It is often convenient to extend a convex function to all of Rn by defining its value to be ∞ outside its domain. If f is convex we define its extended-value extension f~ of f is
f~(x)={f(x)x∈dom f∞x∈/dom f
The extension can simplify notation, since we don’t need to explicitly describe the domain.
First-order condition
f is differentiable if dom f is open and the gradient
∇f(x)=(∂x1∂f(x),∂x2∂f(x),⋯,∂xn∂f(x))T
exists at each x∈dom f
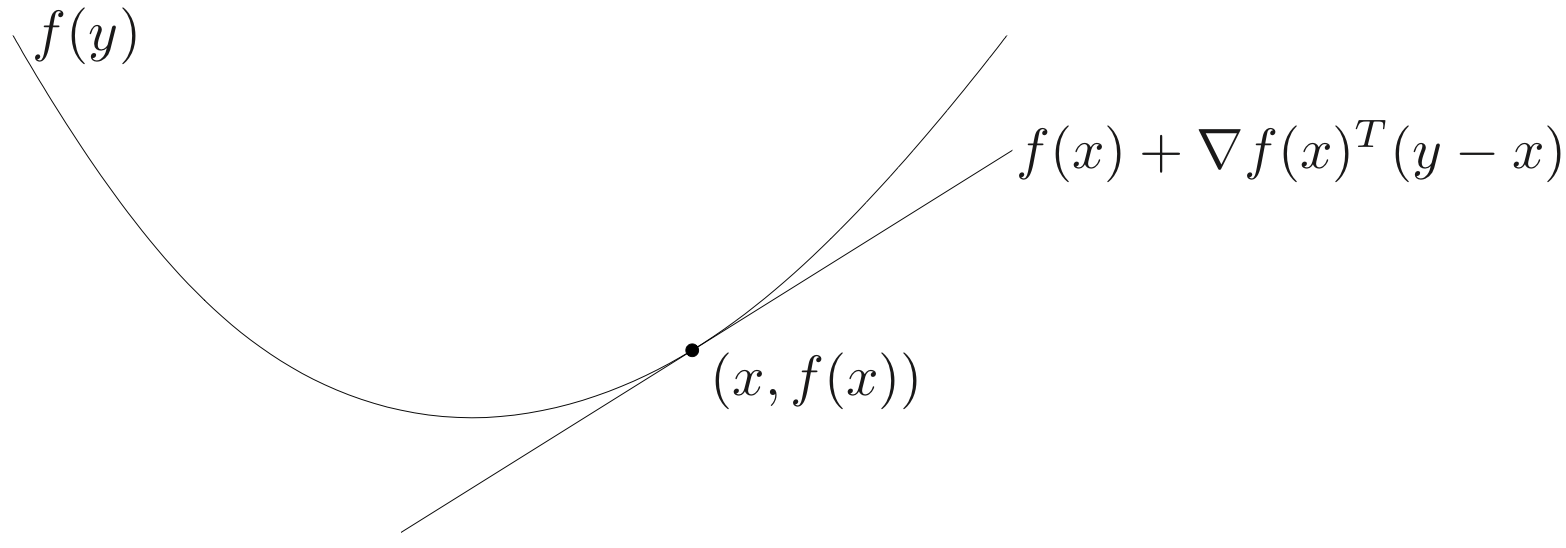
1st-order condition : differentiable f with convex domain is convex if and only if
f(y)≥f(x)+∇f(x)T(y−x),∀x,y∈dom f
Second-order conditions
f is twice differentiable if dom f is open and the Hessian ∇2f(x)∈Sn,
∇2f(x)ij=∂xi∂xj∂2f(x),i,j=1,…,n
or equivalently
∇2f(x)ij=Hx(i,j)
where Hx is a hessian matrix at x.
2nd-order condition : for twice differentiable f with convex domain
f is convex if and only if
∇2f(x)⪰0,∀x∈dom f
if ∇2f(x)≻0,∀x∈dom f, then f is strictly convex.
Example
Quadratic function : f(x)=21xTPx+qTx+r (with P∈Sn)
∇f(x)=Px+q,∇2f(x)=P
convex if P⪰0
Least-squares objective : f(x)=∥Ax−b∥22
∇f(x)=2AT(Ax−b),∇2f(x)=2ATA
convex for any A since ATA is always positive semi-definite.
