Computer Science/Machine learning
13. Dimensionality Reduction
- -
728x90
반응형
Curse of Dimensionality
Datasets are typically high-dimensional
→ 차원이 올라갈수록 영역당 observation이 줄게 된다. 또한, computational cost가 올라가게 된다. 이러한 현상을 curse of dimensionality 라고 한다.

Observed Dimensionality
실제로 data가 놓여있는 공간의 dimension은 그보다 더 작다.

Dimensional Reduction
기존 데이터들의 properties들을 보존하면서 high-dimensional space를 low-dimensional space로 내리고자 하는것
→ It is commonly used for
- feature extraction
- data compression
- data visualization
Linear dimensionality reduction
- Principal component analysis (PCA)
- Factor analysis
Non-linear dimensionality reduction
- Kernel principal component analysis (Kernel PCA)
- T-SNE
Linear Dimensionality Reduction
Data Projection into Subspace

We need to find a new basis of 2D space that can carry most of the information
→ 그렇다면 어떤 기준으로 basis를 정해야하는 것인가?
이에 대한 기준 2가지를 순서대로 살펴보도록 하자.
Criteria 1 : Maximum Variance Formulation
Given a dataset where , the goal is to project the data onto a space having dimensionality while maximizing the variance of the projected data.

첫 번째 기준은 data들의 variance가 가장 크게끔 basis를 설정하는 것이다. 구체적인 상황을 1차원에서 확인하고, 이를 다차원으로 확장시켜보도록 하자.
1-dimensional Principal Subspace
을 에 projection 시키고자 하는 것
The variance of the projected data is given as
이때, S를 Empirical covariance matrix of the data 라고 부른다.
Proof
We are asked to prove that
where is the n-th data point in the dataset, is the mean of the data set, is a vector, and is the covariance matrix of the data set.
To start, expand the square in the left-hand side (LHS) of the equation:
Now, let's work on the right-hand side (RHS) of the equation:
As you can see, the LHS and the RHS are the same, which completes the proof.
💡
왼쪽이 quadratic form이므로 그에 대응되는 self-adjoint인 S가 존재한다. . 또한 는 self-adjoint하므로 Real-digonalizable하다. 또한 covariance matrix이므로 positive semi-definite이다. 즉 S는 non-negative eigenvalue만을 가진다.
PCA can be formulated as
Lagrange multiplier를 적용하면
즉 must be the eigenvector of S having eigenvalue
