Computer Science/Optimization
6. Approximation and fitting
- -
728x90
반응형
Norm approximation
Basic norm approximation problem
Assume that the columns of are independent.
where with , is a norm of
Geometric interpretation
Geometrically, the solution is the point such that that closest to . The vector
is called the residual for the problem; its components are sometimes called the individual residuals associated with .
Estimation interpretation
It can be interpreted as a problem of estimating a parameter vector based on an imperfect linear vector measurement. We consider a linear measurement model
where is a vector measurement, is a vector of parameters to be estimated, and is some unknown measurement error, presumed to be small in the norm . The estimation problem is to make a sensible guess as to what is for given .
If we guess that has the value , the most plausible guess for is
Example
- least squares approximation ()
The most common norm approximation problem involves the Euclidean or -norm. By squaring the objective, we obtain an equivalent problem which is called the least-squares approximation problem
where the objective is the sum of squares of the residuals. It can be solvable by normal equations
If has a full rank (i.e. the rows of are independent), the least-squares approximation problem has a unique solution
- Chebyshev approximation ()
When the -norm is used, the norm approximation problem
is called the
Chebyshev approximation problemorminimax approximation problemsince we are to minimize the maximum absolute value of residuals. The Chebyshev approximation problem can be solved as an LPsubject to
with variables and
- Sum of absolute residuals approximation ()
When the -norm is used, the norm approximation problem
is called the
sum of absolute residuals approximation problem, or in the context of estimation, it is called arobust estimator. Like the Chebyshev approximation problem, this problem can be expressed as an LPsubject to
with variables and
Penalty function approximation
In -norm approximation, for , the objective is
As in least-squares problems, we can consider the equivalent problem with objective
which is a separable and symmetric function of the residuals. In particular, the objective only depends on the amplitude distribution of the residuals (i.e. the residuals in sorted order)
We will consider a useful generalization of the -norm approximation problem that only depends on the amplitude distribution of the residuals.
The penalty function approximation problem has the form
subject to
where is called the residual penalty function.
💡
We assume that is convex, so the penalty function approximation problem is a convex optimization problem.
💡
By choosing , is determined. Moreover, the feasible set of is an affine set.
💡
By using penalty functions, we can give more weight to a specific component.
💡
We can view the penalty function approximation problem as a multi-criterion optimization problem.
Examples
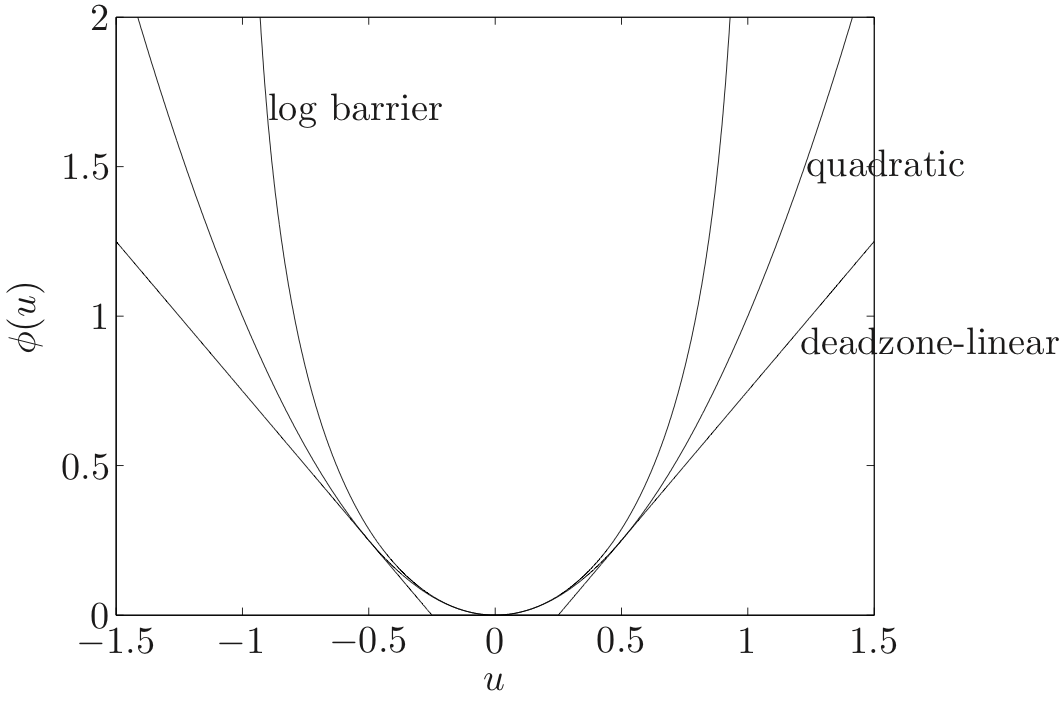
- quadratic💡It is the most typical penalty function because we already know the analytical solution of it.💡Unlike the L1 norm, the penalty function value increases faster as the residual grows larger.
