Computer Science/Operating System
3. Processes
- -
728x90
반응형
What is a Process?
Process의 정의
an instance of a running program
Program과 Process의 차이는 무엇인가?
→ 돌아가고 있는 프로그램 하나의 instance (Active한 개념), 프로그램을 램에 들고와서 cpu가 active하게 하는 대상. 물론 1개의 프로그램이 여러 process가 될 수 있다. (수행중인 프로그램이 process이다.) Program이라는 것은 passive한 개념이다.
Process의 구성요소가 무엇인가?
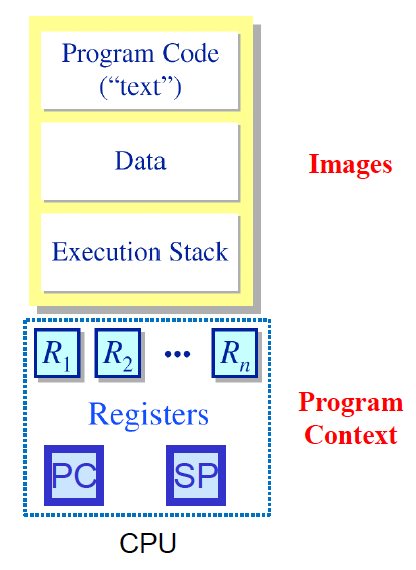
- Image
- Text section
- Data section
- Heap section
memory that is dynamically allocated
- Stack section
temporary data storage when invoking functions
ex ) function parameters, return address, local variable
- Process Context
- Program context
CPU안에 레지스터 : 1word 저장 가능 대략 4byte 저장가능 (PC, stack pointer 등등)
어떤 순간에 프로세스를 수행하기 위해서 레지스터 정보를 가지고 있는데 이를 program context라 부름
- Kernel context
pid, gid, sid, environment등등
- Program context
- Image
Process Layout

OS가 process를 위한 이미지를 만들 때, process의 핵심 component
CPU가 다루는 address는 logical인가 physical인가?
CPU가 다루는 address는 logical address (physical address와 다름) logical address는 architecture에 따라 다름. (32bit machine의 경우 4GB까지 logical memory 컨트롤 가능)
메모리가 많으면 얻는 장점이 무엇인가?
가상 메모리 기법에 의해서 logical memory를 physical memory로 바꿔줌 (실제 physical memory가 많으면 더 빠름. page fault가 덜 나기 때문)
Image의 원소들의 크기는 변하는가?
text와 data section의 경우 크기가 변하지 않고, stack과 heap section의 경우 크기가 유동적으로 변한다.
동일한 프로그램이 여러 프로세스가 될 수 있는가?
Yes!
만약 동일한 프로그램이 여러 프로세스로 취급된다면 data, stack, heap등을 공유하는가?
No! text section은 같겠지만, data, stack, heap section의 경우는 충분히 다를 수 있다.
하나의 Process가 다른 코드의 실행환경으로서 사용될 수 있는가?
Yes! 대표적으로 Java virtual machine(JVM)이 있다. 실행가능한 Java program은 Java virtual machine에서 실행된다. 자바 코드를 컴파일해서 .class 바이트 코드로 만들면 이 코드가 JVM에서 실행된다.
[Java] 자바 가상머신 JVM(Java Virtual Machine) 총정리JVM(Java Virtual Machine)이란? 자바 가상 머신 JVM(Java Virtual Machine)은 자바 프로그램 실행환경을 만들어 주는 소프트웨어입니다. 자바 코드를 컴파일하여 .class 바이트 코드로 만들면 이 코드가 자바 가상 머신 환경에서 실행됩니다. JVM은 자바 실행 환경 JRE(Java Runtime Environment)에 포함되어 있습니다. 현재 사용하는 컴퓨터의 운영체제에 맞는 자바 실행환경 (JRE)가 설치되어 있다면 자바 가상 머신이 설치되어 있다는 뜻입니다. Java는 어떠한 플랫폼에 영향을 받지 않는다. JVM을 사용함으로써 얻는 가장 큰 이점이 무엇일까요? JVM을 사용하면 하나의 바이트 코드(.class)로 모든 플랫폼에서 동작하도록 할 수 있습니다. .cl..https://coding-factory.tistory.com/827