따라서
💡
Variance를 최대로 하는 PCA는 Empirical covariance matrix의 가장 큰 eigenvalue에 대응되는 eigenvector를 basis로 설정해주면 된다.
M-dimensional Principal Subspace
이를 확장시켜서 basis를 개 잡아보도록 하자.
Let is a basis. PCA can be given as the maximization of total variance
→ 여기서
1차원에서와 동일하게 Lagrange multiplier를 처리하게 되면 다음과 같은 결론을 얻을 수 있다.
💡
Variance를 최대로 하는 PCA는 Empirical covariance matrix의 가장 큰
M개의 eigenvalue에 대응되는 eigenvector를 basis로 설정해주면 된다.Criteria 2 : Minimum Error Formulation
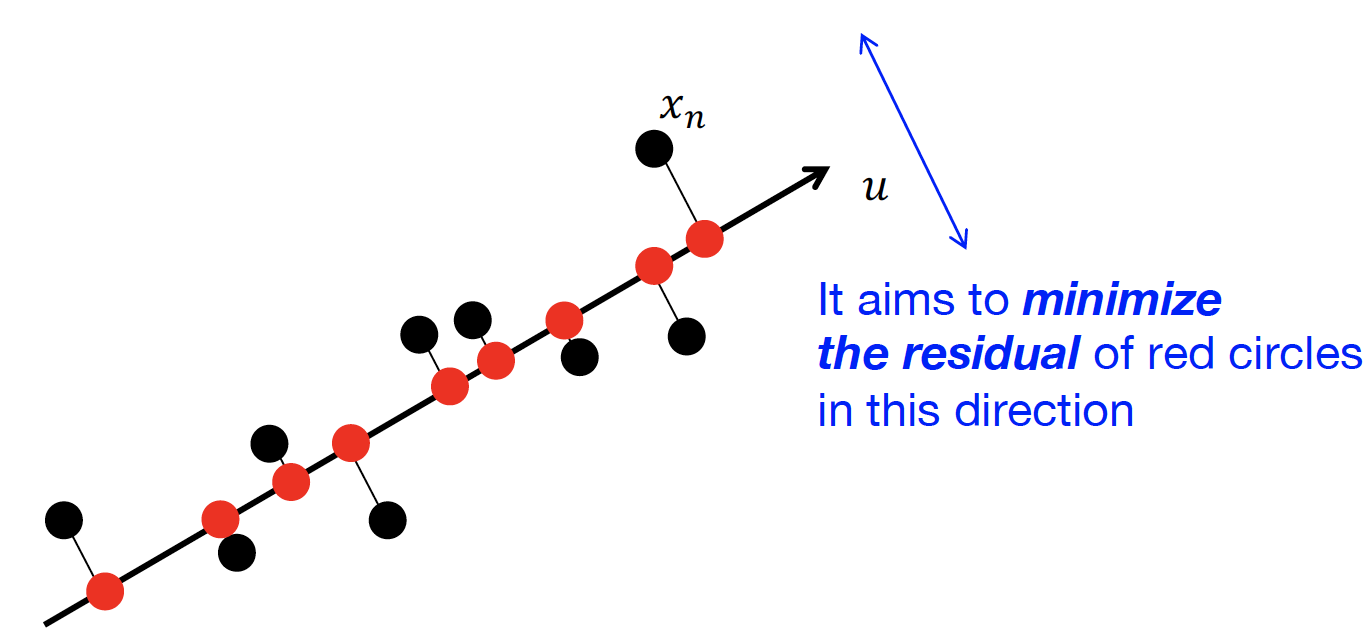
두 번째 기준은 정보의 손실을 최소로 하는 것이다. 즉 다음과 같은 projection error를 최소화하게끔하는 basis를 찾는 것이 목표이다.
→ 즉, projection matrix를 구하고 싶다고 이해해도 무방하다.
💡
결과적으로 m개의 basis를 잡고, m차원의 subspace에 data를 projection시키고 싶다고 생각해주면 된다.
이때 우리는 다음과 같은 orthonormal basis를 잡았다고 가정하자.
(사실 Gram-schimdt를 활용하면 쉽게 orthonormal basis를 잡을 수 있다.)
그리고 일반성을 잃지 않고, 우리가 원하는 subspace의 basis를 이라고 하자.
선형대수적인 지식을 활용하면 를 작게 만들고 싶다는 의미는 결과적으로는 다음과 같이 정리할 수 있다.
그러면 다음과 같은 최적화 문제로 바뀌게 된다.
💡
Error를 최소로 하는 PCA는 Empirical covariance matrix의 가장 작은
D - M개의 eigenvalue에 대응되는 eigenvector를 projection subspace의 basis로 설정해주면 된다.또한, 일반적으로 projection subspace의 basis를 principal component 라고 부른다.
PCA for High-Dimensional Data
일반적으로 dimension 에 비해서 data point의 개수 이 작을 경우 dataset이 high-dimensional라고 부른다.
이때, empirical covariance matrix 의 eigenvalue decomposition을 하려면 결과적으로 의 시간복잡도가 걸린다. (왜냐하면 )
하지만, 잘 생각해보면 차원에 데이터가 개가 있는 상황이므로, 데이터들이 형성할 수 있는 subspace는 기껏해봐야 차원이다. 즉 dataset이 high-dimensional인 경우, 의 eigenvalue가 대부분 0이라는 것을 추측할 수 있다.
이러한 특성을 활용하면 data의 개수에 비해서 차원이 큰 경우에 computational cost를 줄일 수 있다.
💡
는 n번째 행이 인 matrix이다.
💡
이때 S를 sample covariance matrix라고 부른다. 정확하게는 각 차원들끼리의 covariance에 대한 정보를 담고 있는 배열이다.
일단 를 다음과 같이 표현할 수 있고, 이를 활용하면 의 eigenvalue를 구하는 과정을 다음과 같이 표현할 수 있다.
양변에 를 곱해주면 다음과 같다.
즉 의 eigenvector와 eigenvalue를 구하는 문제로 바뀌었다. 이때, 편의를 위해 라고 치환하자
의 eigenvalue와 eigenvector를 구함으로써 를 구했다고 하자. 그렇다면 이거를 활용해서 로 어떻게 복원할 것인가?
위 식에 다시 를 곱해보자
이때, 이므로
따라서
즉 이렇게 하면 시간복잡도를 로 낮출 수 있다. 왜냐하면 결과적으로 이기 때문이다.
Factor Analysis