Therefore, ∇2f(x) is a positive semi-definite matrix.
💡
This function is a smooth approximation of a maximum since the maximum number nominate the value. In deep learning or machine learning perspective, we call this function as a softmax function.
geometric mean : f(x)=(∏k=1nxk)1/n on R++n is concave
Epigraph and sublevel set
α-sublevel set of f:Rn→R:
Cα={x∈dom f∣f(x)≤α}
sublevel sets of convex functions are convex
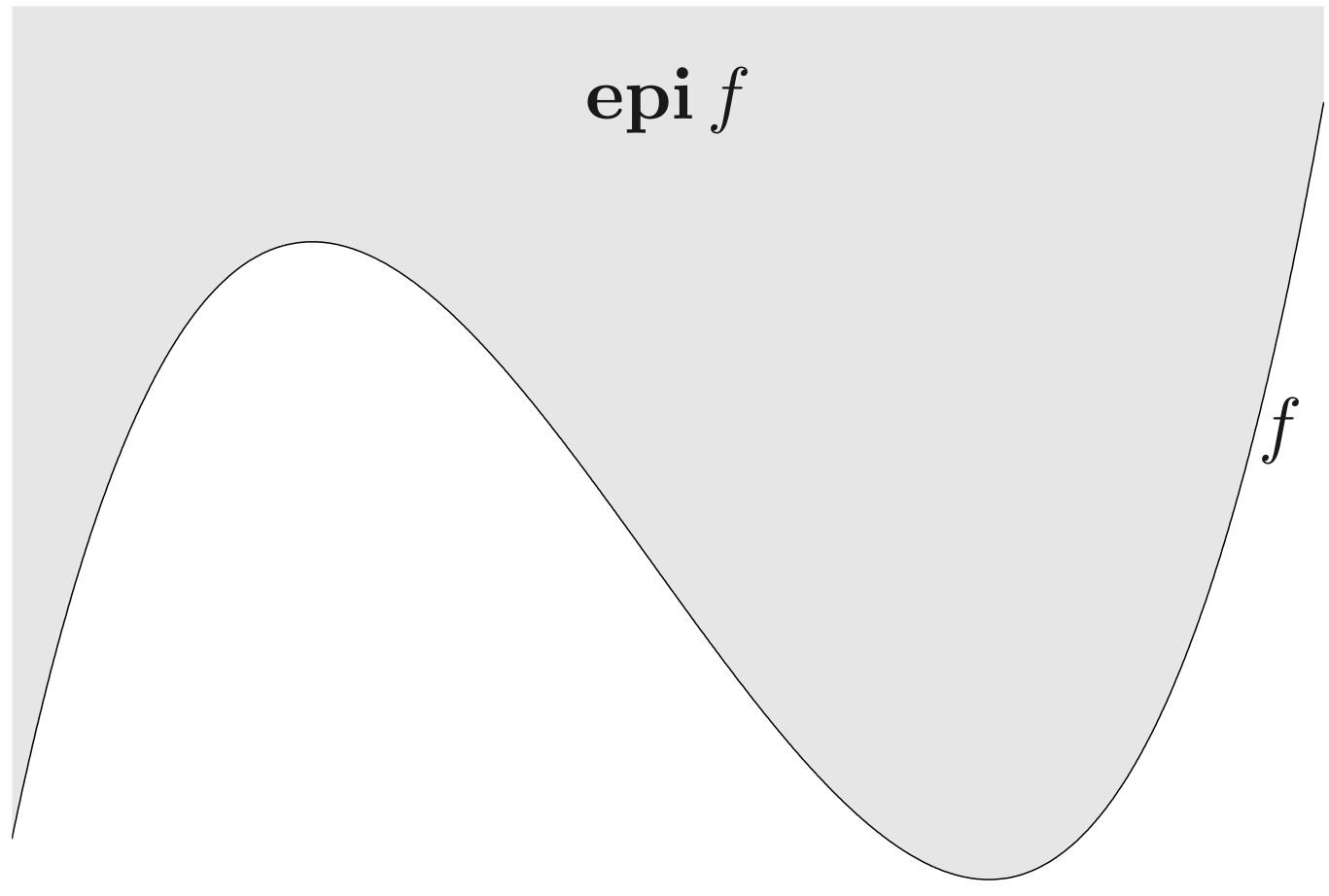
epigraph of f:Rn→R
epi f={(x,t)∈Rn+1∣x∈dom f,f(x)≤t}
💡
f is convex if and only if epi f is a convex set.