라이브러리는 어디에 저장되는가?
Stack과 heap사이의 공간에 저장됨

Example
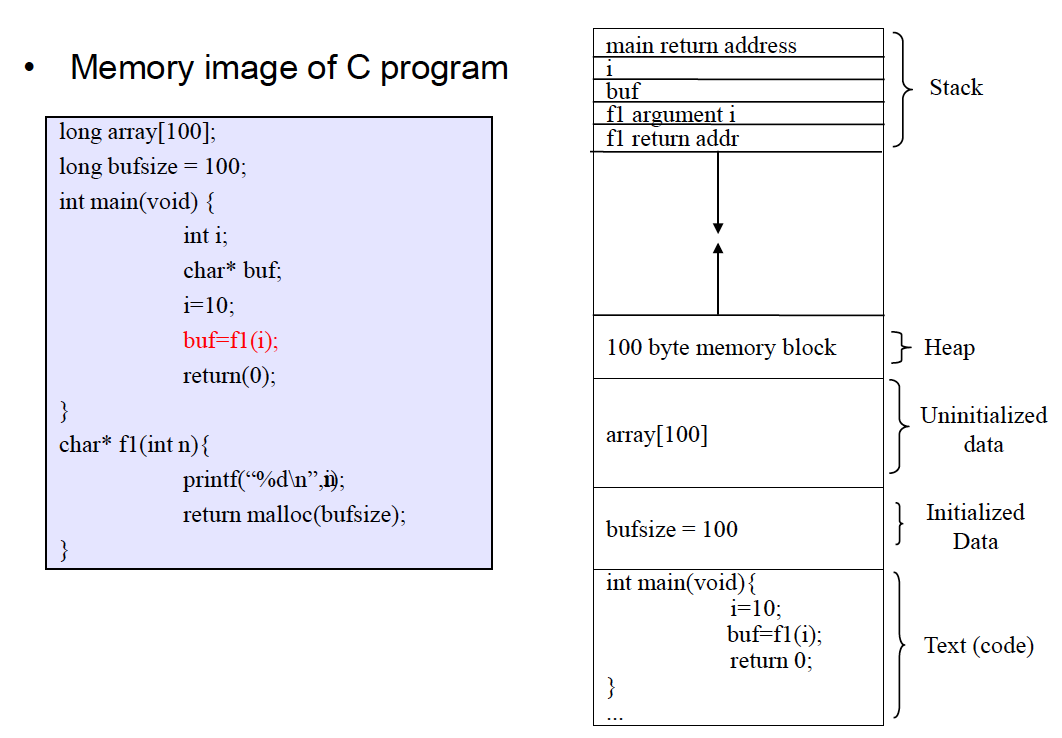
malloc이 system call을 부름 (Dynamic)
실제로는 0101로 들어가 있음
Stack : 아래쪽으로 진행
→ 그러려면 항상 stack의 top을 알아야함 (stack pointer에 해당 값을 저장함)
local variable를 stack에 저장 (Dynamic하게)
- 근데 function을 부를 때 변수를 넘길 때도 선언을 해야함(이것도 stack에 저장)
- 함수가 끝나면 PC가 어떻게 원래 위치로 복귀할 것인가?
→ return할 때 address를 stack에다가 저장해둠.
stack : control flow에 따라 관리하는 영역
전체 메모리 영역을 다 쓸 수 있다고 생각
전역변수를 잡으면 미리 잡아두어야 하는 메모리의 크기가 증가함.
Process Control Structure
운영체제의 경우 여러 process를 동시에 관리함
PCB(Process control block)
커널 코드가 process를 관리하기 위해 필요한 정교한 자료구조
→ 각 process당 1개
PCB의 element는 무엇인가
Image, program context, kernel context
생각해보면 PCB는 해당 process의 image 정보를 알고 있어야함.
struct task_struct : PCB 자료구조
struct mm_struct *mm이 code, data, stack에 대한 시작위치들을 전부 다 담고 있음 (Image에 대한 정보)
struct thread_struct : Program Context를 담고 있음
Kernel context는 어디에 있는가?
나머지 변수들을 kernel context로 생각하면 됨.


new : 프로그램이 process화가 된 것 (PCB가 만들어짐)
ready : ready상태에 있는 process들을 모아두는 것. (ready queue라는 것이 따로 있음)
linked list를 통해 pcb들을 연결해둠 (이런 것들이 개념적으로 ready queue)
→ ready queue에 있는 것들은 언제든지 돌릴 수 있는 상태
(어느 것을 먼저 실행시키는지는 scheduling에 의해서 결정)
running : active하게 돌아가고 있는 process (User mode에서 돌고 있는 것)
만약 특정 process가 read operation을 실행하기를 원하는 경우 system call을 부르고 IO에 명령을 시킴. 하지만, 속도가 굉장히 느리기 때문에 해당 process를 blocked state로 옮김.
→ kernel은 ready queue에서 다음 우선순위 process를 돌림.
💡
모든 system call이 해당 process를 block시키는 것은 아니다. I/O read/write처럼 긴 작업들에 한해서 wait queue로 보내는 것임을 주의해야 한다. + 기본적으로 interrupt는 다 처리하고 원래 돌리던 프로그램으로 돌아온다.
다른 프로그램을 돌리고 있는데 디스크가 interrupt를 줌 (나 작업 끝남) → 하던 작업을 바꾸고 kernel로 mode switching을 함 → 해당 process를 ready queue로 올림