Factor analysis(FA) 및 probabilistic PCA (PPCA)는 generative model이다. 반면 앞에서 다룬 PCA는 데이터들이 놓여있는 차원보다 단순히 더 낮은 subspace로 projection시킨 것에 불과하다.
예를 들어 위 예시를 보면, 사람이라면 각 cluster에 대해 projection을 다르게 진행해야한다는 점을 판단할 수 있다. 하지만, PCA는 이러한 판단을 할 수 없다. 반면, factor analysis는 data의 distribution을 찾는 generative model이기 때문에 가능하다.
💡
즉, PCA는 단순히 data compression의 역할만 수행할 수 있다.
Revisit Mixture of Gaussian
Mixture of Gaussian의 경우 data가 놓여있는 차원보다 데이터의 수가 많이 작은 경우에 사용하기가 부적합하다.
예를 들어 라고 가정하자. (단순히 1개의 Gaussian이라고 생각하자.)
이에 대한 MLE는 다음과 같을 것이다.
이때, 데이터들이 놓인 차원보다 데이터들의 개수가 더 적다고 가정하면 covariance matrix인 가 singular가 된다.
이렇게 되면 Multivariable Gaussian distribution을 계산하기가 어려워진다.
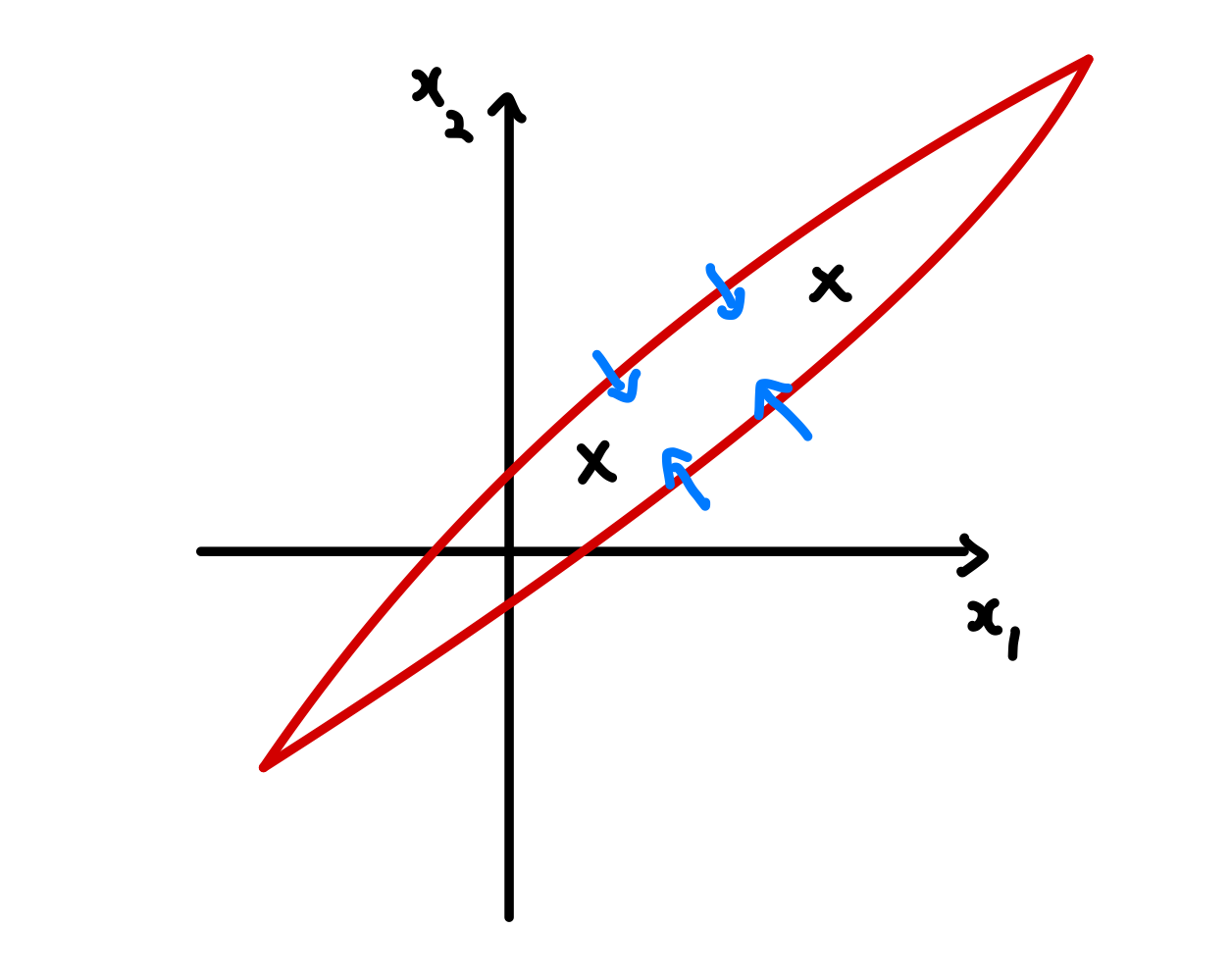
추가적으로 만약 2개의 2차원 상에 존재하는 데이터가 존재하고, Multivari-Gaussian 1개를 통해 데이터들의 분포를 추정하고 싶다고 가정하자. 그러면 Mixture of Gaussian에 의해서 추정되는 Gaussian은 굉장히 flat한 형태의 Gaussian이 될 것이다. 이러한 측면으로 봐도 covariance matrix가 singular가 된다는 것을 확인할 수 있다.
💡
거의 사실상 Gaussian이 직선이 될 것이고, 해당 직선을 살짝만 벗어나도 확률이 0이 될 것이다. 즉 좋은 모델링이 아니다.
만약 여전히 Mixture of gaussian을 쓰고 싶은 경우에는 어떻게 해야할까? 정답은 에 restriction 을 주면 된다.
Option 1 : to be diagonal