Jensen’s inequality
basic inequality : if f is convex, then for 0≤θ≤1
f(θx+(1−θ)y)≤θf(x)+(1−θ)f(y)
💡
It actually extended to the finite sum to infinite sum. Therefore, this equality still holds if we integrate them. That’s why the following inequality holds.
extension : if f is convex, then
f(Ez)≤Ef(z)
for any random variable z
💡
The clarity of this result stems from the fundamental nature of abstract integration, which essentially involves the summation of infinitesimally small quantities.
Operations that preserve convexity
practical methods for establishing convexity of a function
by using definition
for twice differentiable functions, show ∇2f(x)⪰0,∀x
show that f is obtained from simple convex functions by operations that preserve convexity
Since α≥f(x1) for all x1∈dom f and β≥f(x2) for all x2∈dom g, α+β≥f(x)+g(x) for all x∈dom f+g
So, α+β is a upper bound of f+g
Therefore, supx(f(x)+g(x))≤supxf(x)+supxg(x)
Epigraph interpretation
In terms of epigraphs, the point-wise supremum of functions corresponds to the intersection of epigraphs: with f,g. we have
epi g=y∈A⋂epi f(⋅,y)
Thus, the result follows from the fact that the intersection of a family of convex set is convex.
Red and green areas represent the epigraph of f(x,y) for a fixed x. As f is convex in x, both the red and green areas are convex sets. Our objective is to intersect the epigraph with a given point x to determine the maximum (supremum) value for the given x.
Examples
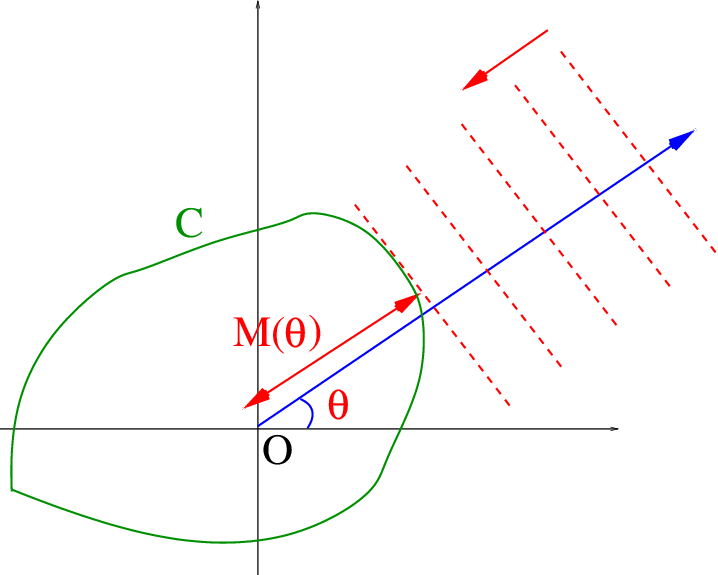
support function of a set C
SC(x)=y∈CsupyTx
The normal vector of the red dotted line is x
💡
Note that C don’t have to be a convex set.
distance to farthest point in a set C
f(x)=y∈Csup∥x−y∥
maximum eigenvalue of symmetric matrix
λmax(X)=∥y∥2=1supyTXy
where X∈Sn
💡
yTXy is a linear function in x for each y.
Proof
Since X∈Sn, there exists an orthonormal basis by spectral theorem.
We have seen that the maximum and supremum of an arbitrary family of convex functions is convex. It turns out the some special forms of minimization also yields convex functions.
if f(x,y) is convex in (x,y) and C is a convex set, then
g(x)=y∈Cinff(x,y)
where g(x)>−∞ for all x
is convex.