각 IO 장치마다 blocked queue가 존재
각 컨트롤러마다 queue가 존재. 특정 IO에 request가 많은 경우에 block queue에 있는 것
(이것도 마찬가지로 PCB가 연결되어있는 것)
→ 사실 커널이 PCB의 포인터를 업데이트하는 것 (IO쪽에 있는 blocked queue에 PCB를 둘 지, 아니면 ready queue에 둘지 결정)
Q) blocked queue에도 스케줄러가 있는지?
사실 이것도 scheduler가 존재.
ex) 디스크 scheduling
Process scheduling

ready queue에서 무엇을 고를지 (short-term scheduling)
Degree of multiprogramming이 무엇인가
얼마나 많은 프로세스가 현재 메모리에 있는지
→ long term scheduling이랑 관련이 되어있음
Scheduling에는 무엇이 있는가?
Job scheduling (long-term scheduling)
Selects which processes should be brought into the system.
→ Degree of multiprogramming이랑 관련되어 있음.
Medium Term scheduling
현재 돌아가고 있는 process들의 dense가 너무 높음
수상한 것들 그대로 하드디스크로 뻄.
→ 누구를 쫓고 누구를 들여보낼 것인가
이러한 개념을 무엇이라고 하는가?
Swapping
: sometimes it can be advantageous to remove a process from memory and thus reduce the degree of multiprogramming.
Memory → disk : swapped out
disk → memory : swapped in
CPU scheduling (short-term scheduling)
Selects which process should be executed and allocates CPU
→ 일반적으로 이야기하는 scheduling
스케줄링이라고 하는 것이 사실은 포괄적이다.
Process는 크게 2가지로 구분될 수 있다. 무엇인가?
- I/O bound process
one that spends more of its time doing I/O than it spends doing computations
- CPU-bound process
generated I/O requests infrequently, using more of its time doing computations.
- I/O bound process
Process Switching
반드시 mode switching과 구분해야 한다.
프로세스간 스위칭이라는 것은 cpu를 놓고 다른 프로세스가 돌아가는 것. 원래 있는 프로세스가 나가고 새로운 process가 실행되는 것.
ex) time slice가 끝난 경우, IO를 사용하는 경우
사실 mode switching은 자주 일어남. 그 중에 어떤 경우가 돌아오지 못하는 상황 (이런 상황이 Process switching임)
💡
반드시 Mode switch를 하기 전에(kernel mode로 들어오기 전에) 현재 processor의 state를 저장해야 한다. (예를 들어 register value나 flag)
커널 스택은 무엇인가?
일반적으로 프로세스는 user mode stack과 kernel mode stack를 각각 1개씩 가진다. User mode이면 user mode 스택의 top을 가르키다가 kernel mode로 전환이 되면 kernel mode stack의 top을 가르킨다. Kernel mode에서 함수를 호출하게 되면 그 함수의 지역변수는 kernel mode stack에 저장된다. kernel stack은 프로세스 별로 따로 존재한다.
커널 스택이 궁금합니다. | KLDP https://kldp.org/node/73308Difference between context switch and mode switch in LinuxContext 스위칭과 kernel-user 모드스위칭은 다르다. 두가지 경우 모두 현재 레지스터 컨텍스트를 메모리에 저장함과동시에 기존에 저장해놨던 레지스터 컨텍스트를 메모리로부터 복원한다는 점이 동일해서 햇갈리기가 쉬운데, 둘을 잘 구분할 필요가 있다.프로세스 A 가 User 모드에서 작동하다가 시스템콜이나 인터럽트에 의해 커널모드로 진입시에는 유저모드에서의 레지스터 컨텍스트가 프로세스 A 의 커널스택에 저장되고, 커널스택에 저장되어있던 프로세스 A 의 커널모드 레지스터 컨텍스트가 복원된다.프로세스 A 가 Context Switching 을 할때는 이미 프로세스 A 가 반드시 커널모드인 상태이다. 이 경우는 프로세스 A 의 커널모드 레지스터 컨텍스트가 메모리에 저장되면서 다음번 스케줄될 프로세스 B ..
https://kldp.org/node/73308Difference between context switch and mode switch in LinuxContext 스위칭과 kernel-user 모드스위칭은 다르다. 두가지 경우 모두 현재 레지스터 컨텍스트를 메모리에 저장함과동시에 기존에 저장해놨던 레지스터 컨텍스트를 메모리로부터 복원한다는 점이 동일해서 햇갈리기가 쉬운데, 둘을 잘 구분할 필요가 있다.프로세스 A 가 User 모드에서 작동하다가 시스템콜이나 인터럽트에 의해 커널모드로 진입시에는 유저모드에서의 레지스터 컨텍스트가 프로세스 A 의 커널스택에 저장되고, 커널스택에 저장되어있던 프로세스 A 의 커널모드 레지스터 컨텍스트가 복원된다.프로세스 A 가 Context Switching 을 할때는 이미 프로세스 A 가 반드시 커널모드인 상태이다. 이 경우는 프로세스 A 의 커널모드 레지스터 컨텍스트가 메모리에 저장되면서 다음번 스케줄될 프로세스 B ..https://daehee87.tistory.com/473
Linux Kernel Stack에 대한 오해[root@XLRDev ~]# cat /proc/1/maps 00271000-00272000 r-xp 00271000 00:00 0 0052f000-0053f000 r-xp...https://blog.naver.com/lache96/140051813931

