x90
반응형
Functional Margin and Geometric Margin
What is the difference
The key difference between the functional margin and geometric margin is that the functional margin is defined for every data point, whereas the geometric margin is defined only for the data point closest to the decision boundary. The geometric margin is often used as a measure of the generalization performance of a linear classifier, as it captures how well the classifier can separate new data points that are similar to the training data.
Functional Margin
Given a training example , we define the functional margin of with respect to the training example
Note that if , then for the functional margin to be large (i.e. for our prediction to be confident and correct), we need to be a large positive number. Conversely, if , then for the functional margin to be large, we need to be a large negative number.
💡
means that our prediction on this example is correct. (i.e. a large functional margin represents a
confidentand a correct predictionGiven a training set , we can define the functional margin of with respect to S to be the smallest of the functional margins of the individual training examples. Denoted by , this can be written as
However, there’s one property of the functional margin that makes it not a very good measure of confidence. This is because if we replace with and with , then since , this would not change the result of classifier (Since, classifier and depends only on the sign, but not on the magnitude.
💡
where if , and otherwise
This means that we can scale and without changing the result of classifier. Intuitively, it might therefore makes sense to impose some sort of normalization condition such as (i.e. we can replace and with and respectively. So the concept of geometric margin arises.
Geometric margin
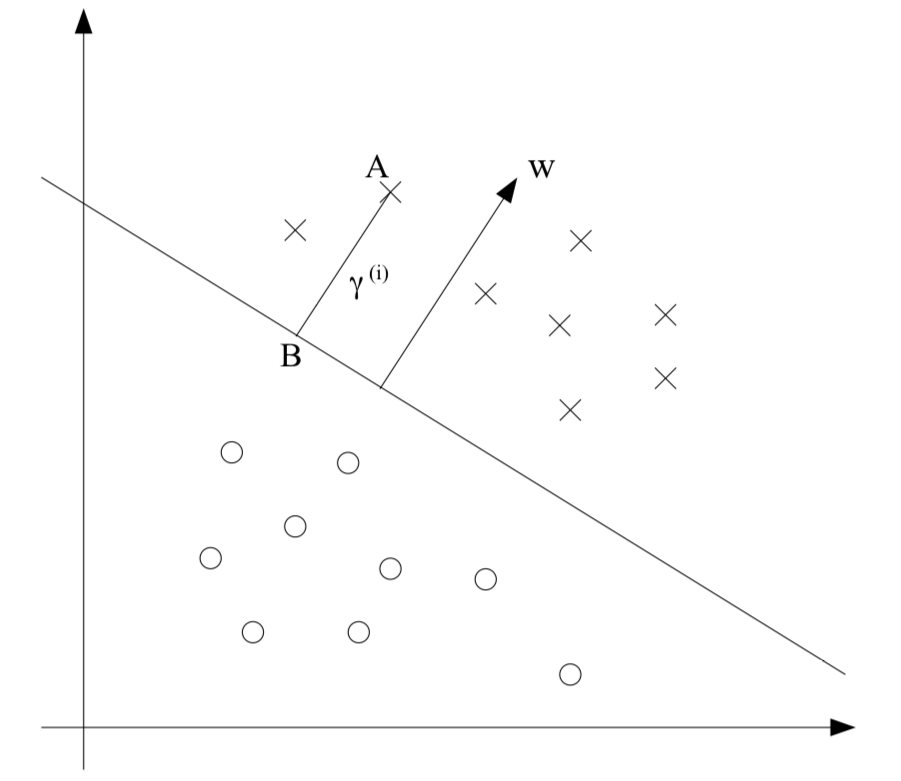
We want to show that geometric margin is not only the normalizing functional margin but also the actual geometric distance between the datapoint and the decision boundary. Since we already know that represents , we therefore find that the point is given . In addition, we already know that the point lies in the decision boundary. Therefore
Solving for yields
💡
Therefore, the geometric margin must be interpreted as a normalized functional margin and the geometric distance between datapoints and the decision boundary.