We have to compare the condition for the point-wise supremum case. Note that f(x,y) is convex in (x,y). In point-wise supremum case, it is enough to satisfy only x
The fundamental idea is that we want to use convexity of f that makes slightly bigger than we want. We can control the amount of its value by using the definition of infimum.
Epigraph interpretation
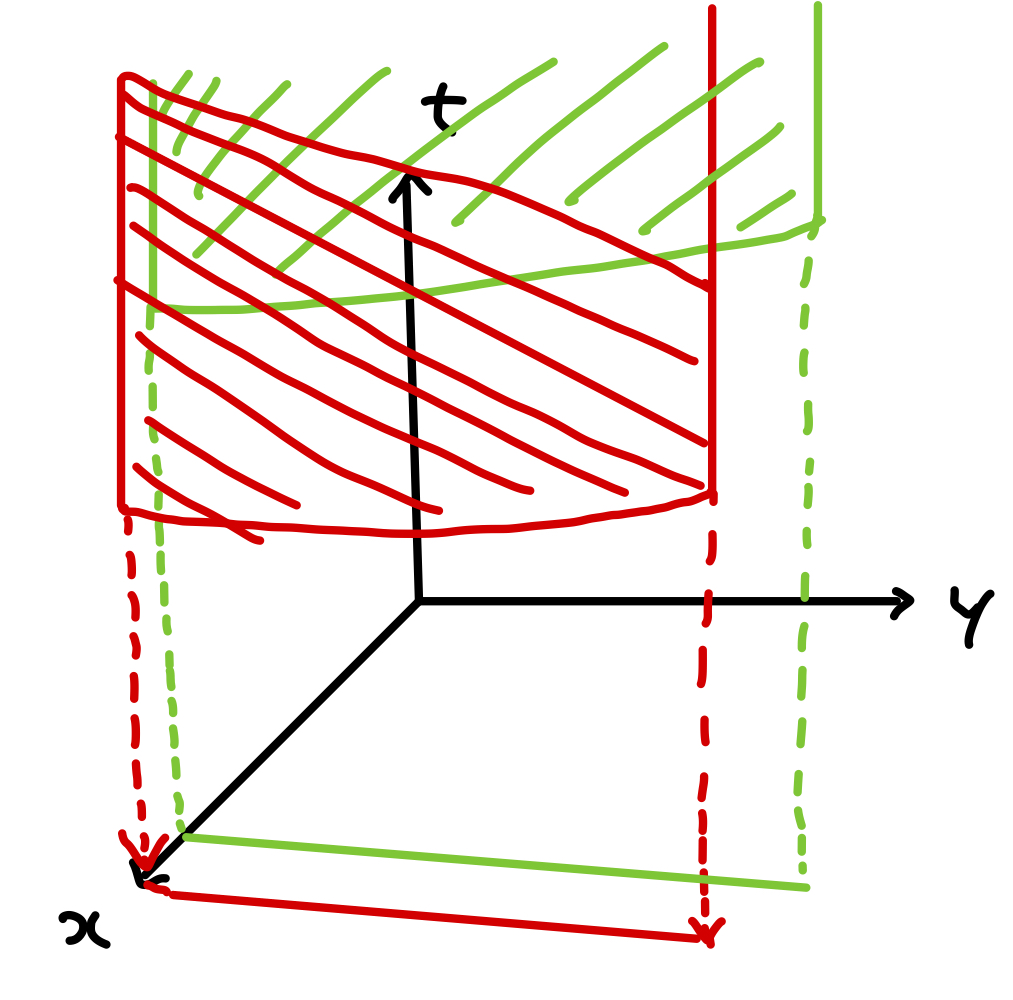
Assume the infimum over y∈C is attained for each x (i.e. {f(x,y)∣y∈C} is closed set for each x). We have
epi g={(x,t)∣(x,y,t)∈epi f for some y∈C}
Since the projection of a convex set on some of its components is convex, epi g is a convex set.
💡
Intuitively, we can interpret this as a projection of epi f to xt plane which is a convex set.