- deadzone linear with width 💡Neglect the residual if its values is less than
- log-barrier with limit 💡It goes to infinity if a residual located in the outside of the limit.💡If the residual is small, the penalty function behaves similarly to a quadratic function. However, if the residual is large, its value will increase much more rapidly than that of a quadratic function.
We take a matrix and vector , and compute the -norm and -norm approximate solutions of , as well as the penalty function approximations with a dead zone linear penalty with and log barrier penalty with . The following figure shows the four associated penalty functions and the amplitude distributions of the optimal residuals for these four penalty approximations.
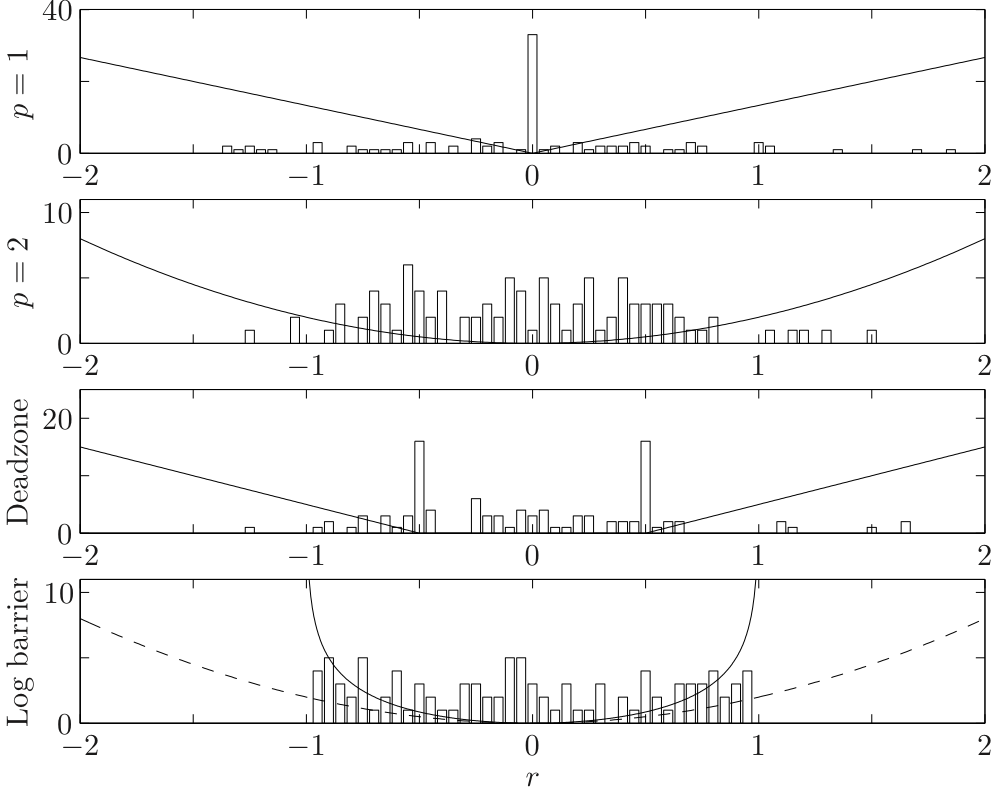
Several features can be derived from the amplitude distributions
- For the -optimal solution, many residuals are either zero or very small. The -optimal solution also has relatively larger residuals than the others.💡Compared to -norm, this converges to zero for relatively small residuals due to the higher penalty imposed when the residuals are small.
- The -norm approximation has many modest residuals, and relatively few larger ones.💡When the residual is small, the value of the penalty value is already small enough so that we can quit the procedure.
- For the dead zone linear penalty, we see that many residuals have the value , right at the edge of the free zone.
- For the log barrier penalty, we see that no residuals have a magnitude larger than 1, but otherwise the residual distribution is similar to the residual distribution for -norm approximation.
