fi:Rn→R,i=1,…,m are the inequality constraint functions
hi:Rn→R,i=1,…,p are the inequality constraint functions
Optimal value
p∗=inf{fo(x)∣fi(x)≤0,i=1,…,m,hi(x)=0,i=1,…,p}
p∗=∞ if a problem is infeasible (no x satisfies the constraints)
p∗=−∞ if a problem is unbounded below
Optimal and locally optimal points
x is feasible if x∈dom f0 and it satisfies all constraints
a feasible x is optimalf0(x)=p∗; Xopt is the set of optimal points
x is locally optimal if there is an R>0 such that x is optimal for
minimize f0(z)
subject to
fi(z)≤0,i=1,…,mhi(z)=0,i=1,…,p∥z−x∥2≤R
💡
It can be interpreted as the restricted domain of f0
Examples
f0(x)=1/x,dom f0=R++ : p∗=0, but it has no optimal point.
💡
We have to distinguish between optimal point and optimal value
f0(x)=−logx,dom f0=R++: p∗=−∞
Implicit constraints
the standard form optimization problem has an implicit constraint
x∈D=i=0⋂mdom fi∩i=1⋂pdom hi
we call D the domain of the problem.
Feasibility problem
find x
subject to
fi(x)≤0,i=1,…,mhi(x)=0,i=1,…,p
can be considered a special case of the general problem with f0(x)=0
Convex optimization problem
minimize f0(x)
subject to
fi(x)≤0,i=1,…,mhi(x)=0,i=1,…,p
f0,…,fm are convex, h1,…,hp are affine
problem is quasi-convex if f0 is quasi-convex and f1,…,fm convex
often written as
minimize f0(x)
subject to
fi(x)≤0,i=1,…,mAx=b
💡
feasible set of a convex optimization problem is a convex set
💡
The convex optimization problem is not an attribute of the feasible set. It is an attribute of the problem description.
equivalent problem : by solving one, we can construct the other solution
identical problem : objective and constraints are identical
Local and global optima
any locally optimal point of a convex problem is globally optimal
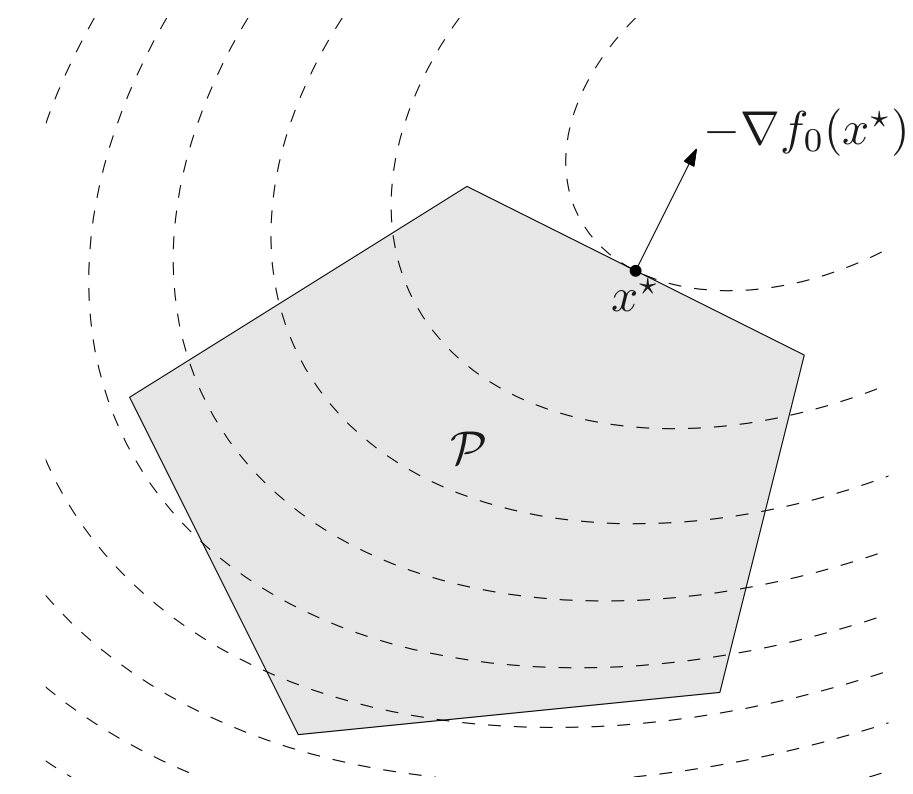
Optimality criterion for differentiable objective function
Suppose that the objective f0 in a convex optimization problem is differentiable, so that for all x,y∈dom f0,
f0(y)≥f0(x)+∇f0(x)T(y−x)
Then x is optimal if and only if it is feasible and
∇f0(x)T(y−x)≥0
for all feasible y
Proof
We already know that f0(y)≥f0(x)+∇f0(x)T(y−x)
If ∇f0(x)T(y−x)≥0 for all feasible y, then f0(y)≥f0(x) for all feasible y. Therefore, x is optimal.
