Computer Science/Computer Network
9. Flow of the Network
- -
728x90
반응형
Application Layer
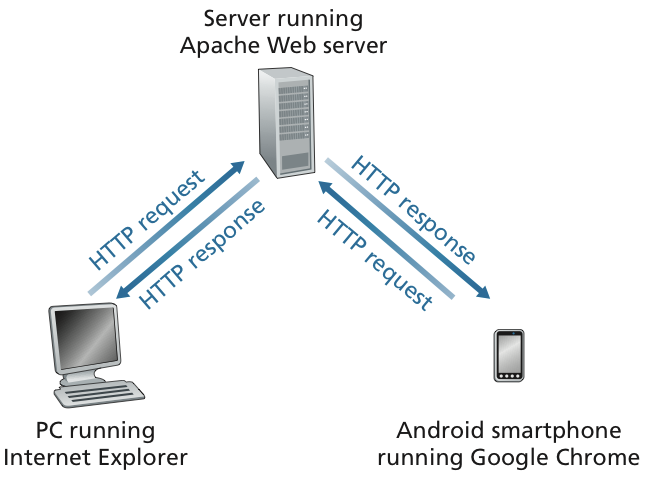
일반적으로 HTTP protocol 을 사용한다.
HTTP (HyperText Transfer Protocol)는 클라이언트(일반적으로 웹 브라우저)와 서버 간에 정보를 교환하는 방식을 정의한 프로토콜이다.
Web page에는 여러가지 object들이 존재한다. 특히 URL은 다음과 같이 구성된다.
hostnameof the server
- object’s path name
예를 들어
http://www.someschool.edu/someDepartment/picture.git 라는 URL이 있다고 했을 때
www.someschool.edu는 hostname이고, /someDepartment/picture.git는 object의 path name이다.
HTTP를 사용하여 전송할 수 있는 데이터 유형에는 다음과 같은 것들이 포함된다:
- HTML 문서: 웹 페이지의 구조와 내용을 정의한다.
- CSS 파일: 웹 페이지의 스타일과 레이아웃을 정의한다.
- JavaScript 파일: 웹 페이지에 대화형 기능을 추가하는데 사용된다.이미지, 비디오, 오디오 등의 멀티미디어 콘텐츠
- JSON 또는 XML과 같은 데이터 형식: 서버와 클라이언트 간에 데이터를 교환하는데 사용된다.
따라서 HTTP 프로토콜은 단순히 HTML 문서를 주고받는 것 이상으로, 웹 애플리케이션에서 필요한 모든 종류의 데이터를 전송하는 역할을 한다
💡
추가적으로 HTTP protocol은 기본적으로는 port 번호
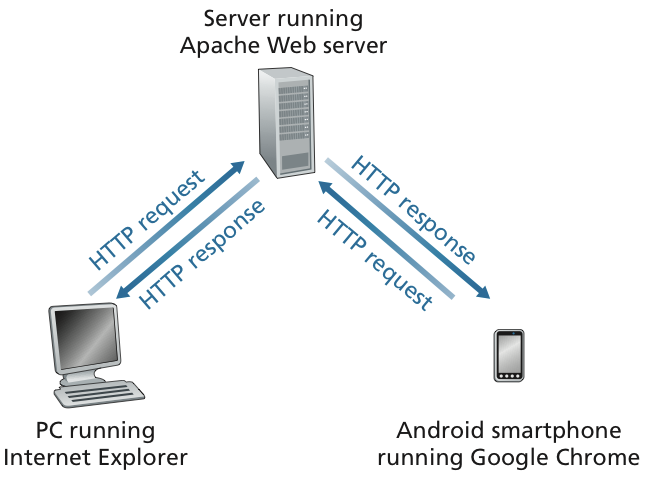
80 번을 사용한다.추가적으로 정확하게는 Web-client는 처음에 base HTML을 요구하고, 다른 사진이나 이런 파일들은 base HTML에 reference되어있는 것을 client가 읽고 추가적으로 요청하는 작업을 거치게 된다. 정확하게 살펴보면 다음과 같다.
- User가 base HTML을 request한다.
- 이 과정에서 browser는 해당 object에 대한 HTTP request를 보낸다
→ 이 과정에서 HTTP는
TCP protocol를 사용한다.💡물론 정확하게는 TCP protocol은 transport layer에 해당한다.→ 이 과정에서 handshaking이 수반되고, user와 server 사이에 TCP connection이 형성이 된다. 이를
3-way handshaking이라고 부른다.→ 더욱 정확하게는 Socket interface를 떠나는 순간 TCP protocol이 담당한다고 생각하면 된다.
💡이때, TCP는 reliable communication이므로 user가 보낸 HTTP request는 반드시 server에게 도착한다.
- server는 해당 base HTML을 server의 storage에서 찾아서 client에게 보내준다.