Therefore, the geometric margin is invariant to rescaling of the parameters.
In addition, given a training set , we also define the geometric margin of with respect to to be the smallest of the geometric margins on the individual training examples:
The optimal margin classifier
Given a training set, we want to find the optimal decision boundary that maximizes the geometric margin. We will assume that we are given a training set that is linearly separable.
💡
If the training set that is not linearly separable, it can be solvable by using regularization. This concept will discuss later.
So, we want to solve the following optimization problem
But this optimization problem has “” constraint which is not a convex. So, we have to reformulate the above optimization problem as follows
However, the objective function() still non-covex function, so we need to step further. Recall our earlier discussion that we can add an arbitrary scaling constraint on and without changing anything. By using this fact, we want to make the functional margin of with respect to the training set to be :
Therefore, the optimization problem is reformulated as follows
However, the objective function() still non-convex function, so we need to step further.
It’s easily show that maximizing is equivalent to minimizing which is convex. Finally, therefore, we can derive the optimization problem as follows
Although the above objective function can be solved by quadratic programming, if we use Lagrange duality , we can use kernels to get optimal margin classifiers to work efficiently in very high dimensional space.
💡
In addition, the dual form typically do much better than generic QP software
Lagrange duality
Consider a problem of the following form:
This problem could be solved by Lagrange multipliers. In this method, we can define the Lagrangian to be
Here, the ’s called the Lagrange multipliers . We would then find and set ’s partial derivative to zero:
and solve for and . The above optimization problem only has equality constraint. What if the optimization problem has inequality constraint such as
To solve it, we start by defining the generalized Lagrangian.
Consider the quantity
where means primal . We can easily find that
Therefore, our original optimization problem can be reformulated as follows
Now, let’s look at a a slightly different problem. Define
where means dual. We can define the dual optimization problem:
💡
The key difference between the original optimization problem and the dual optimization problem is
the order of min and max.Normally, . However, under certain conditions, we will have
💡
Under such condition, we can solve the original optimization problem via solving the dual optimization problem.
if these conditions hold.
- and the ’s are convex, and ’s are affine.
- The constraints are strictly feasible; this means that there exists some so that for all .
Under above assumptions, there must exist so that is the solution to the primal problem. are the solutions to the dual problem, and moreover . Moreover, and satisfy the KKT conditions , which are as follows:
Moreover, if some satisfy the KKT conditions, then it is also a solution to the primal and dual problems.
💡
This means that converse is also true.
More specifically, one of the most important condition in KKT conditions is
which is called KKT dual complementarity condition. This implies that if , then (i.e. The inequality constraints holds with equality rather than with inequality)
💡
This condition helps SVM has only a small number of
support vectors
Revisit the optimal margin classifier
As I mentioned, the final optimization problem we want to solve is
We can write the constraints as
Therefore, by KKT dual complementary conditions, only for the training examples that have functional margin exactly equal to 1.