위 그림에서 확인할 수 있는 것처럼, covariance가 diagonal로 제한하게 되면 비스듬하게 Gaussian이 형성되지 않게끔 한다. MLE를 통해 covariance를 추정한 결과는 다음과 같다.
하지만, 각 feature가 uncorelated되어 있다는 가정을 하게 되는 꼴이므로 문제가 발생할 수 있다.
Option 2 :
Option 2는 Option 1에 비해서 더 강한 가정을 하고 있다.
이렇게 되면 Gaussian는 Circular 형태를 띄게 된다. MLE를 통해 를 esimate한 결과는 다음과 같다.
💡
사실 covariance의 diagonal들을 평균 취해준 것에 불과하다.
앞서 살펴본 것처럼, option 1 과 option 2는 feature들 사이의 관계를 무시하게 되는 문제점이 존재하게 된다. 이를 해결하기 위해서 등장한 개념이 factor analysis이다.
Definition of Factor analysis
Factor analysis is a statistical method used to describe variability among observed, correlated variables in terms of a potentially lower number of unobserved variables called factors. For example, it is possible that variations in six observed variables mainly reflect the variations in two unobserved (underlying) variables. The observed variables are modeled as linear combinations of the potential factors plus error terms
즉, 결과적으로 latent variable들의 linear combination과 error term들의 합으로 observed data를 표현하고 싶은 것이다.
💡
이러한 측면에서 factor들의 개수(의 dimension)은 실질적으로 가 놓여있는 subspace의 dimension과 관련이 되어있다. 추가적으로 noise를 줌으로써 살짝의 smoothing을 취하고자 하는 것.
Exact procedure
일단 다음과 같이 가정한다.
💡
parameters : (where is
Diagonal) 💡
는 data가 살고 있을 것으로 추정되는 차원과 관련이 되어있다. 즉 는 에 살고 있지만 실질적으로는 dimension이 인 subspace상에 놓여있다고 생각하는 것. 결과적으로 k는 데이터가 놓여있을 것이라고 생각하는 차원만큼 설정하는 hyper-paramter이다.
따라서
💡
가 주어지면 사실상 는 constant이고, 에 의해서 perturbation되는 것으로 이해할 수 있다.
💡
이므로 사실상 latent variable이 k개라고 생각해주면 된다. Mixture of gaussian의 경우는 latent variable이 1개이고, latent variable의 class가 k개라고 가정했다는 것을 주의하도록 하자.
💡
추가적으로 를 diagonal로 잡았기 때문에, data의 feature에 대한 noise가 독립이라고 가정한 것이다.
Example 1
💡
는 latent variable의 차원(실제 data가 살고 있는 차원이랑 관계가 있음), 은 data의 차원, 은 data의 개수
이때
라고 하자. 위 상황을 기하학적으로 나타내면 다음과 같다.
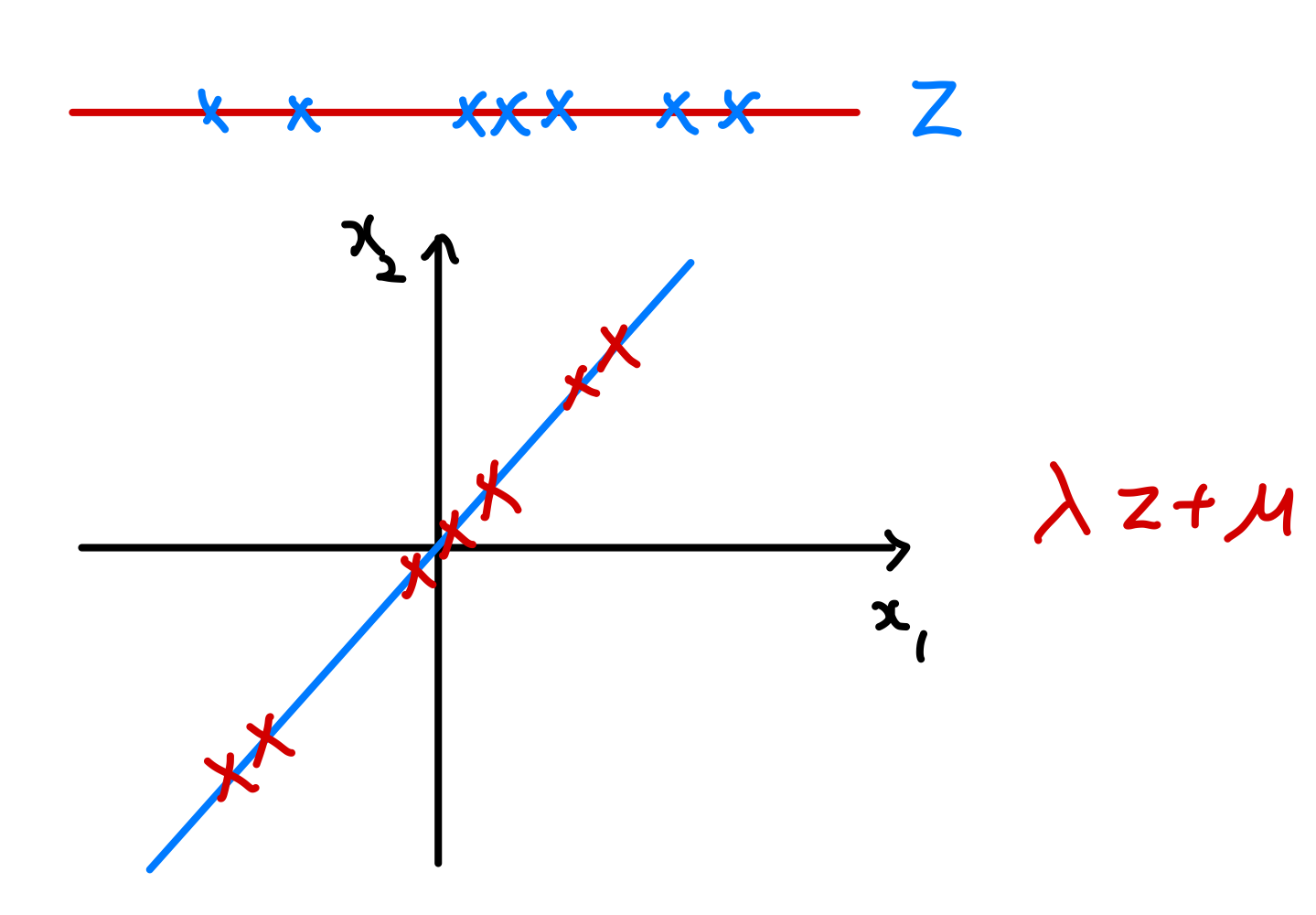
💡
각 data에 대응되는 latent variable의 값이 존재한다고 이해해야 한다. 위 상황에서는 data가 총 7개라고 가정했으므로, z의 값도 7개인 것이다.
추가적으로 가 다음과 같다고 하자.
그러면 error에 대한 distribution은 다음과 같을 것이다.
(이때 가로는 , 세로는 를 의미하게 된다.)