- client가 이 HTML 문서를 받으면, 그 내용을 분석하면서 추가적으로 필요한 리소스들 (예: 이미지 파일, CSS 파일, JavaScript 파일 등)의 위치와 이름을 찾습니다. 이 위치와 이름 정보는 HTML 문서 내의 태그들 (예:
<img>,<link>,<script>등)에 지정되어 있다.
- client는 그런 다음 각각의 추가 resource들에 대해 서버에게 별도의 HTTP 요청을 보낸다.
- client가 모든 필요한 resource들을 받으면, 그것들을 사용하여 최종적인 웹 페이지를 구성하고 화면에 표시합니다.
추가적으로 주목할만한 것은 HTTP protocol은 stateless라는 것이다. 즉 다시 말해서 client에 대한 정보를 기억하지 않는다. 예를 들어 동일한 client가 동일한 자료를 요구한 경우, web server는 해당 자료를 단순히 재전송한다.
💡
Web server는 항상 켜져있고, 고정 IP를 사용한다
이때 application developer는 중요한 결정을 내려야 한다. 각 request/response pair가 separate TCP connection 으로 보낼 것인지 아니면 same TCP connection 으로 보낼 것인지를 결정해야 한다. 전자는 non-persistent connection 방식이고, 후자는 persistent connection 방식이다.
각각에 대해 알아보면 다음과 같다.
- non-persistent connection : 이 방식에서는 각 HTTP 요청/응답 쌍에 대해 별도의 TCP 연결이 생성되고 종료된다. 즉, 클라이언트가 서버에게 HTTP 요청을 보내면 서버가 응답하고 그 후 해당 TCP 연결은 닫힌다
- persistent connection: 이 방식에서는 여러 HTTP 요청과 응답들이 동일한 TCP 연결 위로 전송된다. 클라이언트가 처음 서버에게 요청을 보낼 때 TCP연결이 생성되며, 그 후의 모든 요청과 응답들은 동일한 TCP연결을 재사용한다. 일정 시간동안 추가적인 데이터 교환이 없으면 해당 TCP연결은 자동으로 종료될 수 있다