Penalty function approximation with sensitivity to outliers
In the estimation or regression context, an outlier is a measurement for which the noise is relatively large. This is often associated with faculty data or a flawed measurement. When outliers occur, any estimate of will be associated with a residual vector with some large components.
Ideally, we would like to guess which measurements are outliers, and either remove them from the estimation process or greatly lower their weight in forming the estimate. This could be accomplished using penalty function approximation such as
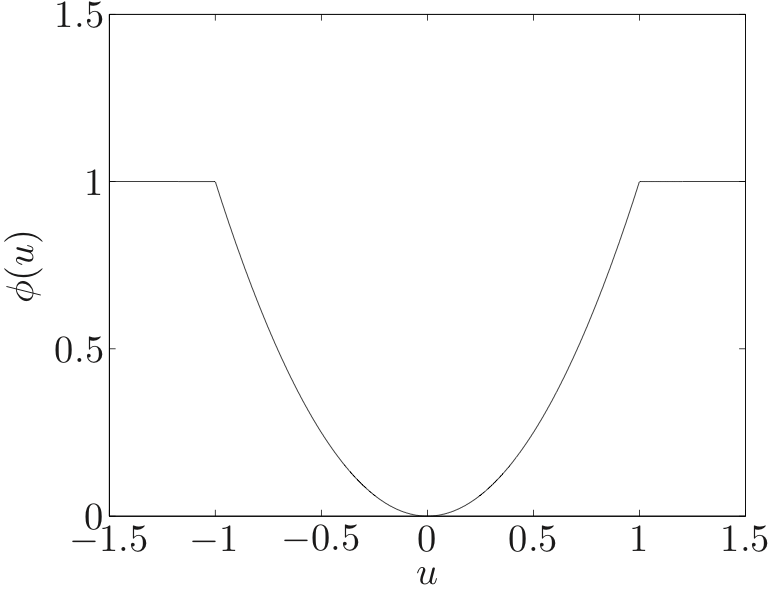
This penalty function agrees with least-squares for any residual smaller than , but puts a fixed weight on any residual larger than , no matter how much larger it is.
💡
By doing so, we can alleviate the impact of the outlier.
The problem is that, like we can see above, it is not a convex function. The sensitivity of a penalty function depends on the value of the penalty function for large residuals. If we restrict ourselves to convex penalty functions, the ones that are least sensitive are those for which grows linearly (like -norm).
💡
Penalty functions with this property are sometimes called
robust, since the associated penalty function approximation methods are much less sensitive to outliers than least-squares.One obvious example of a robust penalty function is . Another example is the robust least-squares or Huber penalty function given by
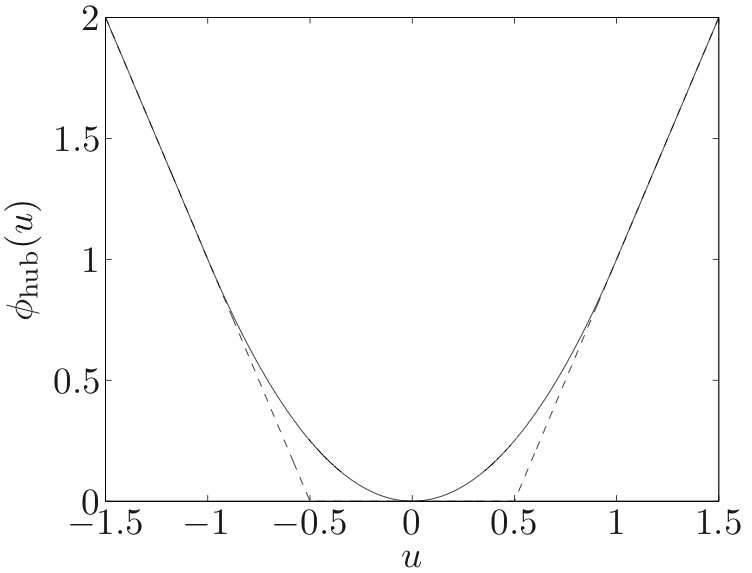
💡
Actually, is a tangent line of the quadratic function at and
💡
It can be interpreted as a mixture of -norm and -norm.
💡
Since -norm approximation is among the convex penalty function approximation methods that are most robust to outliers. So it is sometimes called
robust estimation or robust regressionLeast norm problems
The basic least-norm problem has the form
subject to
where the data are with and , the variable is , and is a norm on . Assume that the rows of are independent.
💡
The least-norm problem is a convex optimization problem
- Geometric interpretation
is a point in affine set with minimum distance to 0
- Estimation interpretation
are perfect measurement of . is the smallest estimate consistent with measurements.