mode swtiching을 하고 일부 경우에 다시 못돌아오는 것
이런 경우를 Process swithcing이 발생한다고 하는 것.
사실 생각해보면 mode switching을 할 때 현재 상태들을 저장하지 않으면 안된다. 그래야 restore할 수 있으므로
Q : 해당 정보들을 어디다가 저장을 해둘 것인가?
커널 모드로 진입하면서 user-mode register context를 해당 프로세스의 kernel stack에 저장된다. 사실 해당 정보는 PCB에 저장된다. (PCB 자체가 kernel stack에 저장). 정확히는 레지스터 값들이나 flag 값들을 저장한다. 이 값들은 kernel에서도 건드릴 수 있는 대상이므로 반드시 저장해야 한다.
→ 즉, Mode switching도 overhead가 발생
(Process switching이 mode switching보다 overhead가 더 큼)
Mode switching은 자주 발생하고, Process switching은 간헐적으로 발생.
→ State change에 발생하는 부분때문에 Mode switching에 비해 Process switch가 cost가 더 크다.
Process switching step은 어떻게 되는가?
- 옮기기 전
- Save the program context (register, etc) : kernel mode로 들어오기 전에 했어도 또 해야한다.
- Update the state of the current process
running에서 block/ready/exit으로
- Move the process control block(PCB) to the appropriate queue
- Select another processes to execute (By process scheduling)
- 옮긴 후
- Move its PCB from the appropriate queue
- Update the state of the selected processes to running
- Update necessary memory-management structures (이 과정은 mode switch에서 전혀 요구되지 않음. 그래서 context switch의 overhead가 더 큼)
- Restore the program context of the newly selected process
Case study : Linux
CPU can run either in User Mode or Kernel Mode
system call을 부를 때마다 kernel mode로 이동하는 mode switching이 가능.
exception의 경우(page fault/0 devise error)도 마찬가지고 exception handler를 kernel이 돌리고 다시 돌아옴.

intel의 경우에는 int 0x80를 처리하면 mode switich
Execution of the Operating System
커널이 실제로 어떻게 존재하는가? 커널이 프로세스인가?
2가지 design Approach
- Execution within User Process
현재 대부분의 os가 해당 방식을 따름
- Process-based Operating System (Execution outside user process) : 1번과 완전히 다른 방식
- Execution within User Process
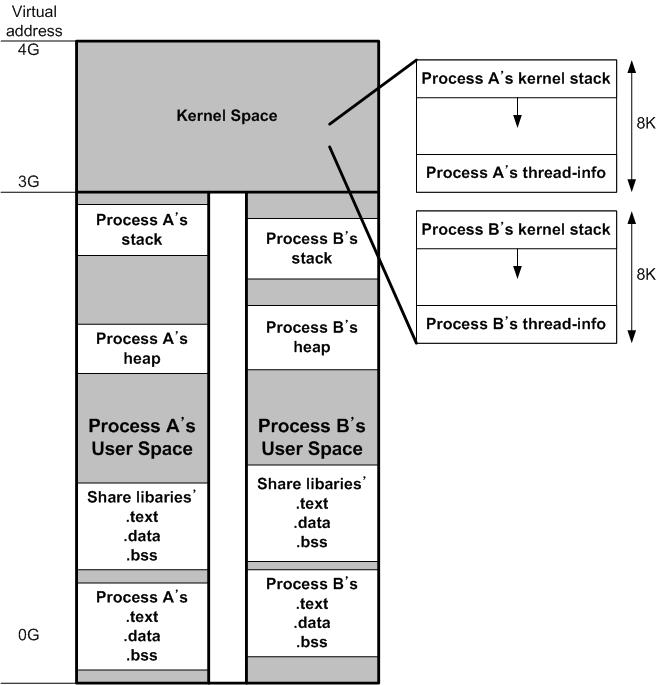
Execution within User process

4GB를 3GB와 1GB로 쪼갬 (Linux의 경우 이렇게 쪼갬)
4GB의 주인은 Process임
근데, 그 중 1GB가 kernel을 위해 할당됨
System call이 오면 kernel address space로 점프함
→ system call handler를 돌리고 user address space로 내려옴
사실 mode switching이 program counter 입장에서 kernel address space와 user address space를 넘는 것.
밖에서 보면 kernel이 보이지 않음.
→ 커널은 process로 존재하는 것이 아니라, user process 안에서 수행되는 것. (The kernel appears to be the part of the user process). 커널은 pid가 존재하지 않음.
각 process는 동일한 커널 코드들이 존재
왜 이렇게 했을까?
장점 : mode switching할 때 속도가 빠름 (사실 엄청나게 interrupt가 많이 들어오므로 이런 장점은 굉장히 큼)
→ 만약 kernel을 process로 잡는 경우, process switching을 엄청나게 해야하는 문제점이 발생. (따라서 따로 관리하는 것이 더 효율적임)
단점 : user가 쓸 수 있는 메모리의 크기가 줄어듦.
PCB도 kernel address space에 존재함.
(Ready queue등도 전부 다 저장하고 있음)
사실 Kernel Address space의 경우 physical memory와 1대1 매핑이 된다. 즉, 동일한 physical memory 영역을 공유하고 있는 상황
kernel address space 상에는 pcb 같은 것들이 전부 다 process마다 공유가 되는 이유가 이 때문이다. (각 process마다 page table 같은 것들도 전부 다 이 공간 안에 저장됨)
Process-based Operating system
Os도 독립적인 process로 간주
→ multi-processor나 multi-computer 환경에서는 유리