non-persistent connection 은 구현하기 간편하지만, 매번 새로운 접속을 열기 때문에 network overhead가 크다는 단점이 있다. 반면 persistent connection은 한 번 열린 접속을 계속 재사용하기 때문에 network resource를 효율적으로 활용할 수 있다는 장점이 있다.
💡
Default는 persistent connection이다.
💡
추가적으로 non-persistent connection은 serial하게 진행하는 것이 아니라 parallel하게 진행할수도 있다. 특히 Browser가 동시에 여러 개의 TCP connection을 사용할 수도 있다.
도식화하면 다음과 같다.
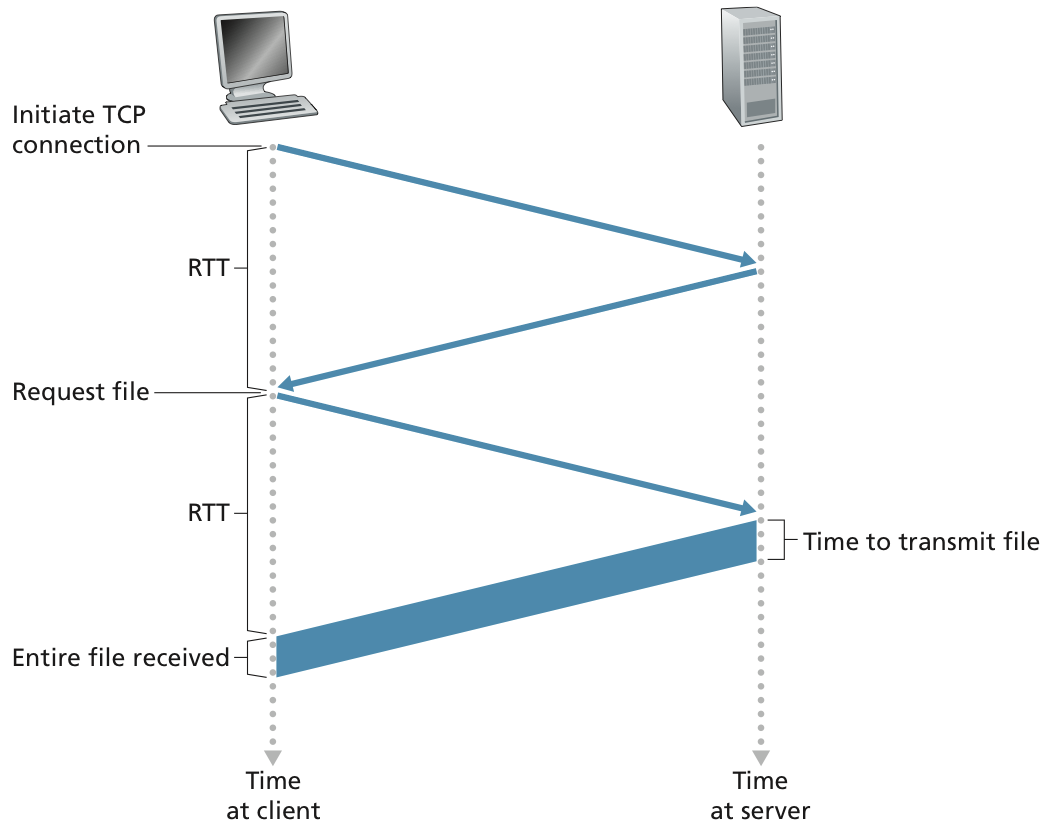
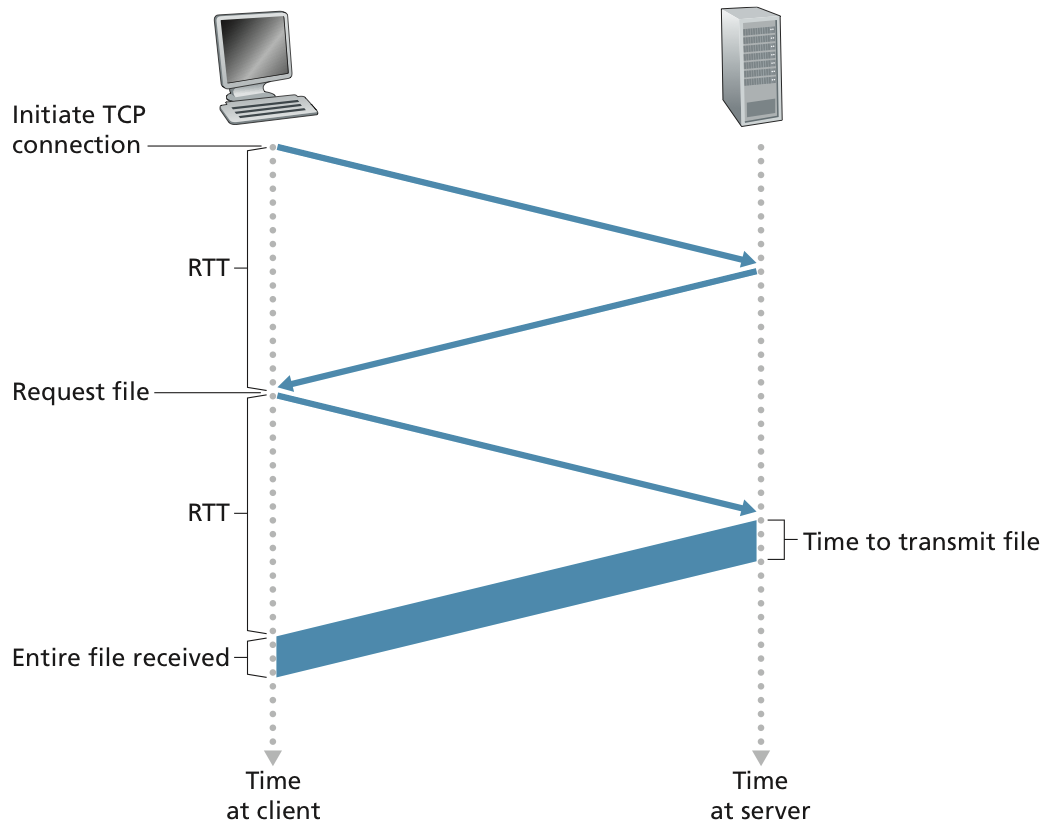
처음에는 TCP connection을 만들기 위해서 신호를 server에게 보내고, 이에 대한 승인을 받은 상황이다.
TCP connection이 형성된 이후 HTTP request를 보내고 해당 파일을 server에서 보내는 것이다.
주의할 점은 client가 HTTP request를 보낼 때 server에게 해당 TCP connection에 대한 ACK signal을 같이 보낸다는 것이다.
💡
TCP connection을 처음 형성할 때
tree-way handshake를 진행한다고 한다. 따라서 초기 TCP packet이 3개가 관여된다.💡
tranmission time와 propagation time을 잘 구분해서 봐두도록 하자.
그리고 만약 non-persisent connetion를 하게 되면 초기 Initial TCP connection을 설정하면서 발생하는 시간을 매번 HTTP request할 때마다 소비해야 한다. 반면 persistent connection을 하게 되면 최초 한번만 하면 된다는 점에서는 장점이지만, 상태를 기억해야한다는 점에서는 overhead가 크다.
DNS
Host를 identify하는 방법에는 2가지가 있다.
- hostname
- IP address
일반적으로 사람들은 hostname을 선호하지만, router의 경우에는 IP address를 선호한다.