💡Assume we don’t have enough measurement to identify a parameter perfectly (the nullity is not zero), but measurements are perfect.
Example
- Least-squares solution of linear equations ()
By squaring the objective we obtain the equivalent problem
subject to
Like the least-squares approximation problem, this problem can be solved analytically. By introducing the dual variable , the optimality conditions are
Then
💡Since , the matrix is invertible
- Sparse solutions via least -norm
-norm approximation gives relatively large weight to small residuals so that it produces a solution with a large number of components equal to zero.
💡-norm problem tens to producesparsesolutions of
- Least penalty problem
subject to
where is a convex penalty function.
Regularized approximation
The goal is to find a vector that is small, and also makes the residual small. This is naturally described as a convex vector optimization problem with two objectives.
where and norms on and can be different.
💡
We want to find a good approximation with small
Regularization
Regularization is a common scalarization method used to solve the bi-criterion problem. One form of regularization is to minimize the weighted sum of the objectives
where is a problem parameter.
Another common method of regularization is to minimize the weighted sum of squared norms
The most common form of regularization is
It is called Tikhonov regularization. It has the analytical solution
Signal reconstruction
In reconstruction problems, we start with a signal represented by a vector . The coefficients correspond to the value of some function of time, evaluated at evenly spaced points.
💡
It is usually assumed that the signal doesn’t vary too rapidly. (i.e. We have )
The signal is corrupted by an additive noise
The goal is to form an estimate of the original signal , given the corrupted signal . This process is called signal reconstruction.
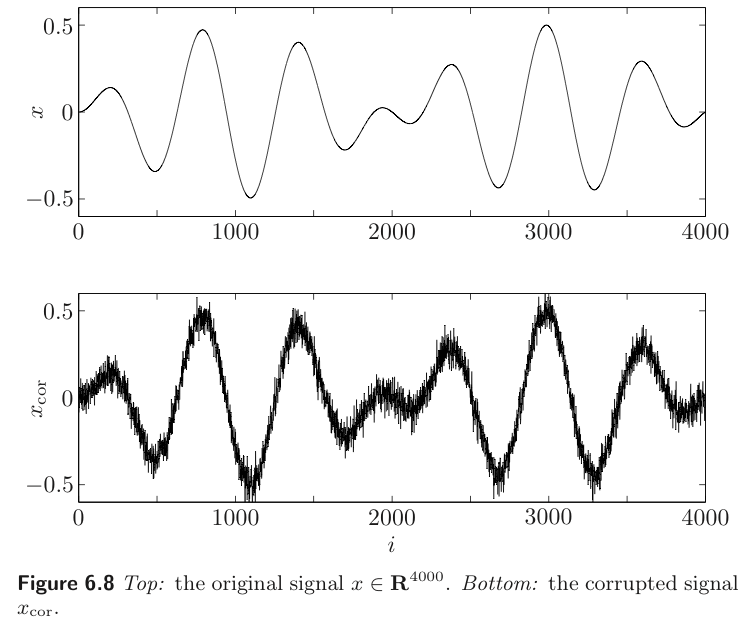
💡
It is related to the denoising process. Moreover, most reconstruction methods end up performing some sort of smoothing operation on to produce , so it is also called
smoothingOne simple formulation of the reconstruction problem is the bi-criterion problem
where is convex, and it is called regularization function or smoothing objective.
💡
It is meant to measure the roughness, or lack or smoothness, of the estimate .
Example : Quadratic smoothing
The simplest reconstruction method uses the quadratic smoothing function
where is the bidiagonal matrix.
We can obtain the optimal trade-off between and by minimizing
where parameters the optimal trade-off curve.