💡
Generally, the union of the convex set is not a convex set. So we can’t apply the same approach for the supremum or maximum case. Therefore, the condition for minimization case is stronger than them (i.e. convexity with respect to (x,y))
Example
f(x,y)=xTAx+2xTBy+yTCy with
[ABTBC]⪰0,C≻0
We can express g(x)=infyf(x,y) as
g(x)=xT(A−BC†BT)x
where C† is the pseudo-inverse of C. Since g is convex, A−BC†BT⪰0
If C is invertible, then A−BC−1BT is called the Schur complement of C in the matrix
[ABTBC]
💡
A convex quadratic function and if minimize that function over some variables, the result is quadratic form.
distance to a set : dist(x,S)=infy∈S∥x−y∥ is convex if S is convex.
Composition with scalar functions
composition of g:Rn→R and h:R→R
f(x)=h(g(x))
f is convex if
g convex, h convex, h~ non-decreasing
g concave, h convex, h~ non-increasing
where h~ is a extended value extension
💡
There are no assumption related to twice differentiability of h and g
If we assume that n=1 and twice differentiable for g,h we can get an intuition
f′′(x)=h′′(g(x))g′(x)2+h′(g(x))g′′(x)
Think about this example,
h(x)=x2x∈R+
This function is trivially increasing. However,
h~(x)={x2x∈R+∞otherwise
this function is not a increasing function.
Interpretation of h~
To say that h~ is nondecreasing means that for any x,y∈R (x<y), we have h~(x)≤h~(y).
That means y∈dom h⇒x∈dom h
Therefore, the domain of h extends infinitely in the negative direction; it is either R or an interval like (−∞,a) or (∞,a]
Similarly, h~ is non-increasing means that the domain of h extends infinitely in the positive direction; it is either R or an interval like (a,∞) or [a,∞)
Proof
Let g is convex, h is convex, h~ is nondecreasing and x,y∈dom f,θ≥0.
Since x,y∈dom f, x,y∈dom g
Moreover we already know that g is convex,
g(θx+(1−θ)y)≤θg(x)+(1−θ)g(y)
Similarly since x,y∈dom f,
g(x),g(y)∈dom h⇒θg(x)+(1−θ)g(y)∈dom h (since dom h is convex set)⇒g(θx+(1−θ)y)∈dom h (since h~ is non-decreasing)
Since h~ is non-decreasing,
h(g(θx+(1−θ)y))≤h(θg(x)+(1−θ)g(y))
In addition, since θg(x)+(1−θ)g(y)∈dom h and h is a convex function,
h(θg(x)+(1−θ)g(y))≤θh(g(x))+(1−θ)h(g(y))
Therefore,
h(g(θx+(1−θ)y))≤θh(g(x))+(1−θ)h(g(y))
Therefore h∘g is a convex function.
Examples
expg(x) is convex if g is convex
💡
We already know that exponential function is convex and increasing function on R
1/g(x) is convex if g is concave and positive.
💡
We already know that 1/x is concave and non-increasing
Vector composition
composition of g:Rn→Rk and h:Rk→R
f(x)=h(g(x))=h(g1(x),g2(x),…,gk(x))
f is convex if
gi affine, h convex
gi convex, h convex, h~ non-decreasing in each argument
gi concave, h convex, h~ non-increasing in each argument
where h~ is a extended value extension
Proof
Without loss of generality, assume that gi convex, h convex, h~ non-decreasing in each argument.
Let x,y∈dom f,θ≥0 (i.e. x,y∈dom gi for each i and g(x),g(y)∈dom h)
Since gi is a convex function and x,y∈dom gi
gi(θx+(1−θ)y)≤θgi(x)+(1−θ)gi(y)
Since h is convex, πi(dom h) is a convex set for each i.
