Computer Science/Database
6. SQL
- -
728x90
반응형
Simple select

- attribute : specifies a column in the result
- table_reference : the name of the table
- where_condition : the condition that selected rows must satisfy
Example



Select Distinct
To remove duplicate rows from the result, we can use SELECT DISTINCT

Where Clause
Logical connections AND , OR , NOT can be used to create a more complex where condition

IS [NOT] NULL
- IS NULL
- IS NOT NULL
💡
NEVER use NULL nor <> NULL
Other Operations

Order by Clause
Order of rows in the result can be given by adding the ORDER BY CLAUSE

Example


💡
Default order is ascending (ASC)
Relational Product by an example


💡
We will use this when we want to join it
💡
It is just the printed result. Therefore, there is no effect on the original tables.
Joins
Inner Join
We want to show the ID, first name, last name, and department’s title for all employees.
Idea: DO the relational product and take only the rows where the employee’s department_id is equal to the department’s id

💡
foreign key를 이용해서 결합을 형성한다.
OR

Outer Join



Example

💡
기준을 어떻게 잡느냐에 따라서 LEFT JOIN과 RIGHT JOIN이 달라지는 것이라고 이해하면 된다.
Table alias
If an attribute’s name is unique, the table reference can be dropped

Tables can be referenced by using aliases:

💡
If a query joins a table with the same table, using aliases is the only way how to reference the tables

Create table

💡
예를 들어 Employee table을 생성할 때 SSN를 unique로 설정했기 때문에 중복된 데이터를 넣으려고 하면 에러를 출력한다.
💡
ID와 SSN 둘 다 unique하지만 ID를 primary key로 설정한 이유는 integer가 computational cost가 적기 때문이다.

💡
다음 예시처럼 composite primary key를 설정할 수 있다. 특히 many-to-many relation을 표현할 때 자주보게 될 것이다.

다음과 같은 예시를 참고해주면 된다.

추가적으로 primary key를 integer로 사용하는 편이 좋다. 이를 개선한 코드이다.
Reference options

Reference options
- Cascade : Deletes/update matching rows in the child tables too
- No action : Delete/update will fail if there are matching rows in the child tables
- Set null : Foreign key for matching rows in the child tables will be changed to NULL
INSERTING NEW DATA

💡
위에서 studnet 뒤에 column 이름을 명시하지 않아도 된다. 단, 그렇게 되면 모든 attribute를 다 포함해야한다
Deleting and Modifying data

Removing and Modifying relations

Set Operations - Union


Set Operations - Intersection

Set Operations - Except

💡
EXCEPT은 차집합이라고 생각해주면 된다. EXCEPT ALL의 경우에는 개수까지 고려하는 것이다.
Aggregate functions
Aggregate functions, e.g. count(), sum(), avg(), min(), max(), can be used to calculate summary statistics based on rows selected by a WHERE clause


Grouping
We can divide selected rows into groups based on the value of one or several attributes and calculate summary statistics in each group.


💡
attribute 값을 기준으로 grouping을 하고 그에 대한 statistics를 제공할 수 있게 된다.
Having clause

💡
Group에 condition을 거는 것이라고 생각해주면 된다.

💡
AS를 붙이는 이유는 출력되는 column name을 지정해주는 것이다.

Nested Queries
Suppose we want to find an employees have the lowest hour salary.

Actually, these approach works. However, we can use a nested query which returns one value instead of hardcoded like above.