error까지 더해준 결과는 다음과 같다.

이때 분홍색으로 표기한 점이 위의 model로부터 생성된 sample이다.
💡
즉, 실제의 data를 기반으로 를 optimize하고 이를 통해 data의 distribution을 예측한다고 이해하면 된다. 즉, 를 sampling함으로써 를 sampling하는 효과를 가져올 수 있게 된다. (사실상 data의 distribution을 추정하고 있는 작업이다.)
위 상황에서는 data는 2차원 공간안에 살고 있음에도 불구하고, 실질적으로는 굉장히 적은 차원에서 살고 있다. 따라서 그보다 작은 공간으로 projection시키되, 일종의 noise를 살짝 줌으로써 smoothing한 것으로 이해하면 된다.
Example 2
💡
는 latent variable의 차원 (실제 data가 살고 있는 차원이랑 관계가 있음), 은 data의 차원, 은 data의 개수

이를 와 를 활용해서 linear transformation해준 결과를 기하학적으로 나타내면 다음과 같다.

💡
즉 고차원으로 올려준 효과라고 생각해주면 된다.
마지막으로 여기에 noise를 더해주면 다음과 같다.

앞서 2개의 예시에서 살펴본 것처럼, factor-analysis를 사용하면 high-dimensional data를 활용할 수 있게 된다.
Marginals and Conditional of Gaussian Distribution
Suppose where
where and
💡
이때 는 covariance matrix이므로 symmetric하다. 따라서
First, we want to compute the marginal distribution of (i.e ).
By the definition
So we can easily show that
Secondly, we want to compute the conditional distribution of
By the definition
So we can easily show that
💡
특히 conditional distribution 공식은 외우지 말고, 필요할때마다 참고하는 식이면 충분하다.
정확한 증명은 다음 사이트를 참고하면 된다.
Conditional distributions of the multivariate normal distribution
The Book of Statistical Proofs – a centralized, open and collaboratively edited archive of statistical theorems for the computational sciences
 https://statproofbook.github.io/P/mvn-cond.html
https://statproofbook.github.io/P/mvn-cond.htmlEM Algorithm for Factor Analysis
1. Derive
💡
가 gaussian이라고 가정한 것이다.
Since
where
Similarly, we can derive
💡
여기서 는 Sample covariance matrix이다.
Let's calculate one of the elements in the above covariance matrix.
Since, and are not correlated and their expectations are 0,
By doing similar calculations, we can easily find that
Finally, we can derive
💡
이 식을 통해 likelihood 를 구하는 것은 가능하다. 하지만, log-likelihood을 maximize하는 closed-form solution이 존재하지 않는다. 따라서 EM algorithm을 통해 iterative하게 구하고자 하는 것이다.
2. E-step
💡
mixture of Gaussian에서는 가 discrete였지만, 여기서는 continuous random variable이다.
💡
EM algorithm에서 살펴본 것처럼, 를 로 잡음으로써 log-likelihood의 lower-bound를 tight하게 만들 수 있다.
Mixture of Gaussian의 경우에는 를 적당히 summation해서 구할 수 있었다. 하지만 여기서는 가 continuous random variable이기 때문에, 위에서 증명한 conditional distribution of gaussian 공식을 활용해야 한다.
위 내용을 활용해서 를 표현한다.
3. M-step
M-step에서는 를 고정하고 다음 식을 maximize하고 싶은 상황이다.
여기서 하나의 트릭은 적분을 expectation 으로 돌릴 수 있다는 것이다. 즉 위의 식을 다음과 같이 바꿀 수 있다.
💡
나머지 항들은 에 영향을 받지 않으므로 생략한 것이다.
그러면 결과적으로 각 parameter에 대해서 영향을 주는 것은 가 유일하다.
이때
위 식을 각각 에 대해서 미분하고 0이 나오는 값을 찾아주면 된다. (Quadratic function임을 보장할 수 있으므로 미분하고 0인 값만 찾아줘도 된다.)상당히 복잡한 과정이 있지만 결과만 살펴보자면 다음과 같다.
이때
로 설정한다. 즉 가 Diagonal이 되게끔 하는 것이다.
💡
이때, 는 parameter가 바뀜에 따라서 변하지 않으므로 한번만 계산해줘도 무방하다.
정확한 유도는 다음을 참고하도록 하자.
Mixture of Factor Analysis
The assumption is that there are a number of different subpopulations (clusters), each of which is modeled with its own factor analysis model. This model is powerful because it can capture complex structures in the data. The factor analysis part allows it to capture correlations in the data, while the mixture model part allows it to represent multiple different subpopulations. This makes it particularly useful for things like clustering high-dimensional data, dimensionality reduction, and exploratory data analysis.
💡
Mixture of Factor Analysis는 linear combination of different factor analysis model로 생각할 수 있다.
먼저 Factor analysis를 다시 확인해보도록 하자.
즉 결과적으로 의 형태로 표현이 된다는 것을 가정한 것이다.
반면, Mixture of Factor Analysis는 이와 달리 Factor Analysis들의 linear combination으로 가 표현된다고 가정한다
where
💡
Mixture of Factor Analysis는
clustering(Mixture model) 과 dimensionality reduction(Factor analysis)를 동시에 수행하게 된다.
Nonlinear Dimensionality Reduction