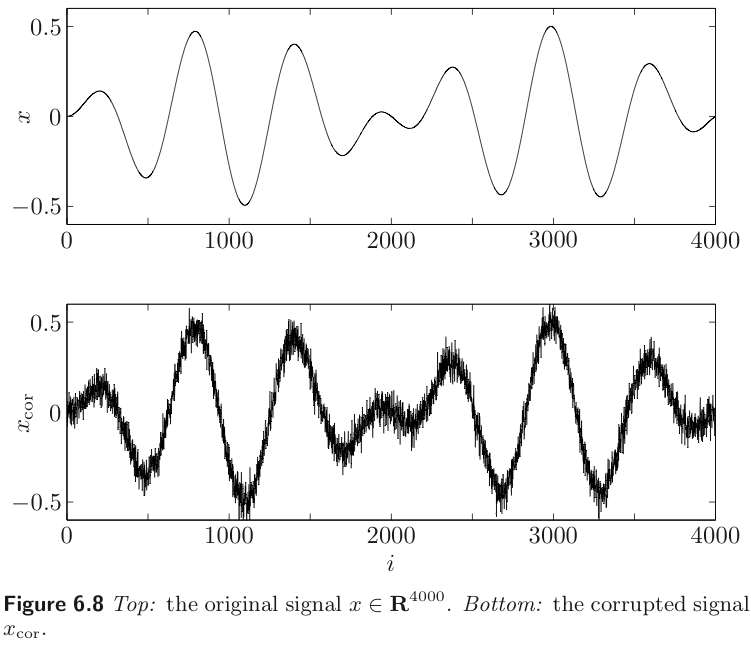
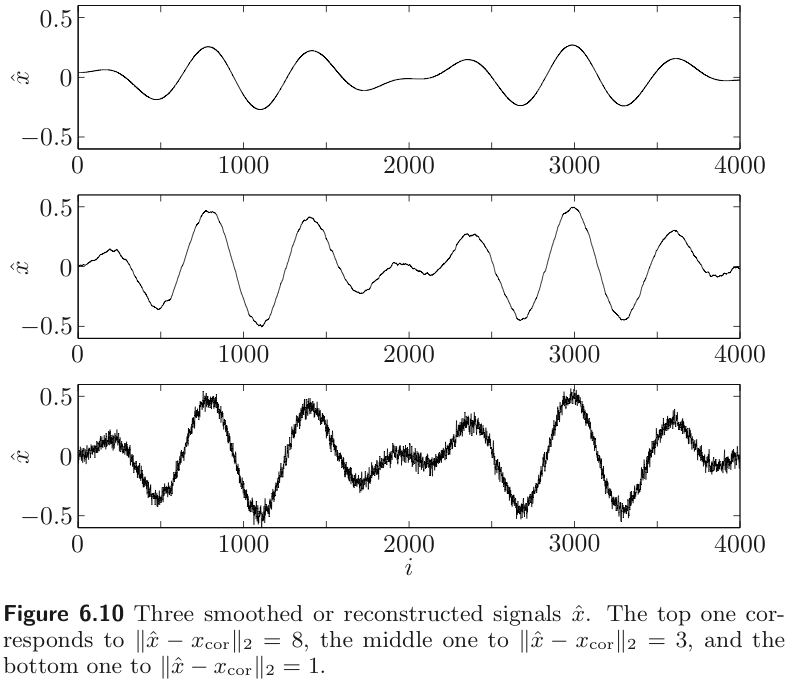
Example : Total variation reconstruction
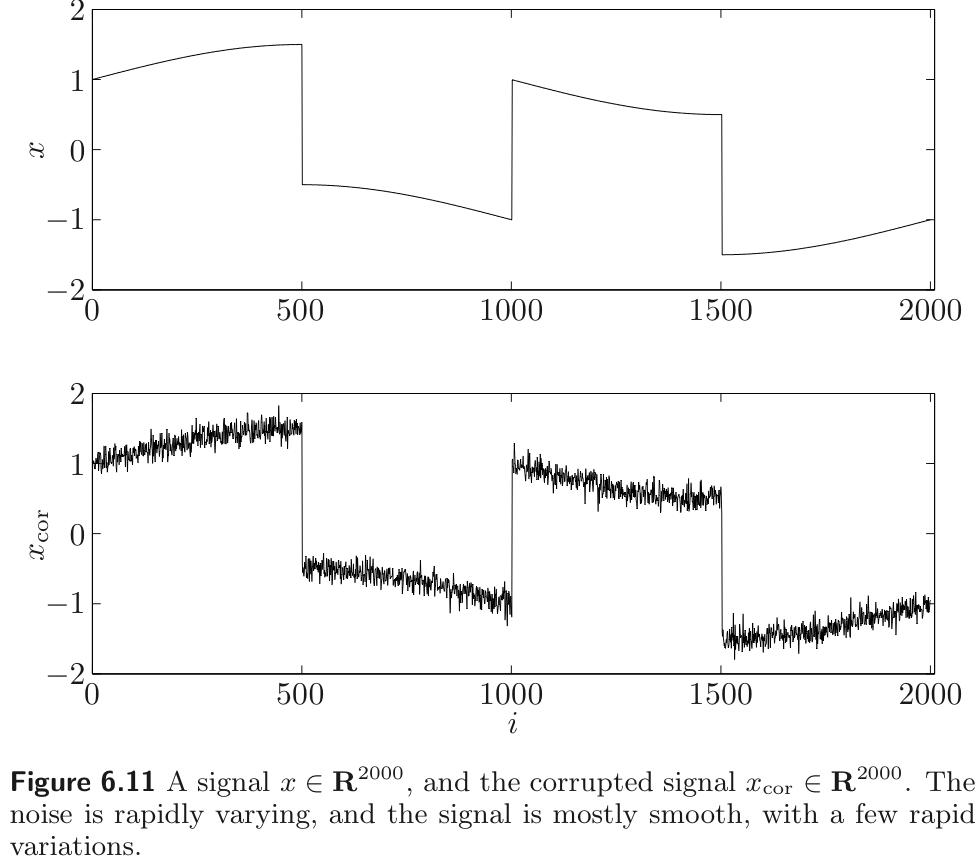
Simple quadratic smoothing works well as a reconstruction method when the original signal is very smooth, and the noise is rapidly varying. But any rapid variations in the original signal will be removed by quadratic smoothing.