Conversely, suppose x is optimal and there exists y is feasible region such that
∇f0(x)T(y−x)<0
That means y is located in the half-space that corresponds to the negative sign of the ∇f0(x). It contradicts the assumption.
Therefore, ∇f0(x)T(y−x)≥0 for all y in the feasible region.
💡
if non-zero, ∇f0(x) defines a supporting hyperplane to a feasible set X at x
unconstrained problem : x is optimal if and only if
x∈dom f0∇f0(x)=0
💡
In an unconstrained problem case, we can put arbitrary y so the only option that we can choose is ∇f0(x)=0
equality constrained problem
minimize f0(x)
subject to
Ax=b
(Assume that it is non-empty; otherwise the problem is unfeasible)
x is optimal if and only if there exists a ν such that
x∈dom f0Ax=b∇f0(x)+ATν=0
Proof
Since x,y is in the feasible region,
Ax=b and Ay=b
That means
x−y∈N(A)
Therefore, the first optimality condition can be written as
∇f0(x)Tz≥0,∀z∈N(A)
Since N(A) is a subspace,
∇f0(x)T(−z)≥0,∀∈N(A)
That means
∇f0(x)Tz=0,∀z∈N(A)
So,
∇f0(x)⊥N(A)
Since N(A)⊥R(AT), (equivalently, R(AT) is row space of A)
3F theorem (Linear algebra and its application written by Gilbert Strang)
∇f0(x)∈R(AT)⇒∃v∈dom A,∇f0(x)=ATv
Since dom A is a vector space, it is equivalent to say that
∃v∈dom A,∇f0(x)+ATv=0
💡
This is the classical Lagrange multiplier optimality condition
minimization over nonnegative orthant
minimize f0(x)
subject to
x⪰0
x is optimal if and only if
x∈dom f0x⪰0{∇f0(x)i≥0∇f0(x)i=0xi=0xi>0
Proof
The first order optimality condition is
∇f0(x)T(y−x)≥0
for all feasible y
Since y is in the feasible region, y⪰0. So ∇f0(x)⪰0, it not ∇f0(x)Ty is not unbounded below. Then ∇f0(x)Ty≥0 for all feasible y.
Therefore
−∇f0(x)Tx≥0
Since ∇f0(x)⪰0,x⪰0,
{∇f0(x)i≥0∇f0(x)i=0xi=0xi>0
Equivalent convex problems
two problems are (informally) equivalent if the solution of one is readily obtained from the solution of the other, and vice-versa
some common transformations that preserve convexity
Eliminating equality constraints
minimize f0(x)
subject to
fi(x)≤0,i=1,…,mAx=b
is equivalent to
minimize zf0(Fz+x0)
subject to
fi(Fz+x0)≤0i=1,…,m
where F and x0 are such that
Ax=b⇔x=Fz+x0 for some z
Actually let y is in the feasible region (i.e. Ay=b and fi(y)≤0,∀i)
Ax=b,Ay=b⇒x−y∈N(A)
Let N is a matrix which its columns is the linearly independent vector in N(A)
💡
However, this problem requires at least one feasible point x0
💡
If the original problem is a convex problem, the transformed problem is also a convex problem since it is just the composition of the affine function.