만약 데이터가 다음과 같이 manifold상에 존재한다면, 단순한 linear pca만으로는 데이터들의 특성을 반영해주기 어렵다. 이러한 문제를 해결하고자 등장한 개념이 non-linear PCA이다.
하나의 더 예시를 살펴보도록 하자.

A better dimensionality reduction can be done by PCA after mapping of data points to feature space.
💡
The feature space is an
alternative representation of the original data that is obtained through some transformation or feature extraction process. It aims to capture the relevant information or patterns in a more suitable and informative way for analysis or modeling.즉 원래 공간에서 차원 축소가 잘 진행되지 않는 형태의 data distribution을 feature space로 transformation시키면 상대적으로 좋은 형태의 차원 축소를 진행시킬 수도 있다는 것
💡
즉 이전의 방법과 거의 동일하나 original data space에서 PCA를 진행하는 것이 아니라, feature space 상에서 PCA를 진행하려고 하는 것이다.
The objective for Kernel PCA
앞서 SVM with kernel에서 살펴본 것처럼, 계산적으로 cost가 크기 때문에 직접적으로 feature space에서 계산하는 것보다는 kernel function를 통해 계산하고자 하는 것이다.
앞서 PCA에서 했던 작업과 같이 feature space 상에서의 empirical covariance matrix를 구하면 다음과 같다.
💡
결국 covariance matrix의 제일 큰 eigenvalue를 찾는 것이 중요한 문제가 된다.
where : the dimension of feature space
논의의 편의를 위해 평균이 0이라고 가정을 하자. 그러면
💡
정확하게는 평균이 0이 되게끔 조정을 하는 것이다. 일반적인 케이스에 대해서는 뒤에 다루도록 하자.
그러면 m-dimensional principal subspace를 구성하고자 하는 경우에는 objective가 다음과 같다.
즉 의 eigenvalue 중에 가장 큰 m개를 찾는 것이 목표이다.
💡
원하는 크기의 principal subspace의 차원에 의해서, 더해지는 eigenvalue의 개수가 달라지게 된다.
이를 위해서는 일단 의 eigenvector와 eigenvalue를 찾아야 한다. 그런데 식을 잘 관찰해보면 다음과 같은 특성을 확인할 수 있다.
where is a eigenvector of .
즉 다시 말해서 는 들의 linear combination으로 표현할 수 있다는 의미이다.
💡
즉 의 eigenvector들은 들의 linear combination으로 표현할 수 있다
So, there exist some coefficients such that
By using the above equation,
양변에 를 곱한다
where and (Matrix multiplication)
여태까지의 흐름을 요약하면 다음과 같다.
라고 했을 때
를 만족하게끔 하는 들을 찾고 싶은 것이다. 즉 의 eigenvalue들 중 가장 큰 상위 m개를 택해주면되므로, 우리는 S의 eigenvector와 eigenvalue를 찾는 문제로 바뀌게 된다.
앞에서 증명한 것처럼 해당 문제는 결과적으로는 다음 식을 만족하는 와 를 찾는 문제를 푸는 것과 동치가 된다.
💡
즉 feature space에서의 basis들의 coordinate로 변환한 것이다. 는 feature space의 원소로 굉장히 untractable한 반면, 는 coefficient이므로 계산할만하다._
이제 우리는 위 식을 더 정리하려고 한다.
일단, 가 symmetric positive semi-definiteness이다. 즉, 모든 eigenvalue가 non-negative이다. 따라서 는 항상 eigen-decomposable하다. 이때, 의 eigenvector를 이라고 하고, 이에 대응되는 eigenvalue를 이라고 하자. 이때, 는 basis를 이루므로
를 만족하는 이 존재한다. 따라서
따라서
Since are independent
If ,
이때 principal subspace를 구할 때 일반적으로 eigenvalue가 0인 값들에 대해서는 고려하지 않으므로 다음과 같은 식을 푸는 문제로 치환해서 풀 수 있게 된다.
이때 이고 이다. (은 feature space의 dimension으로
따라서 feature space 상에서 바로 eigenvalue decomposition을 수행하는 것보다 훨씬 computational적으로 훨씬 유리하다.
💡
즉, kernel matrix를 활용해서 높은 차원의 eigenvalue decomposition을 상대적으로 낮은 차원의 eigenvalue decomposition 문제로 회귀해서 풀 수 있게 된다.
Normalization in Kernel PCA
사실 정확하게 하려면 를 unit-vector로 잡아야 한다. 왜냐하면
라고 했을 때