이때문에 hostname을 IP address로 변환하는 작업이 필요하게 된다. 이러한 작업을 domain name system(DNS) 라고 한다.
이때, DNS 프로토콜은 UDP(User Datagram Protocol) 위에서 작동하며, port 53을 사용한다. UDP는 TCP와 달리 연결 지향적이지 않으므로 빠른 속도와 단순성을 제공하지만, 패킷 전달의 신뢰성은 보장하지 않는다.
간단히 과정은 다음과 같다.
- user의 컴퓨터에서 client side DNS application이 실행된다. 해당 application은 hostname을 IP address로 변환하는 역할을 한다
- Web browser는 URL에서 hostname(예: www.someschool.edu)을 추출하고, 이 호스트 이름을 client side DNS application에 전달한다.
- client side DNS application는 hostname을 포함하는 쿼리를 DNS server에 보낸다.
- client side DNS application는 결국 DNS server로 부터 응답을 받게 되며, 이 응답에는 hostname에 대한 IP 주소가 포함되어 있다.
- Browser가 DNS로부터 IP 주소를 받으면, 해당 IP 주소의
80번 포트에서 위치한 HTTP server process와 TCP 연결을 시작하게 된다.
추가적으로 TCP server는 distributed된다. centralized되면 다음과 같은 문제점이 있기 때문이다.
- A single point of failure : 1개밖에 없으면 그게 문제가 생길 경우 인터넷이 마비된다
- Traffic volume : 모든 request가 해당 server에 쏠리면서 overhead가 발생한다.
- Distant centralized database : 특정 host의 경우 거리가 멀어지게 된다는 문제가 발생한다. 이는 심각한 delay를 발생시킬 수 있음을 의미한다
- Maintenance : 해당하는 모든 정보를 다 가지고 있어야 하고, 추가적으로 업데이트되는 정보도 계속 업데이트 해야한다는 측면에서 unfeasible하다.
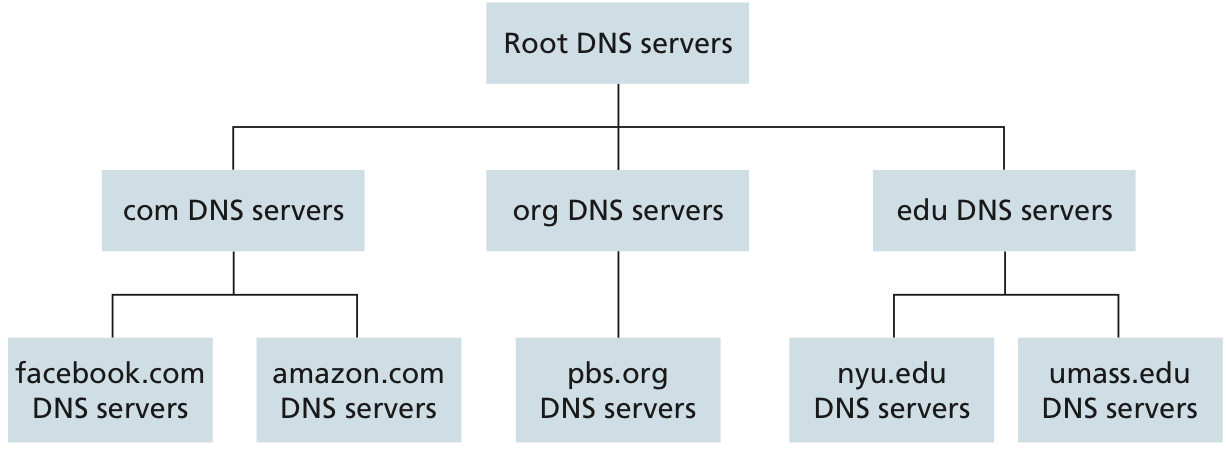
대략적으로 다음과 같은 hierarchy를 가진다.
구체적으로는 다음과 같다
- Root DNS server : TLD server의 IP 주소를 가지고 있다.
- Top-level domain (TLD) server : For each of the top-level domains such as com, org, net, edu, and all of the country top level domains such as uk, fr, ca.💡즉, domain별로 DNS server가 나누어져 있는 것이다.
- Authoritative DNS server : 특정 도메인에 대한 DNS 레코드를 갖고 있는, 그 도메인에 대해 "권한 있는" DNS 서버를 의미한다. 이 서버는 해당 도메인과 관련된 모든 DNS 정보를 알고 있으며, 이 정보는 보통 웹사이트의 소유자나 관리자에 의해 설정된다. 예를 들어, 'example.com'이라는 웹사이트가 있다면, 이 사이트의 authoritative DNS 서버는 'example.com' 및 그 하위 도메인 (예: 'www.example.com', 'mail.example.com') 에 대한 모든 정보를 가지고 있을 것이다.
