Computer Science/Database
7. Indexes and Transactions
- -
728x90
반응형
Index
Motivation

MySQL database, 10,000,000 people
- How long does it take to find name and phone number for person with ID 4,857,845?
- How long does it take to find the phone number for all people named Kristin Elvik?
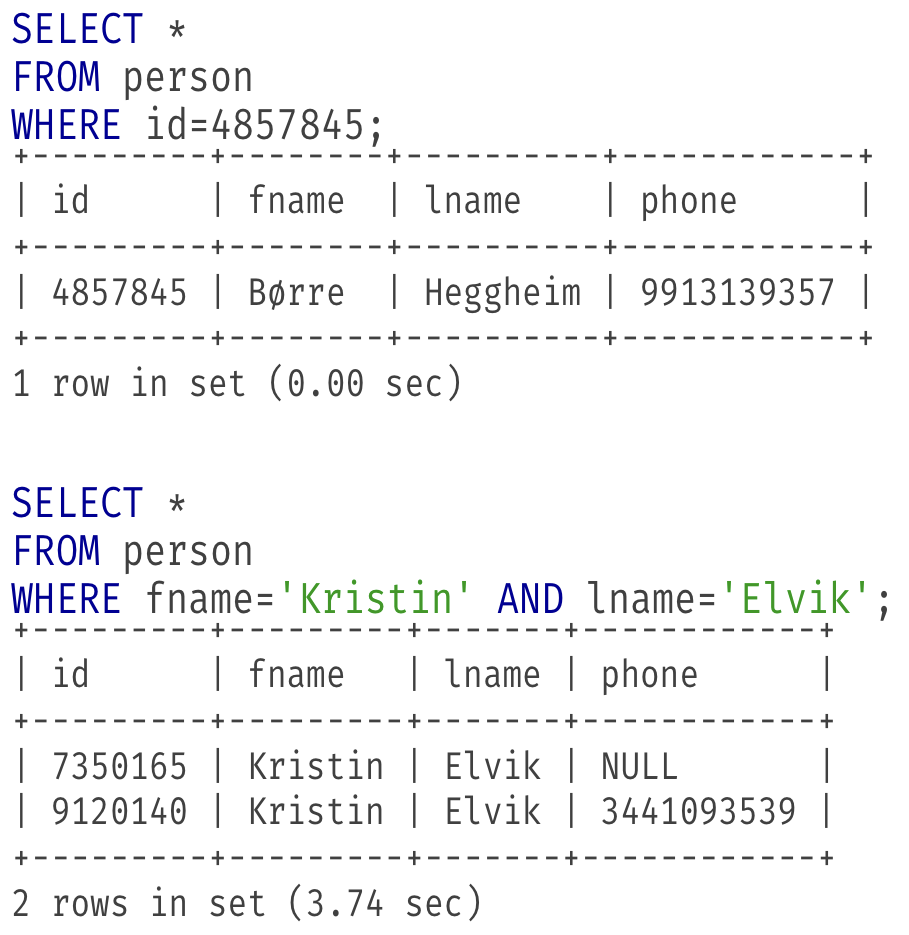
The result of the second experiment is very slow. Why is it slow and what can we do about it?
Explanation
The slow query from the experiment performs a full table scan each row in the table is read and checked if it meets the condition
Index
Index is a persistent data structure which can be used to quickly locate rows in a table based on the values of one or several given attributes.
Cost of an Index
- extra storage space (usually not a problem)
- Index creation might take time (but it is done only once)
- Index maintenance - index must be updated when the data in the table changes
💡
일종의 레드 블랙 트리나 이진탐색트리 느낌으로 기억해주면 된다. 해당 자료구조도 새로운 자료가 들어옴에 따라서 업데이트를 진행해주어야 한다.
Creating and Dropping Indexes

- Unique index doesn’t allow duplicate values
- Indexes on the primary key attributes are created automatically
→ Some RDBMS (e.g. MySQL) create indexes on the foreign key attributes automatically as well