결과적으로 우리가 원하는 값이 와 같아지기 때문이다. 따라서 앞의 연산에 추가적으로 가 unit vector라는 constraint를 주어야 한다. 이에 따라 에도 제한이 가해지게 된다.
Therefore,
즉 다음과 같은 를 찾는 작업으로 바뀌게 된다.
Compute Nonlinear Components
여태까지의 내용을 총 정리해보도록 하자. 또한 일반성을 잃지 않기 위해 principal subspace의 차원을 m으로 가정하겠다.
💡
: feature space의 차원, : data space의 차원, : data의 개수
Suppose we have a dataset and this dataset is not easily linearly separable.
We want to increase the dimension by using feature mapping so that this dataset could be easily separable in the feature space. So, our objective is as follows
where
💡
For mathematical simplicity, we suppose that the sample mean is
zeroSince we have some constraints for , we have to apply for Lagrange multipliers.
Differentiate it w.r.t
Therefore
is equivalent to
So, this problem is actually the problem of finding the eigenvalue of .
Since , the computational cost for finding eigenvectors and eigenvalues is very large. We want to reduce the computational cost by using kernel trick
Actually, the problem which we actually want to solve is finding the solution of the following equation
We can convert this equation as follows
This means that can be expressed by the linear combination of . We say
By using this fact, we can convert the problem of to
and multiply each equation (i.e is arbitrary)
where , i, jth component of Kernel matrix
By using some calculations, the above problem could be converted to
In addition, by
Finally, we want to solve this equation
Since and has 1-1 correspondence, if we know one of them, the other one can be easily calculated. In addition, if we find such (i.e. we know the eigenvalue of , we can easily calculate the which we actually want to find. As you expected, since , we can easily find the for not .
So our objective is converted as follows
After we find such , this means that we actually know . In other words, we find the principal directions in the feature space. So how can we project new data into the subspace that we found?
Let’s say the subspace we found to and the new data to .
- We have to convert to (i.e transform data space to feature space)
- Project to the subspace we found
where is a Kernel function
💡
Kernel function을 활용하면 고차원 공간에서 내적을 할 필요가 없이 data space상에서 연산을 수행해주면 되므로 computational 측면에서 그렇게 부담이 크지 않다.
Centering in Feature Space
기존의 Kernel matrix는 다음과 같다.
이때, feature space에 대응되는 값들의 평균을 0으로 만들고 싶은 상황으로 이해해주면 된다.
이를 기반으로 Kernel matrix를 다시 정의해주면 다음과 같다.
Therefore,
왜냐하면 의 i,j 원소는 j번째 열의 평균, 의 i,j 원소는 i번째 행의 평균, 은 전체 평균이기 때문이다.
이때, 이므로 는 의 basis change에 대한 결과로 볼 수 있다. 즉 단순히 기저를 변경함으로써 feature space상의 데이터들의 평균을 원점으로 재조정한 것에 불과하다. 또한 는 이미 eigenvalue decomposable하고 기저 변경에 의해서는 eigenvalue를 바꾸지 않으므로 최종적으로 우리의 objective를 다음과 같이 이해할 수 있다.
💡
여기까지 하면 기존의 평균이 0이라는 가정을 안해도 무방하다.
Isomap