추가적으로 Local DNS server 가 있다. 각 ISP 별로 Local DNS server가 있고, DNS를 하는 과정에서 가장 먼저 이 부분에 정보가 있는지를 체크한다.
하지만, 이러한 과정을 수행하는 과정에서 delay가 발생하게 된다. 이를 줄이기 위해서 가까운 DNS server에 해당 정보를 캐싱해둔다.
💡
추가적으로 hostname과 IP address는 항상 영구적인 것이 아니기 때문에 캐싱해둔 것도 주기적으로 초기화해주어야 한다. (일반적으로는 2일정도로 설정한다.)
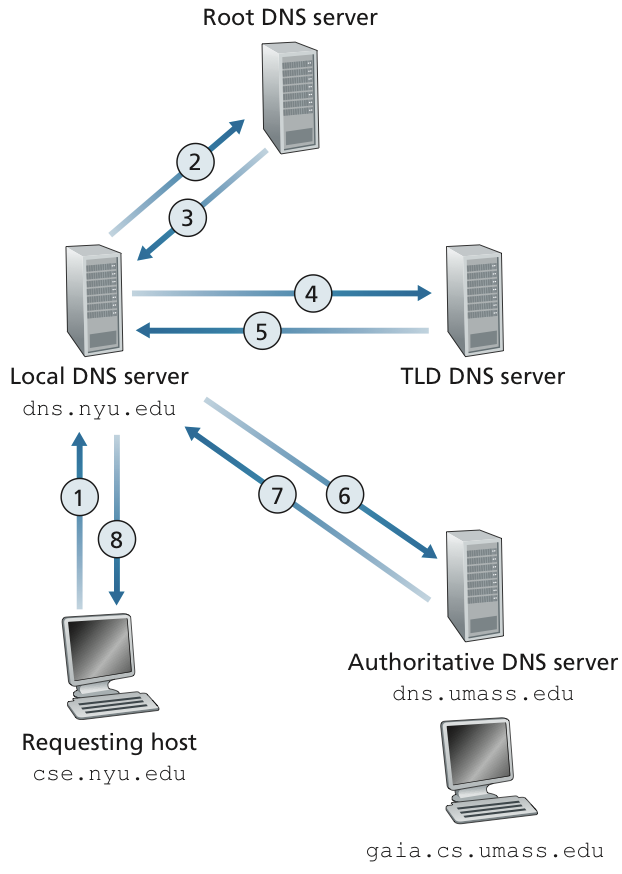
예를 들어, 사용자가 "www.example.com"이라는 웹사이트를 방문하려 할 때 다음과 같은 과정을 거친다
- 사용자의 컴퓨터가 local DNS 서버에 "www.example.com"의 IP 주소를 요청한다
- local DNS 서버가 이 정보를 가지고 있지 않다면 (즉 캐시에 없다면), root DNS 서버로 질의한다
- root DNS 서버는 ".com" TLD를 관리하는 TLD 서버의 IP 주소를 local DNS 서버에 반환한다
- root DNS서버는 받은 TLD서버로 질의하여 'example.com' 도메인을 관리하는 authoritative DNS server 의 주소 정보를 얻는다.
- 마지막으로 해당 도메인을 관리하는 authoritative DNS server에 'www.example.com' 의 실제 IP주소 정보를 얻어 사용자 컴퓨터에 반환한다

wireshark를 통해 직접적으로 알아보면 다음과 같다.
위의 상황은 www.genielab.net이라는 hostname의 IP주소를 알고 싶은 상황이고, 해당하는 IP 주소가 10.20.0.1라는 정보를 받은 상황이다.
TCP
TCP is said to be connection-oriented because one application process can begin to send data to another, the two processes must first handshake with each other.
주의할 점은 TCP protocol은 end system에서만 작동된다. 즉, intermediate network는 datagram만 확인하지 TCP connection과는 무관하다.
TCP connection이 형성되는 과정은 다음과 같다.
- Suppose a process running in one host wants to initiate a connection with another process in another host
- The client application process first informs the client transport layer that it wants to establish a connection to a process in the server.
- Then, TCP in the client then proceed to establish a TCP connection with TCP in the Server.
- The client sends a special TCP segment
- The server responds with a second special TCP segment
- Finally, the client responds again with a third special segment.
💡
4, 5에서 보내는 segment에는 payload가 없다. 즉 다시 말해서 application layer data가 없다는 의미이다. 4, 5, 6과정을
three-way handshake 이라고 부른다.- TCP connection is established. So two application process can send data to each other.
TCP segment의 구조를 알아보면 다음과 같다.