Introducing equality constraints
minimize f0(A0x+b0)
subject to
fi(Aix+bi)≤0,i=1,…,m
is equivalent to
minimize x,yif0(y0)
subject to
fi(yi)≤0,i=1,…,myi=Aix+bi,i=1,…,m
💡
Since this approach eventually increases the number of constraints, there is no progress at first glance. However, this approach can lead to significant progress.
Introducing slack variables for linear inequalities
minimize f0(x)
subject to
aiTx≤bii=1,…,m
is equivalent to
minimize x,sf0(x)
subject to
aiTx+si=bi,i=1,…,msi≥0i=1,…,m
💡
This approach can be applicable when we solve the linear programming problem.
Epigraph form
standard form convex problem is equivalent to
minimize x,tt
subject to
f0(x)−t≤0fi(x)≤0,i=1,…,mAx=b
💡
By using this, we can change our objective function as a linear objective.
Minimizing over some variables
minimize f0(x1,x2)
subject to
fi(x1)≤0i=1,…,m
is equivalent to
minimize fˉ0(x1)
subject to
fi(x1)≤0i=1,…,m
where fˉ0(x1)=infx2f0(x1,x2)
💡
We already know that fˉ0 is a convex function.
💡
Dynamic programming preserves the convexity of the problem.
Quasi-convex optimization
minimize f0(x)
subject to
fi(x)≤0,i=1,…,mAx=b
with f0:Rn→R quasi-convex, f1,…,fm convex.
Unlike the convex optimization case, it can have locally optimal points that are not globally optimal.
Nevertheless, a variation of the first-order optimality condition does hold for quasi-convex optimization problems with differentiable objective functions.
In quasi-convex optimization problem, x is optimal if
x∈X,∇f0(x)T(y−x)>0,∀y∈X∖{x}
💡
Unlike the convex optimization case, it is only sufficient for optimality.
Representation via a family of convex functions
It will be convenient to represent the sublevel sets of a quasi-convex function f via inequalities of convex functions. We seek a family of convex functions ϕt such that
f0(x)≤t⇔ϕt(x)≤0
Evidently ϕt must satisfy the property that for all x∈Rn,
ϕs(x)≤0⇒ϕt(x)≤0
for s≥t. This is satisfied if for each x, ϕt(x) is a non-increasing function of t (i.e. ϕs(x)≤ϕt(x) whenever s≥t.
If we take
ϕt(x)={0∞f(x)≤totherwise
it satisfies the above conditions.
💡
We call it the indicator function of the t-sublevel of f
Note that this representation is not unique, for example, if the sublevel sets of f are closed, we can take
ϕt(x)=dist(x,{z∣f(z)≤t})=zsup{d(z,x)∣f(z)≤t}
Example
f0(x)=q(x)p(x)
with p convex, q concave, and p(x)≥0,q(x)>0 on dom f0 can take ϕt(x)=p(x)−tq(x)
for t≥0,ϕt convex in x
p(x)/q(x)≤t if and only if ϕt(x)≤0
Quasi-convex optimization via convex feasibility problems
Let ϕt:Rn→R,t∈R be a family of convex functions that satisfy
f0(x)≤t⇔ϕt(x)≤0
and also, for each x, ϕt(x) is a non-increasing function of t, i.e.
s≥t⇒ϕs(x)≤ϕt(x)
Let p∗ is the optimal value of the quasi-convex optimization problem.
If the feasibility problem
find x
subject to
ϕt(x)≤0fi(x)≤0,i=1,…,mAx=b
is feasible, then we have p∗≤t. Conversely, if the problem is infeasible, then we can conclude p∗≥t.
💡
Note that we want to find the minimum t such that satisfy the above feasibility problem. Since ϕt(x) is a non-increasing of t, if t satisfy the feasibility for s≥t, s is also satisfy the feasibility.
💡
Note that the above problem is a convex feasibility problem, since the inequality constraint functions are all convex, and the equality constraints are linear.
This can be used as the basis of a simple algorithm for solving the quasi-convex optimization problem using bisection (solving a convex feasibility problem at each step)
Assume that the problem is feasible, and start with an interval [l,u] known to contain the optimal value p∗. When then solve the convex feasibility problem at its midpoint t=(l+u)/2, to determine wheter the optimal value is in the lower or upper half of the interval, and update the interval accordingly. This produces a new interval, which also contains the optimal value, but has half the width of the initial interval.