Isomap approximates geodesic distance by using shortest paths in graph
즉 다시 말해서 2개의 data 사이의 metric를 graph 상에서 shortest path로 정의하겠다는 의미이다.
정확하게는 data 사이의 거리가 특정 임계값보다 적으면 edge를 그리고 해당 edge에 가중치를 부여하는 방식으로 그래프를 그린다. 그리고 해당 그래프에서 shortest path 문제를 푸는 것이다.
💡
알고리즘에서 배운 것처럼, shortest path는 metric이 되기 위한 조건을 다 만족한다.
Isomap is a nonlinear dimensionality reduction technique that aims to preserve the global geometric structure of the data. It achieves this by first constructing a neighborhood graph based on pairwise distances between data points and then computing the shortest path distances (geodesic distances) on this graph.
Once the geodesic distances are computed, Isomap creates a new distance matrix that captures the intrinsic relationships between data points in the low-dimensional space. This new distance matrix is constructed by preserving the pairwise distances in the original high-dimensional space, while accounting for the manifold's underlying geometry.
To obtain the low-dimensional representation, Isomap performs eigen-decomposition on the new distance matrix. Eigen-decomposition is a process that decomposes a matrix into its eigenvectors and eigenvalues. In this context, Isomap computes the eigenvectors and eigenvalues of the new distance matrix.
The eigenvectors represent the principal components or basis vectors in the low-dimensional space, and the eigenvalues indicate the importance of each eigenvector in capturing the variance or structure of the data. By selecting a subset of the eigenvectors corresponding to the largest eigenvalues, Isomap obtains the low-dimensional representation of the data.
Autoencoder
앞서 살펴본 것처럼 kernel PCA나 isomap의 경우에는 각 데이터들에 대한 metric을 계산할 필요성이 존재했다. kernel PCA의 경우에는 feature space로 올라감에 따라 계산량이 올라가서 문제였고, isomap의 경우에는 geodesic distance를 구하는 것이 문제가 된다.

→ 따라서 metric을 정의하지 않고 알아서 해줬으면 좋겠다는 측면에서 등장한 개념이 Autoencoder 이다. 즉 data 그 자체로부터 mapping function을 배우게끔 하자는 것이 핵심 아이디어이다.
Encoder는 funciton이며 다음과 같이 정의된다.
즉 다시 말해서 data가 data들의 특성을 반영하고 있는 latent variable 에 대응되는 를 찾고 싶은 것이다.
💡
는 에 대한 정보를 최대한 많이 들고 있어야 한다. 즉 만으로 를 다시 만들어낼 수 있어야 한다.
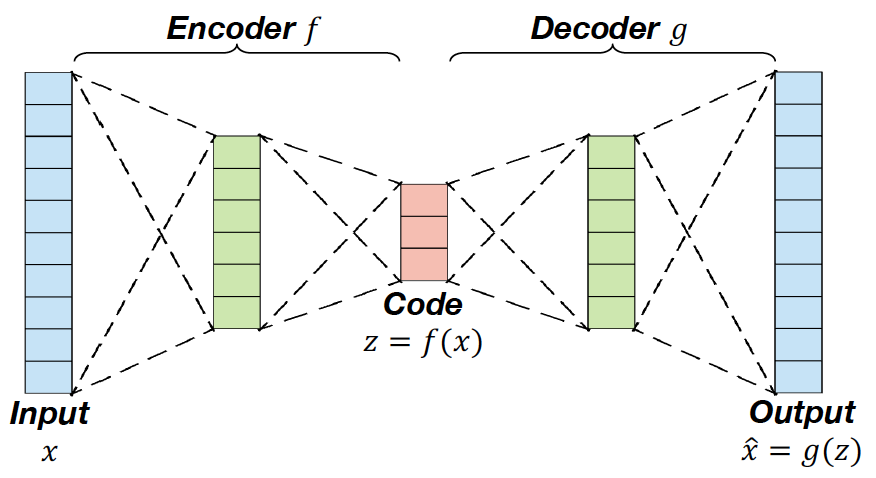
그래서 loss function은 다음과 같이 정의된다.
이때, encoder 와 decoder 는 parametric function이 될 수도 있다. 예를 들어 CNN이나 MLP가 그 예시이다.
💡
즉, Neural network를 통해 최적의 Encoder와 Decoder를 찾아낼 수 있다.

예를 들어 이미지의 경우 에 convolution operation을 에 transposed-convolution operation을 취하는 것을 선택할 수 있다.
t-SNE
앞서 살펴본 것처럼, data compression 목적으로 dimensionality reduction을 수행할 때의 가장 큰 목적은 information preserving 이다. 즉 데이터의 정보 손실을 최소화하면서 차원을 축소하고 싶은 것이다.

하지만 t-SNE같은 visualization을 목적으로 dimensionality reduction을 수행할 때의 가장 큰 목적은 similarity preserving 이다.
💡
즉 차원 축소를 하는 목적에 따라 좋은 차원 축소에 대한 기준이 다를 수 있다.
Suppose we have a dataset , we want to project a dataset to the lower dimension( or ).
이때, t-SNE의 목표는 data space 상에서의 거리(와 projection시킨 space상에서의 거리(가 최대한 유사하게끔 하고 싶은 것이다. 단 data space상에서의 거리를 정의할 때 gaussian distribution을 사용하고 projection시킨 space상에서 거리는 t-distribution을 사용한 것이다.
💡
이때, t-distribution의 degree of freedom은 1로 설정한다.
이때
💡
를 저런식으로 정의하지 않으면 metric의 조건 중 symmetric이 깨진다. 따라서 이를 보완하기 위해서 평균을 취해주는 것이다. 추가적으로 은 joint distribution의 합이 1이 되게끔 하기 위해서 추가적으로 도입한 것이다.
와 의 차이가 작아지게끔 하는 것이 목표이므로
를 최소가 되게끔 gradient descent를 해주면 된다.
반응형
Contents
소중한 공감 감사합니다