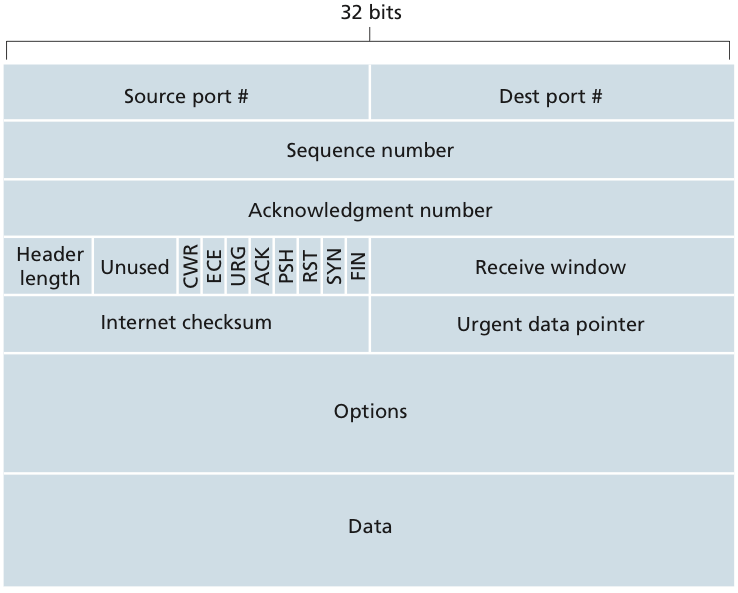
- Sequence number field (32bit) : 각 TCP segment가 어디서 시작되는지를 나타내는 번호이다. 이 number는 receiver가 보내는 첫 byte의 번호로 설정되고 이후의 segment들은 해당 segment에서 전송된 byte 수를 더한 값이 된다.💡sequence number가 필요한 이유는 기본적으로 packet들은 독립적으로 routing되기 때문이다. 따라서 TCP의 경우 sequence number를 사용하여 각 byte에 고유한 식별자를 부여함으로써 이 문제를 해결하고자 하는 것이다.
- Acknowledgement number field (32bit) : sender에게 다음에 받기 원하는 byte의 번호이다.
- Receive window (16bit) : Used for flow control💡수신 측이 자신이 받아들일 수 있는 데이터의 양, 즉 window size를 ACK packet에 담아서 sender에게 다시 보내게 된다. 즉 현재 buffer의 상태에 따라 해당 정보를 업데이트해서 이를 sender가 알 수 있게 한다.
- Header length field (4bit) : specifies the length of the TCP header in 32bit words. Since the TCP header can be variable length due to the TCP options field.
- Flag field
- ACK bit : used to indicate that the value carried in the acknowledgement field is valid.
→ 해당 packet이 ACK인지 여부를 담고 있는 flag이다.
- ACK bit : used to indicate that the value carried in the acknowledgement field is valid.
💡
receiver입장에서는 packet를 수신하고 Acknowledgement number를 수정하고 ACK bit를 1로 수정함으로서 해당 packet이 ACK임을 알 수 있게 한다. 또한 receive window field에 현재 수신자의 buffer상태가 어떤지에 대한 정보를 업데이트한다. 이후 수정된 packet을 sender에게 다시 보내게 된다.
Flow control
Receiver가 처리할 수 있는 것보다 더 많은 데이터를 sender가 보내지 않게끔 하는 것이다. 이를 위해서 receiver는 TCP header에 존재하는 receive window field를 업데이트 하고 ACK를 보냄으로써 sender가 알 수 있게끔 한다.
Congestion Control
Congestion control은 네트워크의 혼잡 상태를 관리하기 위한 mechanism이다. 만약 network가 과부화됨에 따라 packet loss가 감지되면 transmission rate를 줄여서 network의 혼잡 상태를 완화하려고 노력하게 된다.
크게 3단계로 구성된다. (cwnd : congestion window, ssthresh : slow start threshold)
- Slow start : cwnd를 1로 시작하고 cwnd를 2배씩 늘려나간다.
- Congestion Avoidance : cwnd가 ssthresh에 도달한 경우, 그 다음부터는 linear하게 cwnd를 증가시킨다.
- Fast recovery : 3개의 duplicate ACK가 도달했을 때 cwnd를 절반으로 줄이고, ssthresh또한 현재 cwnd의 절반으로 설정한다.
💡
만약 timeout이 발생한 경우에는 slow start 단계로 다시 돌아가게 된다.
💡
ssthresh는 timeout이 발생했거나, 3개의 duplicate ACK가 도달했을 때 현재 cwnd의 절반으로 설정한다.
💡
Workshop Exercise 2번 풀어보면서 참고할 것
ARP
ARP protocol은 IP address와 MAC address 사이의 translation을 담당하고 있다.
주의할 점은 MAC broadcast address를 사용한다는 점이다.