So,
θgi(x)+(1−θ)gi(y)∈πi(dom h),∀i
Therefore,
θg(x)+(1−θ)g(y)∈dom h
Moreover, h~ is non-decreasing in each argument and θgi(x)+(1−θ)gi(y)∈πi(dom h),∀i,
gi(θx+(1−θ)y)∈πi(dom h),∀i
Therefore,
g(θx+(1−θ)y)∈dom h
In addition,
h(g(θx+(1−θ)y))=h(g1(θx+(1−θ)y),⋯,gk(θx+(1−θ)y))≤h(θg1(x)+(1−θ)g1(y),⋯,gk(θx+(1−θ)y))≤h(θg1(x)+(1−θ)g1(y),⋯,θgk(x)+(1−θ)gk(y))=h(θ(g1(x),⋯,gk(x))+(1−θ)(g1(y),⋯,gk(x)))=h(θg(x)+(1−θ)g(y))≤θh(g(x))+(1−θ)h(g(y)) (since h is convex)
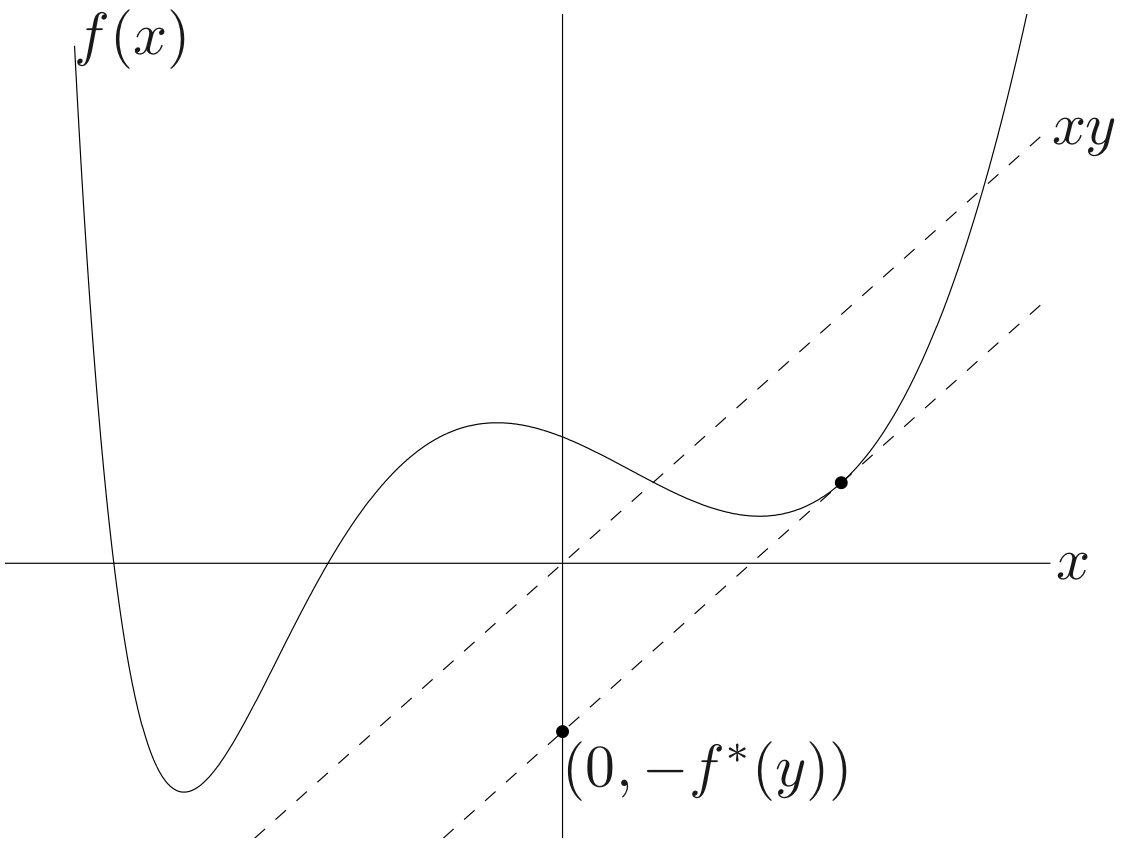
Let f(x) is a making cost, x is the number of product, y is the price for each product.
We want to maximize the profit. So our goal is to find the number of product maximize our benefit.
Note that f∗ is convex (even if f is not)
Proof
yTx−f(x) is affine with respect to y.
Moreover, it is the point-wise supremum of a family of convex (indeed, affine) functions of y. Therefore, it is actually a corollary of the supremum of the convex function is a convex function.