Total variation reconstruction method can remove much of the noise, while still preserving rapid variations in the original signal. The method is based on the smoothing funciton
💡
Similar to -norm, it gives less penalty for rapid variation than the quadratic one.
Therefore, we have to choose the smoothing objective carefully regarding of the characteristic of the noise and signal.
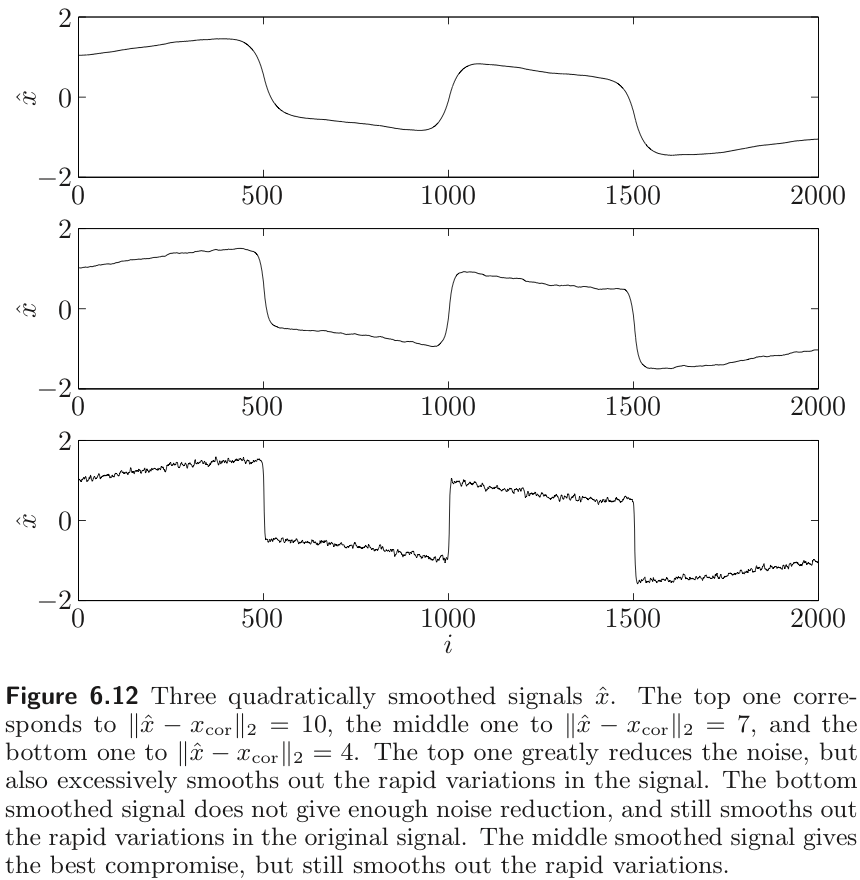
💡
quadratic smoothing smooths out noise and sharp transition signal
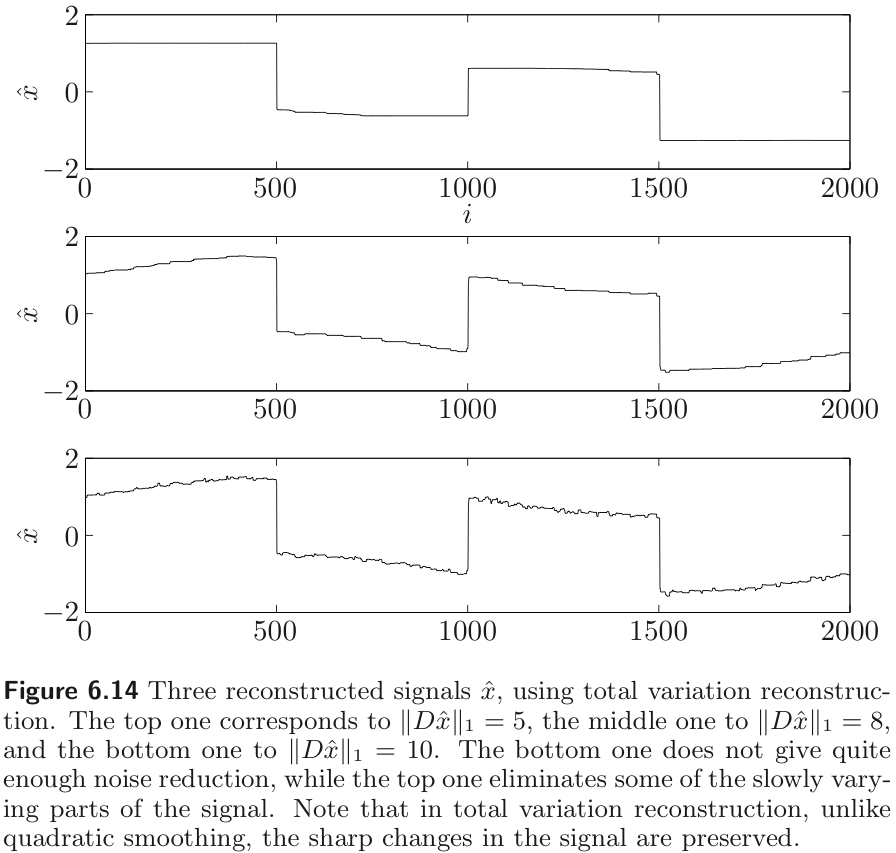
💡
total variation smoothing preserves sharp transitions in signal because -norm has less sensitive for the large value than -norm.
Robust approximation
We consider an approximation problem with basic objective , but also wish to take into account some uncertainty or possible variation in the data matrix . There are two approches to solve this problem.
- stochastic : assume is random and minimize
- worst-case : set of possible values of and minimize
Stochastic robust approximation
We assume that is a random variable taking values in , with mean . Then
where is a random matrix with zero mean.
It is natural to use the expected value of as the objective
We refer to this problem as the stochastic robust approximation problem.
💡
It is always a convex optimization problem, but usually not tractable.
Worst-case robust approximation
It is also possible to model the variation in the matrix using a worst case approach. We describe the uncertainty by a set of possible values for
which we assume is non-empty and bounded. We define the associated worst-case error of a candidate approximate solution as
which is always a convex function of .
💡
It is a convex function because it is just a point-wise supremum which is always convex.
The worst-case robust approximation problem is to minimize the worst case error
where the variable is , and the problem data are and the set .
💡
When is the singleton, the robust approximation problem reduces to the basic norm approximation problem.
It is always a convex optimization problem, but its tractability depends on the norm used and the description of uncertainty of .
Example
To illustrate the difference between the stochastic and worst-case formulations for the robust approximation problem, we consider the least squares problem
where is an uncertain parameter and . We consider a specific instance of the problem, with , , and in the interval .