Different SQL syntax for dropping an index in different RDBMS
Experiment revisited
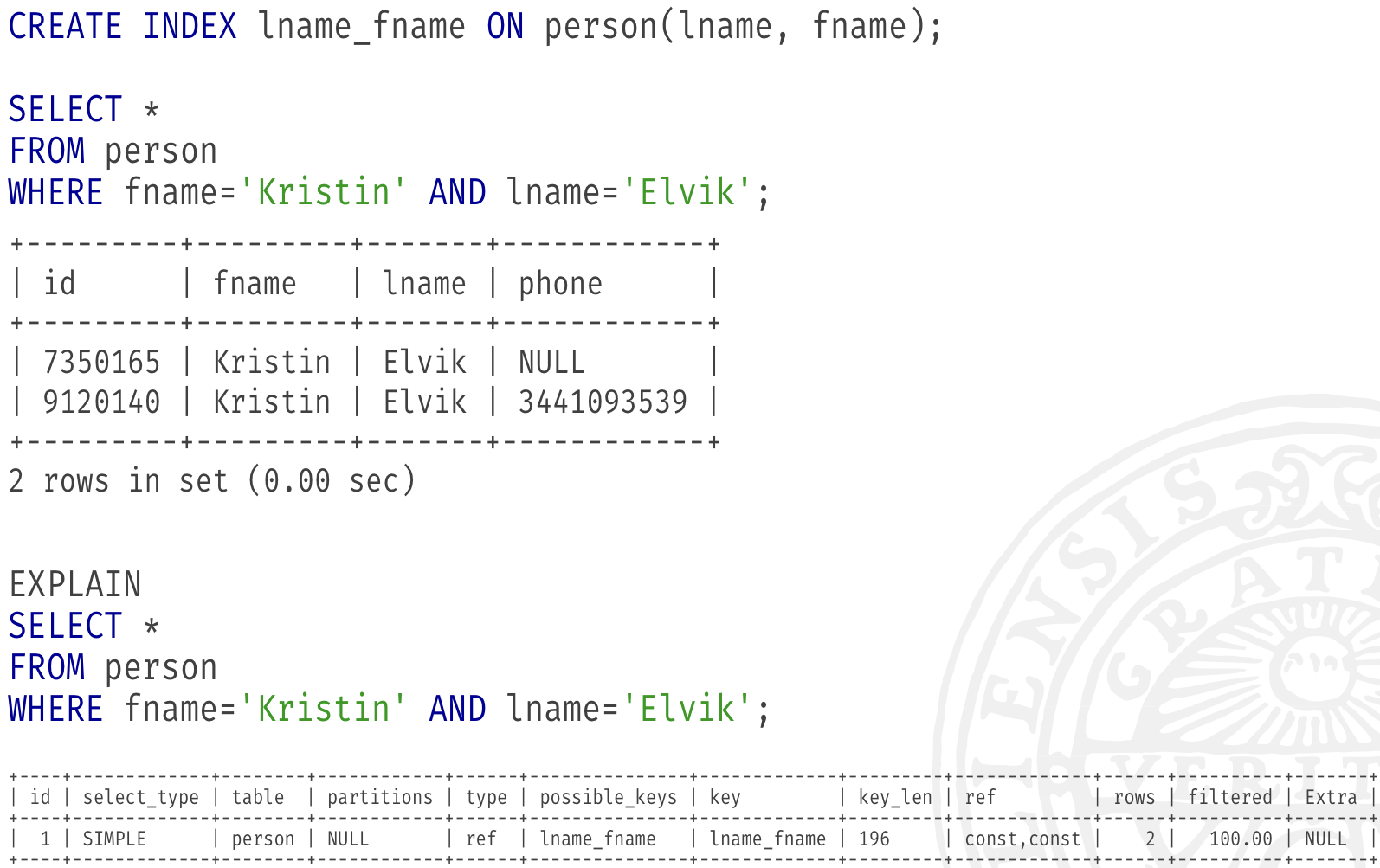
How does an index work?
Two main data structures being used for indexes
- B and B+ trees : useful for conditions with and BETWEEN
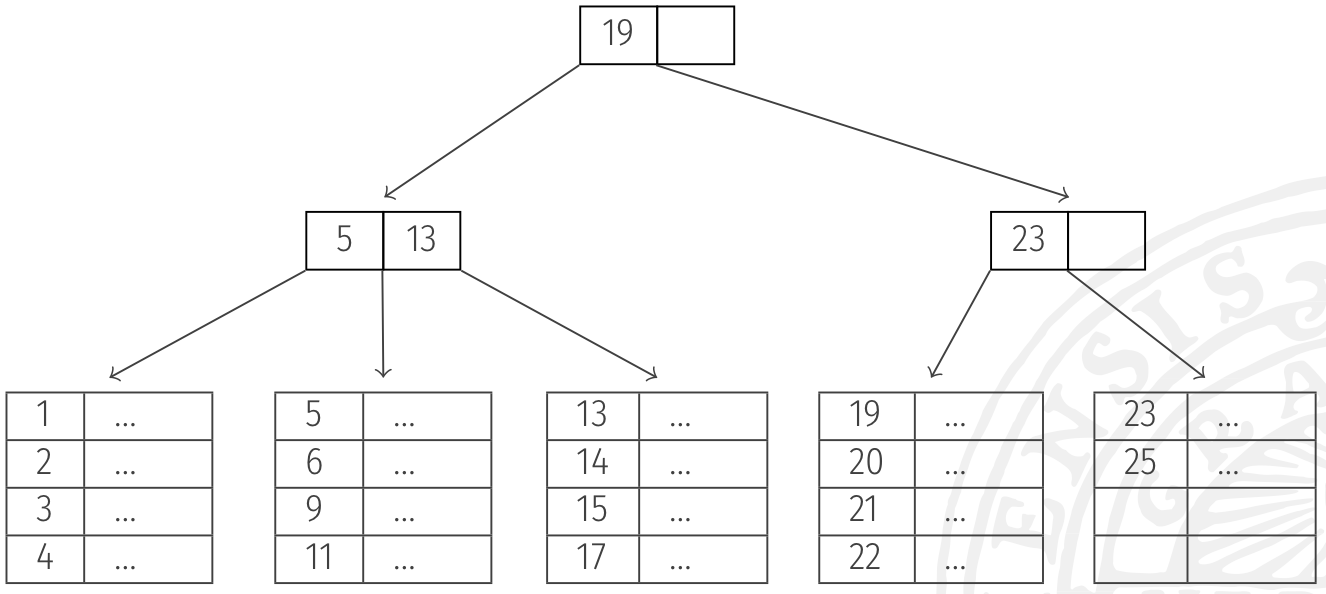
- Hash tables : useful for conditions with only💡잘 생각해보면 Hash는 숫자를 비교하는 용도로는 사용하기에 부적합한 자료구조이다.
Clustered vs Non-clustered Indexes
- Non-clustered index
- Physical order of the rows is not the same as the index order
- Leaf level of the index points to where the data is stored
💡원본 데이터가 존재하는 주소를 저장해 놓는 방식으로 index를 처리하는 것이다. 따라서 여러 개의 non-clustered index를 가질 수 있다.
- Clustered index
- Physical order of the rows is the same as the index order
- Used for indexing of primary keys
- There might only be one clustered index per table
- Fast retrieval of data when multiple rows match the condition
💡Phone book를 생각하면 된다. 원래의 data를 reorganize하는 방식으로 index를 취하는 것이다. 따라서 원본 데이터를 가지고 정렬을 직접 하는 것이므로 clustered index는 반드시 1개만 존재할 수 있다.
Deciding what to Index
- Which queries and insert/update/delete statements will be executed?
- How often?
- What are the time constraints?
- How many rows are in the relevant tables?
💡
즉, 자주 참고하면서 time constraint가 있는 편이고 자료가 많은 경우 index를 사용하면 효율적이라는 것이다.
Quiz 1