Creating a Process : OS View
- Assign a unique process
- Allocate memory for the process
- Image
- PCB 할당
- PCB 초기화 작업 수행
- pid, ppid 기입
- PC와 stack pointer 기입
- ready state로 변경
- 해당 process를 적절한 큐에 넣음
System calls for Processes : Unix
Process와 관련해서 유저가 쓸 수 있는 system call
- fork()
새로운 프로세스를 만듦. parent가 child를 fork
- exec()
하나의 프로세스의 내용을 다른 contents로 replace하는 것.
- wait()
2개의 process간의 동기화를 위한 system call. child가 끝날때까지 기다리게끔 하는 것.
만약 fork를 여러번 한 경우는?
자식 중
1개가 끝나면 이어서 계속 진행함
- exit()
terminates a process
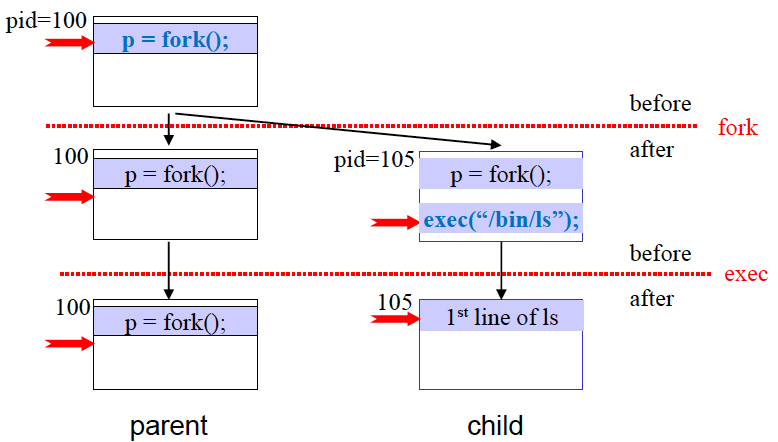
fork() System Call
Unix 계열에서는 새로운 process를 만드는 유일한 방법.
Calling program과 완전히 동일한 copy를 만듦 (일란성 쌍둥이)
→ 단 pid는 다름.
→ data, heap, stack를 복사함. 단, 복사하는 것이지 공유하는 것은 아니다.
- Return value
- Parent : returns child’s pid on success, -1 on failure
- Child : return 0
한 프로세스에서 fork할 수 있는 횟수를 kernel를 컴파일 할 때 조정하기도 함.
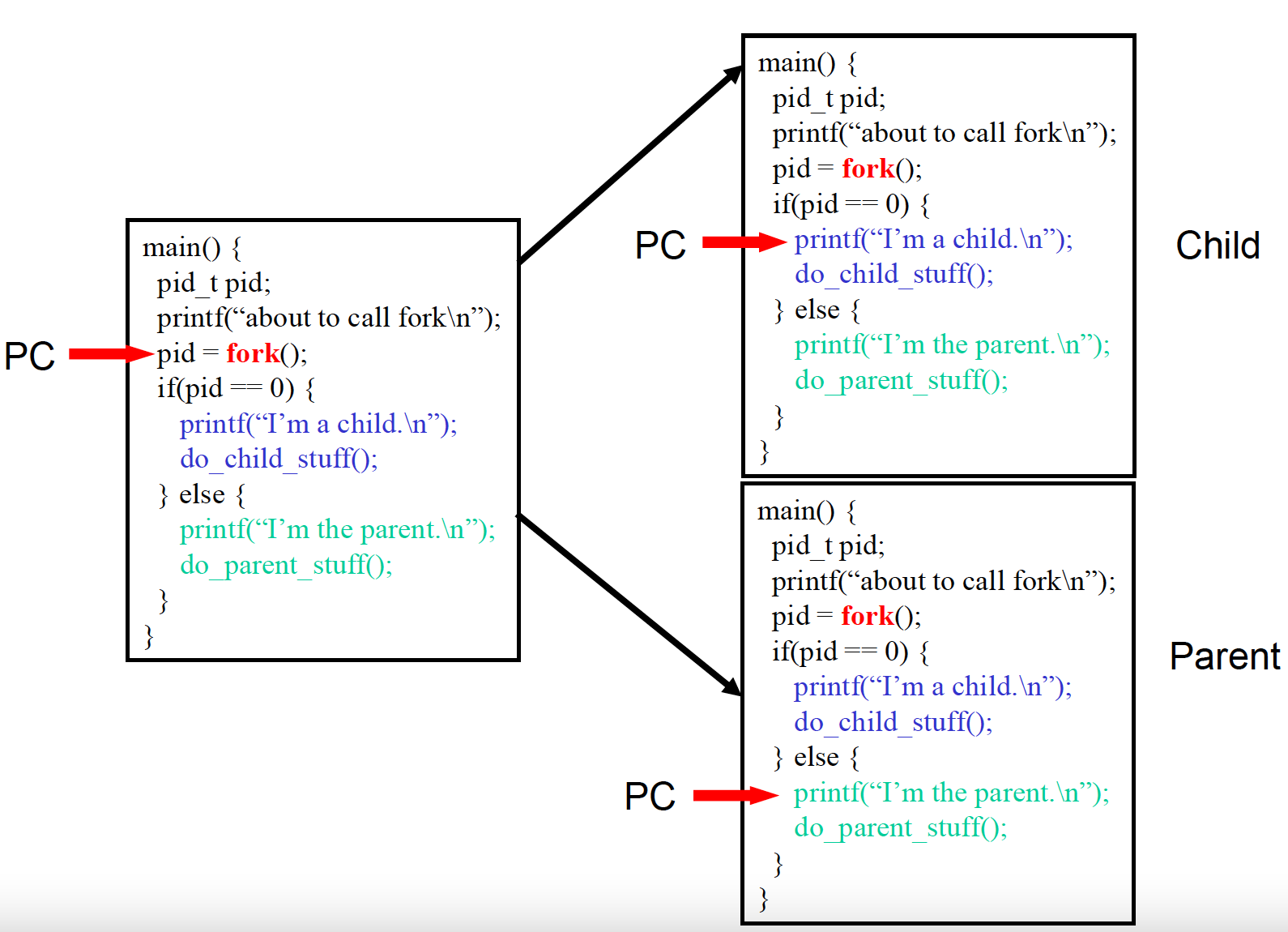
💡
PC값도 그대로 가져오는 상황이므로 child와 parent가 다음으로 실행될 부분은 동일하다. 단, fork()의 return값만 다르다. 이를 이용하여 자식 프로세스와 부모 프로세스의 기능을 분리시킬 수 있다.
exec() System Call
Used to initiate the execution of a new program