We find three approximate solutions
- Nominal optimal : The optimal solution is found, which minimize
- Stochastic robust approximation : We find , which minimizes , assuming the parameter is uniformly distributed on
- Worst-case robust approximation. We find , which minimizes
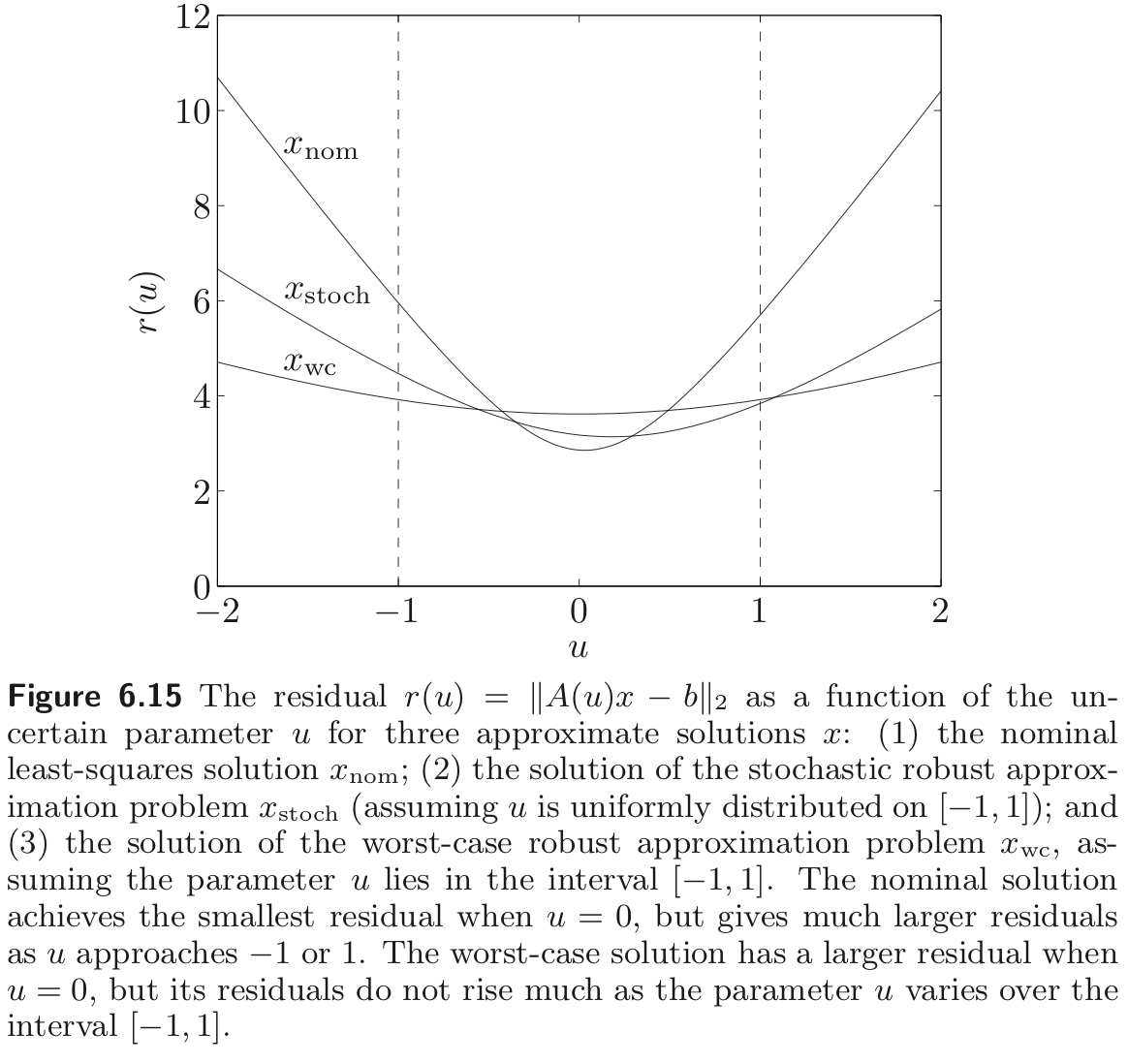
Example : stochastic robust Least squares
Consider the stochastic robust least-squares problem
where , is a random matrix with zero mean.
We can express the objective as
where
Therefore, the stochastic robust approximation problem has the form of regularized least-squares problem
with solution
When the matrix is subject to variation, the vector will have more variation the laarger is, and Jensen’s inequality tells us that variation in will increase the average value of . So we need to balance making small with the desire for a small to keep the variation in small.
For , we can get Tikhonov regularized least squares problem
💡
Therefore, regularized least squares problem can be interpreted as a stochastic concept and vice versa.
Example : worst case robust least squares
Let
Consider the worst case robust least-squares problem
where
Note that the strong duality holds between the following problems
- Primal problem
subject to
💡Intuitively, we can solve this problem by finding a maximum singular value.
- Dual problem
subject to
💡
It is a very specially case of satisfying the strong duality condition when the problem is not a convex.
Therefore, the Lagrange dual of this problem can be expressed as the SDP
subject to
with variables .
For fixed , we can compute by solving the SDP with variables and . In other words, optimizing jointly over , and is equivalent to minimizing worst case error .
💡
Therefore, the robust least squares problem is equivalent to the SDP with as variables.
반응형
Contents
소중한 공감 감사합니다