💡
The conjugate function, also known as the Legendre-Fenchel transform, is a powerful tool in convex analysis that allows us to recover info rmation about a given function. It provides a way to characterize the dual properties of a function, revealing its convexity, smoothness, and other important properties.
strictly convex quadratic : f(x)=(1/2)xTQx with Q∈S++n
f∗(y)=xsup(yTx−(1/2)xTQx)=21yTQ−1y
💡
Conjugate of quadratic form is the inverse matrix
Quasi-convex functions
f:Rn→R is quasi-convex if dom f is convex and the sublevel sets
Sα={x∈dom f∣f(x)≤α}
are convex for all α
A function is quasi-concave if −f is quasi-convex. A function that is both quasi-convex and quasi-concave is called quasi-linear.
Convex functions have convex sub-level sets, and so are quasi-convex.
Proof
We already know that epigraph of a convex function is a convex set. Moreover, {(x,y)∣y≤α} is a convex set.
Since the intersection of convex sets is also a convex set.
Therefore,
{(x,f(x))∣f(x)≤α,x∈dom f}
is a convex set.
Moreover, we already know that projection of certain coordinate is also a convex set. Therefore,
{x∈dom f∣f(x)≤α}
is a convex set.
Therefore, every convex function is a quasi-convex function.
Examples
∣x∣ is quasi-convex on R
ceil(x)=inf{z∈Z∣z≥x} is quasi-linear
logx is quasi-linear on R++
f(x1,x2)=x1x2 is quasi-concave on R++2
linear-fractional function
f(x)=cTx+daTx+bdomf={x∣cTx+d>0}
is quasi-linear
💡
Note that the sublevel set is half space
distance ratio
f(x)=∥x−b∥2∥x−a∥2dom f={x∣∥x−a∥2≤∥x−b∥2}
is quasi-convex.
Proof
We want to know whether {x∈dom f∣f(x)≤t} is a convex set or not for all a. (For simplicity, we assume that t is non-negative.)
Take g:R2→R, h1:R→R,h2:R→R as follows
h1(x)=∥x−a∥2h2(x)=∥x−b∥2g(x1,x2)=x1−tx2
Since h1,h2 are convex and g~ are non-decreasing and non-increasing respectively (if t is negative, g~ are both non-decreasing), g(h1(x),h2(x)) is a convex function.
As we proved above, every convex function is also a quasi-convex funciton.
Therefore,
{x∣∥x−a∥2−t∥x−b∥2≤0}⇔{x∣∥x−b∥2∥x−a∥2≤t}
is a convex set.
Since t is arbitrary,
{x∣∥x−a∥2−1∥x−b∥2≤0}⇔{x∣∥x−a∥2≤∥x−b∥2}
is a convex set.
Therefore,
{x∣∥x−b∥∥x−a∥≤t and ∥x−a∥2≤∥x−b∥2}⇔{x∈dom f∣f(x)≤t}
Therefore, f is a quasi-convex function.
Properties
modified Jensen’s inequality : for quasi-convex f
0≤θ≤1⇒f(θx+(1−θ)y)≤max{f(x),f(y)}
Proof
Since f is a quasi-convex function,
{t∈dom f∣f(t)≤f(x)}{t∈dom f∣f(t)≤f(y)}
are a convex set.
We already know that intersection of two convex sets is also a convex set. Therefore,
{t∈dom f∣f(t)≤max{f(x),f(y)}
is a convex set.