parameter의 조합만 다름.

겉모습은 똑같고 내부는 싹 다 바뀜
fork with exec
따라서 완전히 새로운 process를 만들기 위해서는 fork와 exec를 실행함.
Example : Shell

shell은 계속 loop를 돈다.
exit() System call
Normal process termination

유저가 직접 부를수도 있고, main이 끝나서 부를 수도 있음
cleanup processing을 처리하고 I/O stream을 다 닫고 커널로 복귀하는 작업을 수행하게 된다.
kernel로 바로 직접 가고 싶은 경우 : _exit() (이건 정리하지 않고 돌아감)
wait() System call
자식이 끝날 때까지 동작을 멈춤
→ 특정 process가 끝나면, kernel이 부모에게 SIGCHILD 신호를 보내준다. 해당 신호를 받으면 parent가 ready queue로 이동하게 된다.
Cooperating Processes
- 어떤 경우는 2개의 process가 소통해야 할 측면도 존재. (예를 들어 소켓 통신)
- 동기화에 대한 측면 (수행하는 순서를 의도적으로 제한해야할 경우도 존재한다.)
→ 속칭 Process coordination이라고 한다.
2가지의 Approach
- 프로그램 언어에서 이를 제공 (Shared memory)
- OS 차원에서 primitive를 제공 (IPC : inter-process communication)
Producer-Consumer Problem
현실에서는 buffer의 크기가 제한되어 있음. 따라서 속도 차이에 대한 문제가 발생하게 됨.

Interprocess Communication
시스템이 제공하는 기법이다.