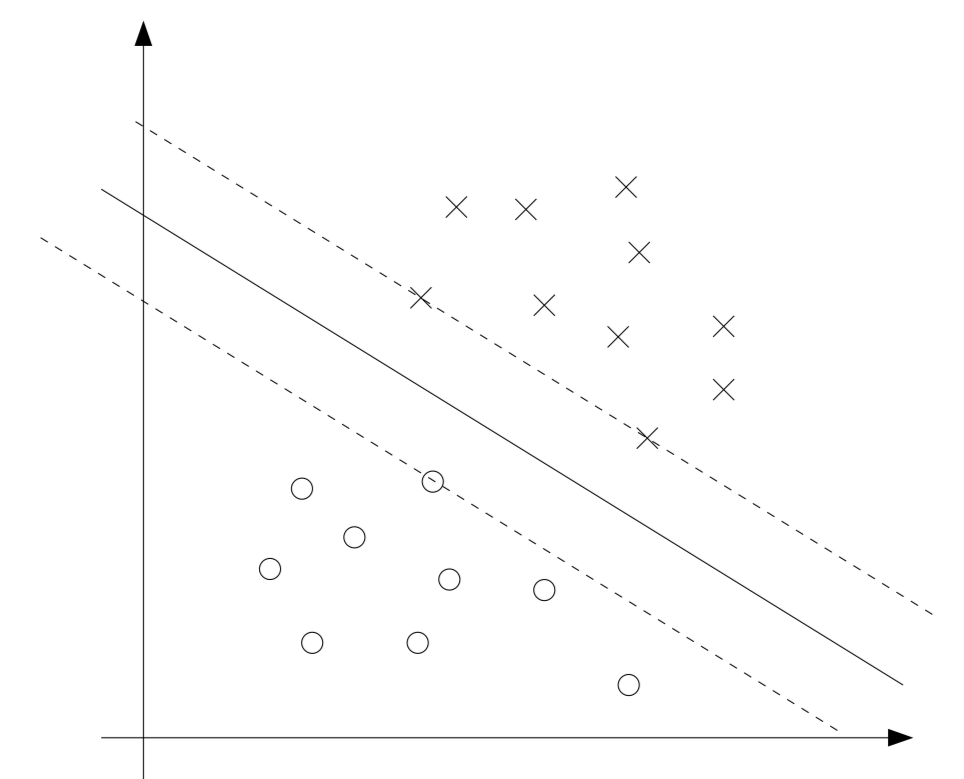
The points with the smallest margins are the exactly the ones closest to the decision boundary. Thus, only three of the ’s that corresponds to the three training example which has the smallest margins have non-zero at the optimal solution. These three points are called the support veectors
💡
The fact is that the number of support vectors can be much smaller than the size of the training set. (So, it is computationally efficient)
When we construct the Lagrangian for our optimization problem we have:
Let’s find the dual form of the problem. To do so, we need to first minimize with respect to and , to get .
This implies that
By using these equations, we can reformulate the original Lagrangian as follows
Therefore, we obtain the following dual optimization problem :
💡
The original optimization problem satisfy KKT condition because and are convex function and is feasible for all . So, we can solve the original optimization via the dual optimization problem.
💡
Dual optimization has inner-product term. So by using this term, we can use kernel trick.
After we find , we can easily derive by using . In addition, we can also find by using following fact
Suppose we’ve fit our model’s parameters to a training set, and now wish to make a prediction at a new point input . We would then calculate , and predict iff this quantity is bigger than zero. By using , we can derive
Hence, if we’ve found the ’s, in order to make a prediction, we have to calculate a quantity that depends only on the inner product between and the points in the training set. Moreover, we saw earlier that the ’s will all be zero except for the support vectors . So we really need to find only the inner products between and the support vectors.
💡
By using Dual optimization problem, we can able to write the entire algorithm in terms of only inner products between input feature vectors. By using this fact, we can use kernel so that it can be able to efficiently learn in very high dimensional spaces.
Meaning of Basis function
A basis function is a function used to construct a particular function or set of functions as a linear combination of the basis function. Let is a function which is we wanted to find. We can construct this function as a linear combination of the basis function.
💡
Note : is linearly independent
Since is isomorphic to , we can think
So, we can think that
And we want to take cost function to
when we have data.
We want to find the optimal (i.e. we want to regard this function as a function of
Batch gradient descent
So, gradient descent for is following (Batch gradient descent case)
Stochastic gradient descent
For i in range(1, n):
Conclusion
Using basis functions can help increase the dimensionality of the input space, which can make it easier to find decision boundaries or capture more complex relationships between the inputs and outputs.
Above example shows that input space is d-dimensional, however, output space is L-dimensional.
Kernel Trick
Actually, we can express as a linear combination of which are generated by input values.
💡
Note : We don’t know whether is independent. We just know that basis function is independent.
When we update the value of by using batch gradient descent twice, we can easily find that
Let , we can easily found that could be expressed by just linear combination of .