Basically, the idea is same as the parametric search algorithm.
The blue area in the above figure represents the range of t that satisfies feasibility.
Canonical Problems
Depending on the types of objective function and constraints, optimization problems can be categorized. We will delve into the following six subcategories
We already know that linear fractional function is a quasi-convex function
It can be solved by bisection like this
f0(x)≤t⇔cTx+d≤t(eTx+f)
If the feasible set is non-empty, the linear-fractional program can be transformed to an equivalent linear program
minimize cTy+dz
subject to
Gy⪯hzAy=bzeTy+fz=1z≥0
with variables y,z
Proof
If x is feasible in our original problem, then
y=eTx+fx,z=eTx+f1
is feasible in the LP problem, with the same objective value cTy+dz=f0(x). Therefore the optimal value of the original problem is greater than or equal to the optimal value of the LP problem. It is has a y,z corresponds to the optimal point of the original problem.
Conversely,
if (y,z) is feasible in the LP problem with z=0, then x=y/z is feasible in the original problem.
If (y,z) is feasible in the LP problem with z=0 and x0 is feasible for the original problem. Then x=x0+ty is feasible in the original problem for all t≥0. Moreover, limt→∞f0(x0+ty)=cTy+dz, so we can find feasible points in the original function with objective values arbitrarily close to the objective value of (y,z)
💡
The basic idea is that if we add the additional variable z, we can normalize it by using x and z. Therefore we can eliminate the denominator. So if z is positive, we can think it as a normalization.
💡
If z=0, we can arbitrary add y to x0. This is a main idea to prove above.
Generalized linear-fractional program
f0(x)=i=1,…,rmaxeiTx+fjciTx+di
where dom f0(x)={x∣eiTx+fi>0,i=1,…,r}
a quasi-convex optimization problem. Unlike the linear fractional problem, there is no way to directly convert to LP. However, since it is a quasi-convex problem, it can be solved by bisection.
💡
The sublevel set is just the intersection of sublevel sets which is convex. Therefore, the objective function is a quasi-convex function.
Quadratic program (QP)
The convex optimization problem is called a quadratic program(QP) if the objective function is convex quadratic, and the constraint functions are affine.
minimize 21xTPx+qTx+r
subject to
Gx⪯hAx=b
where P∈S+n,G∈Rm×n and A∈Rp×n
In a quadratic program, we minimize a convex quadratic function over a polyhedron.
Note that if P∈S++n, a sublevel set is a elipsoid
Proof
Since P is symmetric and positive definite matrix, it has a orthonomal eigenvector. Let say eigenvectors {v1,…,vn}, and eigenvalue {λ1,…,λn}.
Therefore, it is a ellipsoid if it is not a empty set.
💡
If P is not a positive semi-definite (i.e. it has a negative eigenvalue), the problem is belongs to NP hard.
Quadratically constrained quadratic program (QCQP)
minimize 21xTP0x+q0Tx+r0
subject to
21xTPix+qiTx+ri≤0,i=1,…,mAx=b
where Pi∈S+n.
If P1,…,Pm∈S++n, the feasible region is a intersection of m ellipsoids and an affine set.
Examples
Lest-squares
We already know that
∥Ax−b∥22=xTATAx−2bTAx+bTb
and since
xTATAx=(Ax)T(Ax)=⟨Ax,Ax⟩=∥Ax∥≥0
for all x, ATA is a positive semi-definite matrix.
Therefore
minimize ∥Ax−b∥22
it is a Quadratic programming.
Actually, this problem is simple enough to have the well known analytical solution x∗=A†b (A† is a pseudo-inverse of A)
When linear inequality constraints are added, the problem is called constrained regression or constrained least-squares
💡
There are no analytical solution for these cases.
As an example we can consider regression with lower and upper bounds on the variables
minimize ∥Ax−b∥22
subject to
li≤xi≤uii=1,…,n
There is another example like this
minimize ∥Ax−b∥22
where x1≤x2≤⋯≤xn
Actually, it is just adding a set of linear inequalities. Therefore, it is a quadratic programming.
Second-order cone programming (SOCP)
minimize fTx
subject to
∥Aix+bi∥2≤ciTx+di,i=1,…,mFx=g
where x∈Rn,Ai∈Rni×n,F∈Rp×n.