Answer : NO
Quiz 2

Answer : 3 & 4
💡
4 is the best answer, but needs deeper indexing knowledge
Other methods of performance optimization
- Denormalization
- Storing derived attributes
- Storing summary statistics
- Vertical partitioning
- Horizontal partitioning
- Hardware tuning
Transaction
Motivation

Think about the following SQL
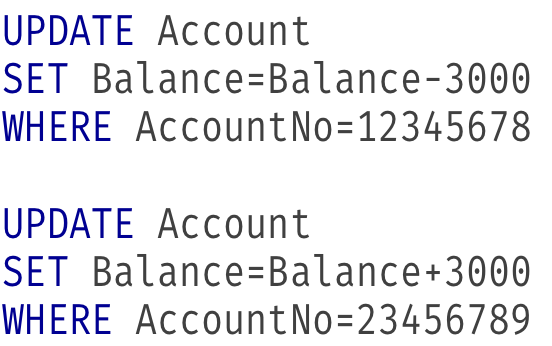
If
- The first SQL gets executed, followed by a software, hardware or network failure
- Both SQLs get executed, but the hardware failure occurs before the changes are permanently stored on a storage device.
Transaction
a series of operations that need to be executed as a single unit of work and that transforms the database from one consistent state to another
Failure (or a user’s decision to abort the transaction) must be treated as if the transaction never happened.
- Commit : making the “effects of the transaction” permanent (successful executing the transaction)
- Rollback : aborting the transaction (because of a failure or user’s decision)
💡
OS에서의 concurrency와 비슷하나 Rollback 기능을 추가적으로 제공한다는 점에서 차이가 있다.
Example
Jan has a subscription from Netflix which withdraws 100 SEK each month from Jan’s checking account.
What can go wrong if this transfer happens to be executed at the same time as the transfer of money to Jan’s savings account?
What are the possible balances at Jan’s checking account after executing both transfers?
One of possible schedules:

💡
즉 본질적으로 Transfer1이 마무리 되기 전에 Transfer2가 read를 해서 발생한 문제이다.
Lost update problem
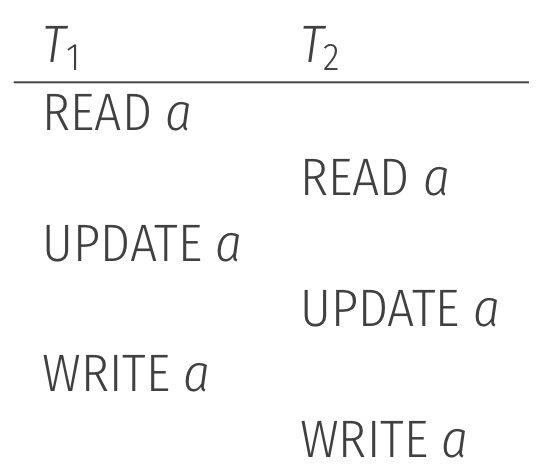
The update of in is lost, is overwritten by which read the state before updating and storing in .
Concurrency
Databases are usually accessed by many clients at the same time.
To avoid problems with concurrent execution, a transaction schedule must be serializable.
→ Execution of concurrent transaction must be equivalent to a serial execution of the transactions.
💡
즉, 동시에 돌려도 각각 순서대로 돌리는 것과 다르지 않은 결과가 나온다는 것을 보장해야한다는 것이다.
ACID
a set of required properties of transactions
- Atomicity : all statements in a transaction are executed or none
- Consistency : all database constraints are satisfied after a transaction is executed
- Isolation : the result of executing concurrent transaction is the same as if the transactions were executed serially
- Durability : once a transaction finishes, effects of the transaction are permanently stored in the database.
Transactions in SQL
- To start a transaction : START TRANSACTION or BEGIN
- To commit the transaction : COMMIT
- To roll back the transaction : ROLLBACK
Example
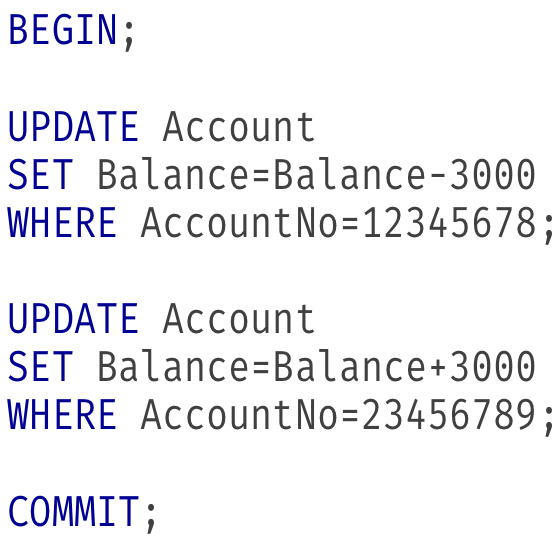
Isolation Levels
The ACID isolation property is often relaxed to reduce the overhead and increase the concurrency.
There are weaker isolation levels that allow some serializability violations in order to achieve higher performance.
Isolation level is set per transaction and it reflects what read phenomena might occur in the current transaction
Read phenomena :
- Dirty reads
- Non-repeatable reads
- Phantom reads
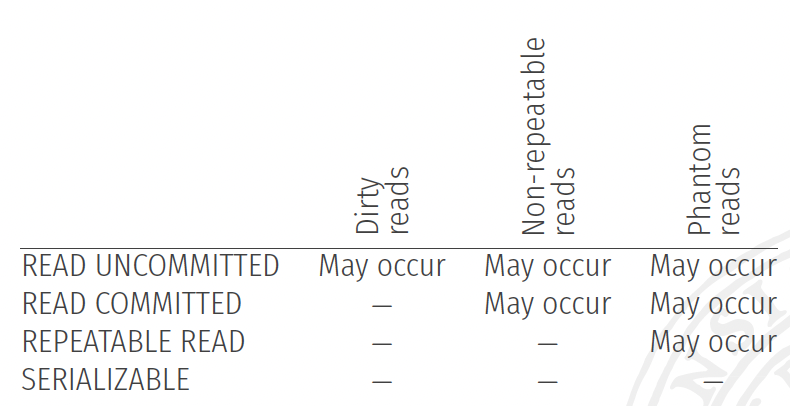
- Default level for InnoDB in MySQL is
REPEATABLE READ
- SQL to change the isolation level
→ SET TRANSACTION ISOLATION LEVEL level, where level is
- SERIALIZABLE
- REPEATABLE READ
- READ COMMITTED
- READ UNCOMMITTED
💡
READ UNCOMMITTED의 경우에는 UNCOMMITTED된 경우에도 READ를 허용하는 것이다. 따라서 Dirty read가 발생할 수 있는 것이다. (나머지의 경우에는 아래에서 설명하는 논리와 크게 다르지 않음)
💡
READ COMMITTED의 경우에는 COMMITTED가 된 경우에만 READ를 허용하는 것이다. 다만, commit이 된 정보를 읽어도 중간에 데이터의 내용이 변동이 생기거나 데이터가 추가로 삽입된 경우에는 문제가 발생할 수 있다.
💡
REPEATABLE READ의 경우에는 반복해서 정보를 읽어도 내용이 바뀌지 않게끔 isolation을 강제하는 것이다. 하지만 새로 데이터가 삽입되는 것까지는 담보하지는 못한다.
Dirty reads

Non-repeatable read

💡
한 작업에서 여러번의 동일 데이터 조회가 있을 때, 그 결과가 다른 것을 말한다
phantom read

💡
여러번에 데이터 조회가 있을 때, 없던 데이터가 생기는 경우를 말한다
Quiz 1

Answer : 1
Quiz 2

Answer : 1, 2
Phantom read에 의해서 1, 2가 발생할 수 있다. 추가적으로 REPEATABLE READ의 경우에는 PHANTOM READ만 가능하므로 데이터가 느는 상황만 가능하다. 따라서 3은 아니다.
마지막으로 격리 수준이 트랜잭션의 중첩된 쿼리의 허용 여부에 영향을 미치지는 않는다. nested query의 사용 가능성은 데이터베이스 시스템의 구성 및 쿼리 구조에 따라 달라지는 것이다.
반응형
Contents
소중한 공감 감사합니다