💡
IP broadcast address를 사용하지 않는 이유 중 하나는 네트워크 계층까지 올라가야 하므로 처리 과정이 복잡해지고, 이는 추가적인 시간과 리소스가 들기 때문이다. 또한 IP broadcast address를 사용한 packet은 일반적으로 라우터에 의해 차단되거나 제한되므로, 같은 로컬 네트워크 내의 모든 장치들에 도달하지 못할 수도 있다. 따라서 ARP와 같이 linked layer protocol의 경우, MAC broadcast address를 사용하여 효율성을 최적하게 된다.
→ 쉽게 말해서 IP address에서도 해당 subnet에 속한 host에게 broadcast하는 방법이 존재하지만 network layer에 해당하기 때문에 MAC broadcast address를 사용하는 것이 훨씬 타당하다.

추가적으로 ARP table의 entry는 TTL (Time to Live)이라는 값을 가지고 있는데, 해당 시점에 해당 ARP table의 entry는 삭제된다.
ARP의 과정은 다음과 같다.
- datagram을 보내려고 하는 destination의 MAC 주소를 ARP cache에서 찾는다.
- 만약 ARP cache에 해당 값이 존재한다면 해당 값을 link layer의 destination MAC address에 쓰고 frame을 link로 내보낸다.
- 만약 존재하지 않는다면
ARP packet를 보낸다. 이때MAC broadcast address를 사용하게 된다. (즉 같은 LAN상에 존재하는 모든 host에게 broadcast하게 된다.)
- 그리고 대응되는 host에서 자신의 MAC address를 보내준다.
- 이후 해당 값을 link layer의 destination MAC address에 쓰고 frame을 link로 내보내게 된다.
TCP와 UDP를 구분하는 방법
transport protocol의 번호는 IP (Internet Protocol) header 내에서 해당 패킷이 사용하는 전송 계층 프로토콜을 식별하는 데 사용된다. 이것은 protocol field라고도 불리며, 각 전송 프로토콜에 대해 고유한 숫자를 할당한다.
💡
잘 생각해보면 network layer가 transport layer보다 바깥쪽에 위치해있기 때문에 해당 정보를 미리 알아야 어떤 방식으로 transport layer를 해석할 지에 대한 기준을 제공할 수 있다.
TCP (Transmission Control Protocol)와 UDP (User Datagram Protocol), 두 가지 가장 일반적인 전송 프로토콜의 경우, 각각 다음과 같은 프로토콜 번호가 할당되어 있다:
- TCP: 6
- UDP: 17
따라서 IP 헤더의 "Protocol" 필드에 6이 포함되어 있다면 해당 패킷은 TCP를 사용하고 있음을 의미하며, 17이 포함되어 있다면 UDP를 사용하고 있음을 의미한다. 이렇게 하여 네트워크 스택은 패킷을 올바르게 처리할 수 있는 방법을 알 수 있다.
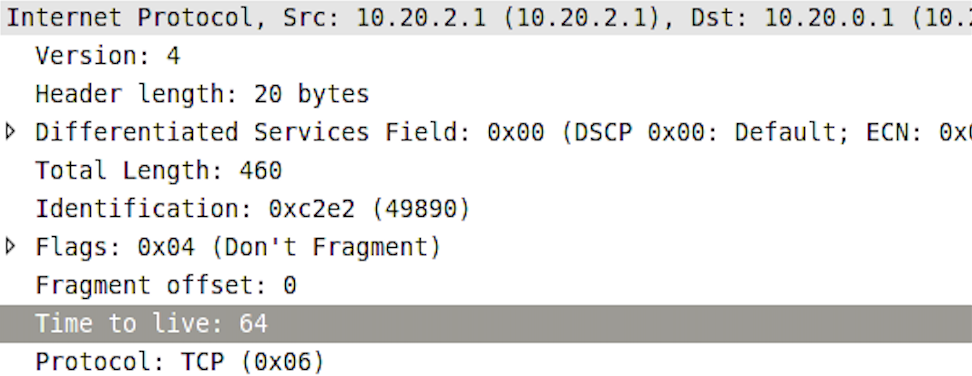
실제로 wireshark에서 확인해보면 다음과 같은 결과를 확인할 수 있다.