💡
To do this, we initialize the parameter = 0
Since could be express by linear combination of ,
💡
Actually, we want to find the optimal value of . But can be express by linear combination of with coefficient respectively. So if we find optimal , it is equivalent to find the optimal value of .
So, from now on, we are focusing on finding an optimal value of .
Why we have to do this procedure
- can be
pre-calculatedfor all pairs of i and j.
- In addition, we don’t have to compute explicitly, when we try to calculate
Regularization and the non-separable case
The derivation of the SVM as presented so far assumed that the data is linearly separable.However, we can’t guarantee that it always will be so. In addition, the original SVM approach is very sensitive to outliers.
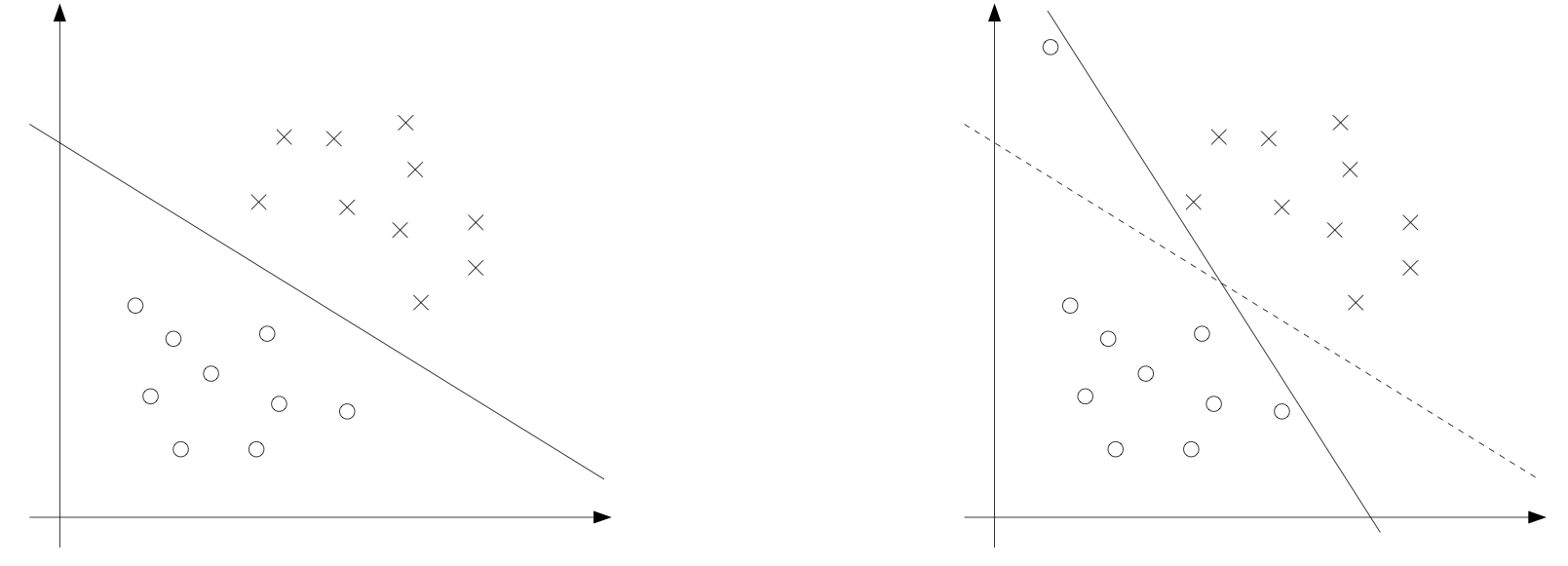
The above figure shows that just one outlier changes the decision boundary dramatically. To make the algorithm work for non-linearly separable datasets as well as be less sensitive to outliers, we reformulate our optimization (using regularization) as follows
💡
By doing so, the formula is permitted to have functional margin less than 1 and if an example has functional margin , we would pay a cost of the objective function being increased by .
As before, we can form the Lagrangian:
After we calculate the dual form, we can derive
반응형
Contents
소중한 공감 감사합니다