Similarly, instead of a list of constants, we can use a nested query which returns several values

Correlated Nested queries
A nested query can also use attributes from the tables used in the main outer query. Such queries are called correlated or synchronized

Any and ALL


Exists
Exists


💡
IN 연산자와 거의 비슷하지만, IN 연산자는 비교할 값을 직접 대입할 수 있지만 EXISTS 연산자는 subquery만 사용할 수 있다.
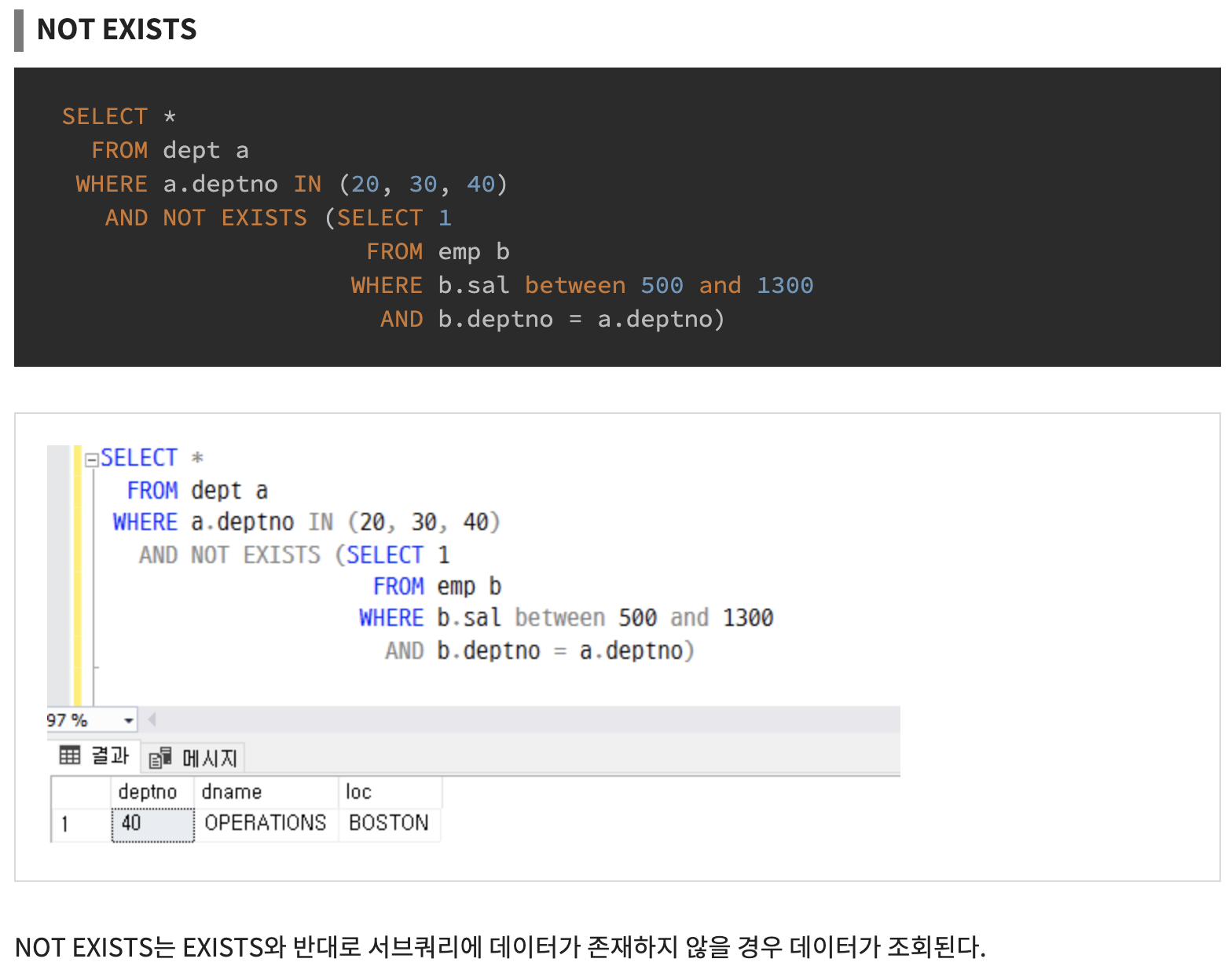
NOT EXISTS

Using the result of a nested query as a table

Views
A view is a named “virtual” table representing the result set of a given SELECT query.

The content of this virtual table is determined dynamically when such a query is executed
반응형
Contents
소중한 공감 감사합니다