동일한 컴퓨터 내에서 다른 2개의 process간의 IPC일수도 있고, 서로 다른 컴퓨터 사이의 IPC일수도 있다.
Basic IPC : Pipe
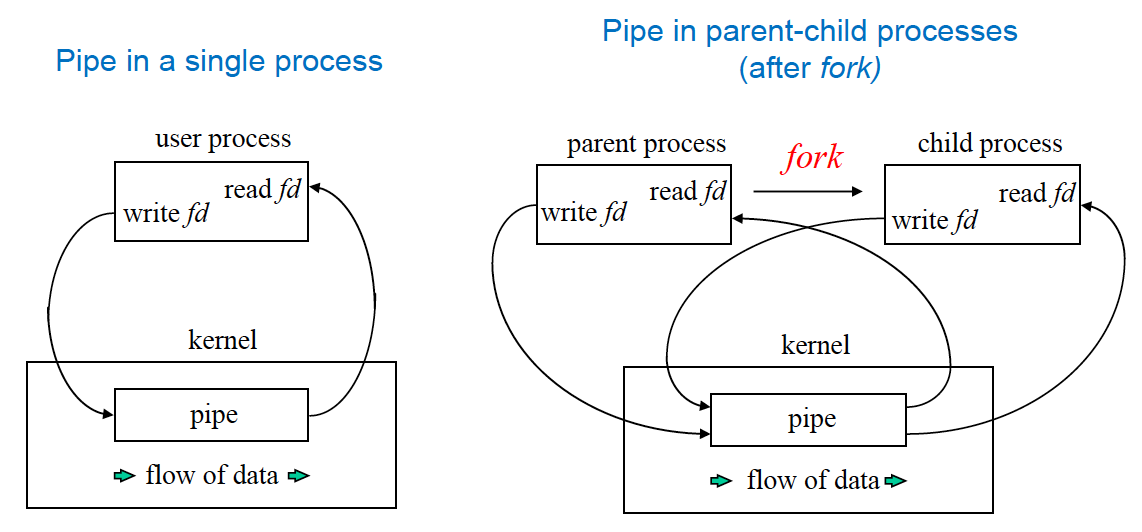
단방향으로 데이터를 주고 받을 수 있게끔.
Problem
- 자식과 부모 사이에만 생성될 수 있음
- 영구적이지 않음
Basic IPC : FIFO (Named Pipe)
무관한 프로세스들끼리도 데이터를 주고받을 수 있게됨
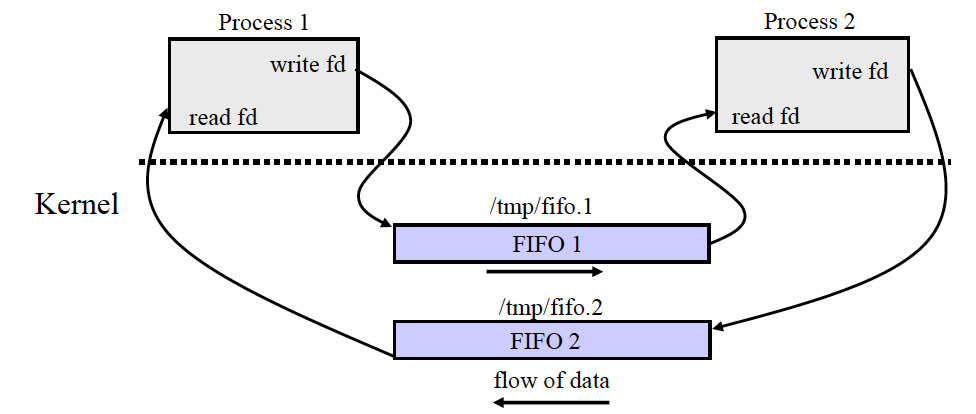
System V IPC
advanced한 IPC 기능들은 IPC facilities 로 설명할 수 있다.
- Message passing
- Shared memory
서로 다른 process에서 데이터를 공유할 수 있게끔
- Semaphores
동기화와 관련한 문제
단, 다른 컴퓨터와의 소통을 하기에는 문제가 있음(한계가 존재)
→ internet base의 IPC의 필요성을 버클리 팀이 느낌
→ 이전까지는 네트워크 개념이 없음
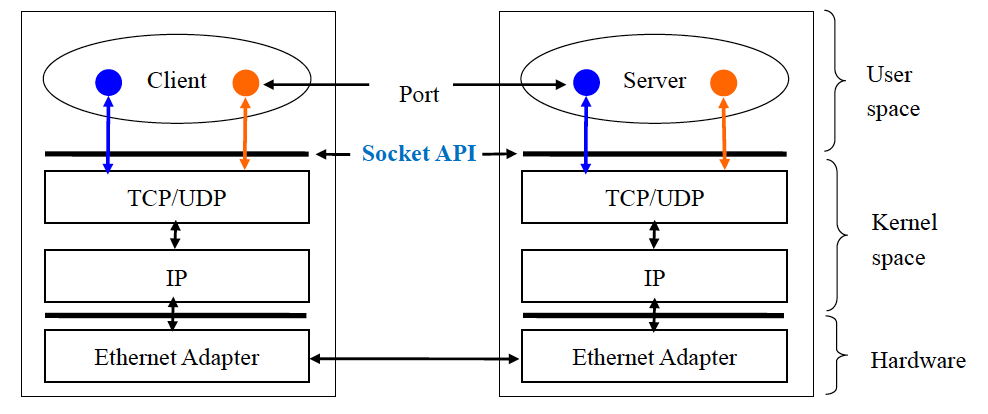
Client-Server IPC using BSD Socket Interface
어떤 process에 대한 통신을 할 적에는 잘 정의된 system call을 통해 가능해야 한다는 것이 목표. 동일한 syntax를 가지고 가능하게끔해야한다는 것이 목표. 그래서 server와 client는 Socket API를 통해서 네트워크 상에서 메세지를 주고받을 수 있게됨

Internet이라는 것이 무엇인가?
Internet Layer위에 TCP와 UDP를 얹은 것. TCP와 UDP를 합쳐서 transport protocol
즉, Internet layer 위에 Transport layer를 어떤 것을 할 것인가가 인터넷
소통을 하기 위해 필요한 2가지 Argument
IP, port number
What is Socket (그래서 소켓이 뭐냐?)