We call a constraint of the form
∥Ax+b∥2≤cTx+d
where A∈Rk×n, a second-order cone constraint because
(Aix+bi,ciTx+di)∈second-order cone in Rni+1
If ci=0 for all i=1,⋯,m, then the SOCP is equivalent to a QCQP.
If Ai=0 for all i=1,…,m, then the SOCP reduces to a general LP
💡
It is more general than QCQP and LP
Let fi(x)=∥Aix+bi∥2−ciTx−di. Then, it is not differentiable for all x since it is not differentiable at Aix+bi=0. It might seems it is okay to neglect that points at the first glance, but we can’t because normally that the solution is very often at these points.
💡
Currently, we can solve SOCP as fast as LP.
Examples
Robust linear programming
the parameters in optimization problems are often uncertain
minimize cTx
subject to
aiTx≤bii=1,…,m
there can be uncertainty in c,ai,bi
two common approaches to handling uncertainty (for simplicity, ai has only uncertainty)
deterministic model: constraints must hold for all ai∈Ei
minimize cTx
subject to
aiTx≤bi for all ai∈Eii=1,…,m
💡
Since constraints must satisfy for all uncertainty region, this approach is called worst case model.
Note that the additional norm terms act as regularization terms ; they prevent x from being large in directions with considerable uncertainty in the parameters ai.
💡
Since SOCP is as fast as LP, it can be applicable when we want to solve the finance problem.
stochastic model: ai is random variable; constraints must hold with probability η
minimize cTx
subject to
prob(aiTx≤bi)≥ηi=1,…,m
💡
Alleviate the condition by using probability
Assume ai is Gaussian with mean aˉi, covariance Σi (i.e. ai∼N(aˉi,Σi))
Then aiTx∼N(aˉiTx,xTΣix). So,
prob(aiTx≤bi)=Φ(∥Σi1/2x∥2bi−aˉiTx)
where Φ(x) is CDF of N(0,1)
Then it can be written as
minimize cTx
subject to
aˉiTx+Φ−1(η)∥Σi1/2x∥2≤bii=1,…,m
If Φ−1(η)≥0 (i.e. η≥1/2), it is equivalent to the SOCP.
Geometric program (GP)
Monomial function
f(x)=cx1a1x2a2⋯xnandom f=R++n
with c>0 and ai∈R, is called a monomial function
💡
In mathematics, monomial has non-negative integers as its exponents. So the above definition is not a standard definition.
Posynomial function
it is just a sum of monomials
f(x)=k=1∑Kckx1a1kx2a2k⋯xnankdom f=R++n
Geometric program (GP)
minimize f0(x)
subject to
fi(x)≤1,i=1,…,mhi(x)=1i=1,…,p
where f0 is a posynomial function, hi is a monomial function.
Geometric program in convex form
Geometric programs are not generally convex optimization problem, but they can be transformed to convex problems by a change of variables and a transformation of the objective and constraint functions.
monomial f(x)=cx1a1⋯xnan transforms to
logf(ey1,…,eyn)=aTy+b
where b=logc
posynomial f(x)=∑k=1Kckx1a1k⋯xnank transforms to
logf(ey1,…,eyn)=log(k=1∑KeeakTy+bk)
where bk=logck
💡
We already know that log-sum-exp is a convex function in y
Therefore, geometric program transforms to a convex problem
minimize log(k=1∑Kexp(a0kTy+b0k))
subject to
log(k=1∑Kexp(aikTy+bik))≤0giTy+hi=0
Generalized inequality constraints
One very useful generalization of the standard form convex optimization problem is obtained by allowing the inequality constraint functions to be vector valued , and using generalized inequalities in the constraints.
minimize f0(x)
subject to
fi(x)⪯Ki0i=1,…,mAx=b
where f0:Rn→R,Ki⊂Rki are proper cones, and fi:Rn→RkiKi-convex.
💡
Later, we will see that convex optimization problems with generalized inequality constraints can often be solved as easily as ordinary convex optimization problems.