For simplicity, let’s say
A={t∈dom f∣f(t)≤max{f(x),f(y)}
Trivially, x,y∈A. Therefore, for given θ≥0,
θx+(1−θ)y∈A
So,
f(θx+(1−θ)y)≤max{f(x),f(y)}
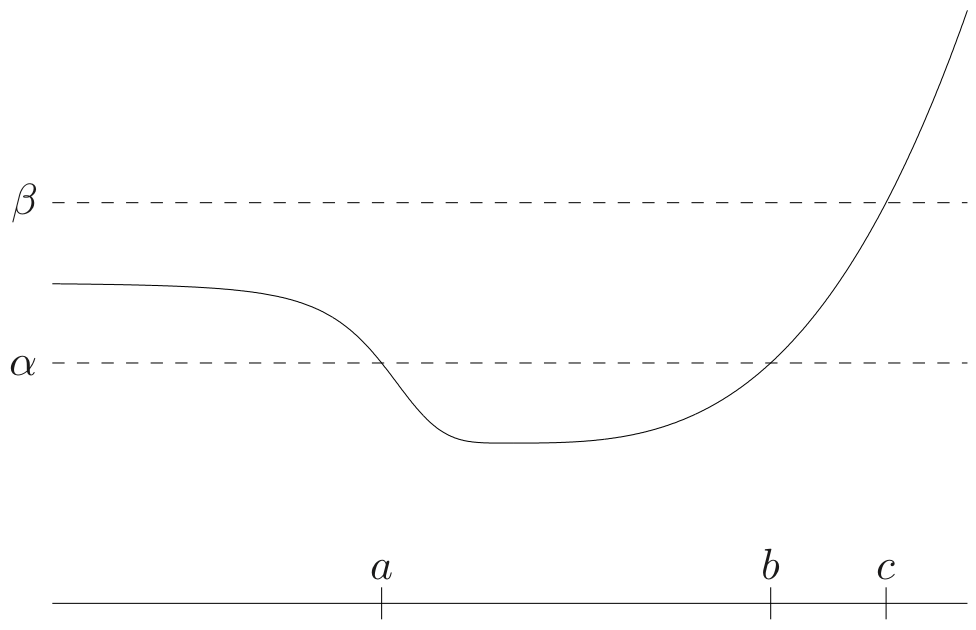
first-order condition : Suppose f:Rn→R is differentiable with dom f is convex. Then f is quasi-convex if and only if
Since ∇2f(x)T(y−x) is affine with respect to y, {y∣∇2f(x)T(y−x)≤0} is a convex set.
Therefore {x∈dom f∣f(x)≤a} is a convex set.
case 2 : ∄x∈dom f such that f(x)=a
Since f is differentiable, f is continuous for every x. Therefore, there are only two cases.
f(x)>a,∀x
In this case, there is no element in sub-level set. Therefore, it is a vacuously true to satisfy the convexity.
f(x)<a,∀x
In this case, {x∈dom f∣f(x)≤a}=dom f. We already know that dom f is a convex set.
Therefore {x∈dom f∣f(x)≤a} is a convex set.
💡
Taking into account that the sublevel set of a quasi-convex function is a convex set, one can understand the above concept as a restriction of the comparison region.
💡
Note that sums of quasi-convex functions are not necessarily quasi-convex.
Log-concave and log-convex functions
a positive function f is log-concave if logf
f(θx+(1−θ)y)≥f(x)θf(y)1−θ
for 0≤θ≤1
f is log-convex if logf is convex.
Examples
powers : xa on R++ is log-convex for α≤0, log-concave for α≥0
proof
alog(θx+(1−θ)y)≥aθlog(x)+a(1−θ)log(y)
if a≥0,
log(θx+(1−θ)y)≥θlog(x)+(1−θ)log(y)
the above function is log-concave.
if α≤0,
log(θx+(1−θ)y)≤θlog(x)+(1−θ)log(y)
the above function is log-convex.
many common probability densities are log-concave (ex : normal dist)
f(x)=(2π)ndetΣ1e−21(x−xˉ)TΣ−1(x−xˉ)
💡
If we take logarithm for above function, it is just a quadratic function.
cumulative Gaussian distribution Φ is log-concave.
Φ(x)=2π1∫−∞xe−u2/2du
Properties
twice differentiable f with convex domain is log-concave if and only if
f(x)∇2f(x)⪯∇f(x)∇f(x)T
for all x∈dom f
or equivalently
∇2f(x)⪯f(x)∇f(x)∇f(x)T
for all x∈dom f
The condition for concave function is 0 for the right side of the above inequality. In log-concave case, the hessian matrix is less than equal to the rank-one matrix. That means we can have at most one positive eigenvalue of the hessian.
💡
For a rank-one matrix A=uvT, there is exactly one non-zero eigenvalue, and it is equal to the dot product uTv
product of log-concave functions is log-concave
💡
basically related to the sum of the concave function is concave.
sum of log-concave functions is not always log-concave
💡
mixture of log-concave distribution is not always log-concave

 https://en.wikipedia.org/wiki/Frobenius_inner_product
https://en.wikipedia.org/wiki/Frobenius_inner_product