Process는 다른 프로세스로부터 message를 소켓을 통해 받거나 보낸다.
소켓은 port number와 IP주소를 통해서 특정할 수 있다.
IP 주소는 소켓이 위치한 기기나 장치를 식별하고, 포트 번호를 그 기기에서 소켓과 연결된 특정 프로세스를 식별한다.
또한 각 소켓은 전송 프로토콜 속성을 가지고 있고, 대표적으로 TCP또는 UDP를 사용한다.
UDP socket (Connectionless)

잘 보면 연결이 점선이다. 기본적으로 서버가 loop를 돌음. 특정 client가 요청하면 처리해주는 과정을 반복함. (connectionless)
손편지의 과정과 비슷. 사실 받는 사람 입장에서는 보낸 순서대로 도착한다는 보장이 없음. 추가적으로 편지가 없어지는 것처럼 분실될 수 있음. (unreliable delivery)
특정 경우에는 아직도 사용하기는 함. 하지만, 범용적으로 쓰기에는 문제가 많음.
TCP socket (Connection-Oriented)
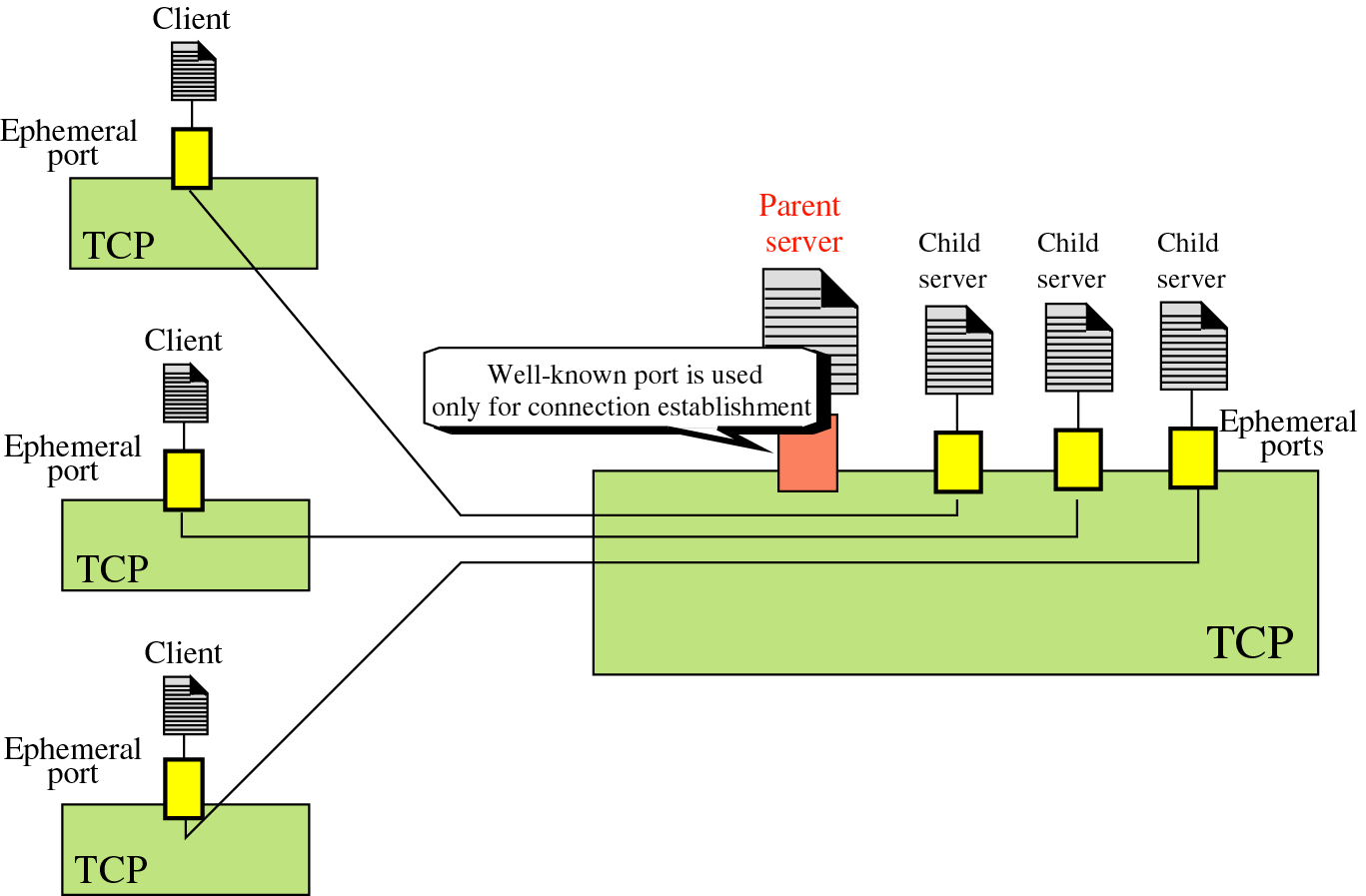
Connection-oriented.
클라이언트 하나당 전담 서버가 별도로 존재한다. 즉 클라이언트가 올 때 마다 fork를 해주는 것. 각 individual process가 해당 기능을 담당.
→ 이 과정에서 overhead가 엄청나게 발생함 (자원 낭비가 심해짐)
→ 대부분 TCP base로 진행됨
→ Reliable하고, In-order가 보장된다. 추가적으로 별도로 존재하는 특성때문에 bidirectional하다.
💡
TCP의 경우 자원의 낭비가 큰 문제점이다. 사용하는 자원은 거의 비슷한데, fork를 통해 여러 프로세스를 만들게 되면 자원을 낭비하게 되기 때문이다. 따라서 이러한 문제를 해결하기 위해서 multi-threading 개념이 도입되게 된다.
반응형
Contents
소중한 공감 감사합니다