Conic form problems
special case with affine objectives and constraints
minimize cTx
subject to
Fx+g⪯K0Ax=b
extends linear programming (K=R+m) to non-polyhedral cones
Semidefinite programming
minimize cTx
subject to
x1F1+⋯+xnFn+G⪯0Ax=b
where G,F1,…,Fn∈Sk, and A∈Rp×n
💡
inequality constraint is called linear matrix inequality (LMI). That means the left-hand side is negative semi-definite.
Note that it includes problems with multiple LMI constraints
where A(x)=A0+x1A1+⋯+xnAn with given Ai∈Sk
we can express it as a SDP form
minimize t
subject to
A(x)⪯tI
where x∈Rn,t∈R
it follows from the fact that
λmax(A)≤t⇔A⪯tI
Proof
λ is an eigenvalue of A(x) if and only if λ−t is an eigenvalue of A(x)−tI.
Therefore, λmax(A(x))≤t if and only if all eigenvalues of A(x)−tI are non-positive. (i.e. A(x)−tI⪯0)
Matrix norm
minimize ∥A(x)∥2:=(λmax(A(x)TA(x)))1/2
where x∈Rn,t∈R,A(x)=A0+x1A1+⋯+xnAn with given Ai∈Rp×q
💡
We already know that matrix norm is a convex function.
we can express it as a SDP form
minimize t
subject to
[tIA(x)TA(x)tI]⪰0
the above matrix is positive semi-definite if
tI≥0tI−tA(x)TA(x)⪰0
Since t is positive,
t2I⪰A(x)TA(x)
Therefore, all eigenvalues of A(x)TA(x) are less than equal to t2
Vector optimization
General vector optimization problem
minimize f0(x) (with respect to K)
subject to
fi(x)≤0i=1,…,mhi(x)=0i=1,…,p
vector objective f0:Rn→Rq minimized with respect to proper cone K∈Rq
💡
How to compare the value of vectors? There’s a lot of ways to do that. (i.e. lexicographical order)
Convex vector optimization problem
minimize f0(x) (with respect to K)
subject to
fi(x)≤0i=1,…,mAx=b
with f0K-convex, f1,…,fm convex.
Optimal and Pareto optimal points
set of achievable objective values
O={f0(x)∣x feasible}
feasible x is optimal if f0(x) is a minimum value of O
x∗ is optimal since it is comparable to any other points in O and it is also less than any other point in O
feasible x is Pareto optimal if f0(x) is a minimal value of O
xpo is Pareto optimal since there is non-comparable point in O
Multi-criterion optimization
vector optimization problem with K=R+q
f0(x)=(F1(x),…,Fq(x))
where we want all Fi’s to be small
feasible x∗ is optimal if
y feasible⇒f0(x∗)⪯f0(y)
if there exists an optimal point, the objectives are non-competing
feasible xpo is Pareto optimal if
y feasible,f0(y)⪯f0(xpo)⇒f0(xpo)=f0(y)
if there are multiple Pareto optimal values, there is a trade-off between the objectives.
Example : Regularized least-squares
minimize (∥Ax−b∥22,∥x∥22) (w.r.t R+2)
💡
In the deep learning concept, this concept can be interpreted as a regularization.
Scalarization
Scalarization is a standard technique for finding Pareto optimal points for a vector optimization problem. To find Pareto optimal points: choose λ≻K∗0 and solve scalar problem
minimize λTf0(x)
subject to
fi(x)≤0,i=1,…,mhi(x)=0i=1,…,p
💡
One way to say that f0 is K-convex, if λTf0(x) is convex a function function for all λ∈K∗
💡
Any optimal points in this problem is the Pareto optimal problem for the original problem.
💡
for convex vector optimization problems, can find (almost) all Pareto optimal points by varying λ≻K∗0
Scalarization for multicriterion problems
to find Pareto optimal points, minimize positive weighted sum
λTf0(x)=λ1F1(x)+⋯+λqFq(x)
Example
Regularized least-squares problem
Take λ=(1,γ) with γ>0
minimize ∥Ax−b∥22+γ∥x∥22
for fixed γ
💡
In Deep learning perspective, this can be interpreted as a regularization term.







 https://en.wikipedia.org/wiki/Piecewise_linear_function
https://en.wikipedia.org/wiki/Piecewise_linear_function