IPv4
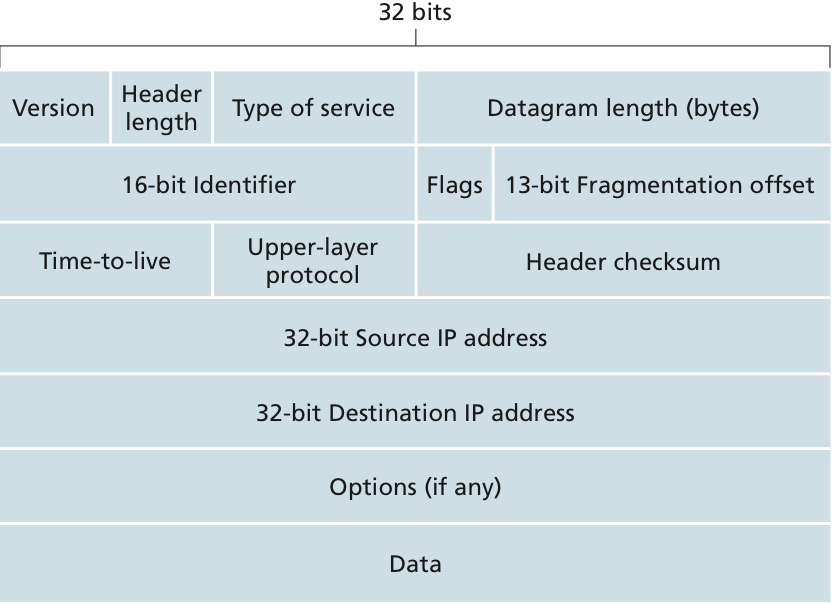
- Version (4bits) : 사용하고 있는 datagram의 version이 어떻게 되는지에 대한 정보를 담고 있다. 이를 통해 IPv4인지 IPv6인지 판단할 수 있게 된다.
- Header length (4bits) : IPv4 header의 크기는
Option field에 의해서 변동될 수 있으므로 header의 크기가 어떻게 되는지에 대한 정보를 여기에다가 담는다.
- Type of service : TOS 필드는 원래 서비스 품질(Quality of Service, QoS)을 제공하기 위해 설계되었다. TOS 필드는 다음과 같은 서브필드로 구성된다:
- Precedence (3 bits): 패킷의 중요도를 나타내며, 값이 높을수록 우선 순위가 높아진다.
- Delay (1 bit): 낮은 지연을 요구하는 패킷인 경우 설정된다.
- Throughput (1 bit): 높은 처리량을 요구하는 패킷인 경우 설정된다.Reliability (1 bit): 높은 신뢰성을 요구하는 패킷인 경우 설정된다.
- Cost (1 bit): 낮은 비용을 요구하는 패킷인 경우 설정된다.
나머지 2비트는 예약되어 있다.
- Datagram length : IP datagram의 전체 크기를
byte단위로 저장한다. (즉, IP header와 IP payload의 크기를 더한 값이 저장되는 것이다.)
- Identifier, flags, fragmentation offset : 기본적으로 위 field는
IP fragmentation에서 사용된다.
- Identifier (16 bits): 이 필드는 원래 데이터그램의 식별자를 나타낸다. 데이터그램이 분할될 경우, 각각의 조각(fragment)은 원래 데이터그램과 동일한 식별자를 가진다. 이를 통해 수신 시스템은 어떤 조각들이 같은 원래 데이터그램으로부터 왔는지 알 수 있다.
- flags (3 bits) : 이 중 첫 번째 비트는 항상 0으로 설정되며, 두 번째 비트는 "Don't Fragment(DF)" 플래그로서 설정되면 해당 패킷이 분할되지 않아야 함을 나타낸다. 세 번째 비트는
"More Fragments(MF)"플래그로서 다른 조각들이 뒤따라 올 것임을 나타낸다.
- Fragmentation offset : 이 필드는 원본 데이터그램 내에서 현재 조각의 위치를 나타내며,
8바이트 단위로 측정된다. 이 정보를 사용하여 수신 시스템은 모든 조각들을 올바른 순서대로 재조립 할 수 있다.
💡즉 IP fragmentation이 발생하면 IP datagram header는 싸드리 다 복사되고, payload 부분이 나눠지게 된다.
- Time-to-live : 이 field를 통해 datagrams이 영원히 circulate하는 것을 막게 된다. 해당 field는 router를 한번 거칠때마다 1씩 줄어들게 되고 0에 도달하면 해당 datagram을 버리게 된다.
- Protocol : 위 field는 IP datagram이 final destination에 도착했을 때만 사용되며, transport layer의 protocol이 무엇인지에 대한 정보를 담고 있다.💡위 field를 통해 network layer와 transport layer가 연결되는 것이다.
- Header checksum : 위 정보를 통해 router가 수신한 IP datagram에 bit error가 있는지 여부를 확인할 수 있게 된다.

checksum 계산방법은 다음과 같다.
- header를 2byte (16bit) 단위로 쪼개서 모두 다 더한다.
- 만약 overflow가 발생한 경우, 해당 값을 앞으로 가져와서 더한다
- 1’s complement를 취한다
- 3의 결과를 checksum field에 채운다.
💡송신자가 보내기 전에 header checksum을 계산하고, 수신자가 도착한 datagram에 대해서 checksum을 다시 계산하기 때문에 해당 값이 같으면 bit error가 없다고간주하는 것이다. (왜냐하면 가능성이 낮기는 하지만 bit가 바뀌어도 checksum이 같을 수는 있다.)💡추가적으로 IPv4의 경우 Time-to-Live field때문에 check sum을 계속 보낼때마다 다시 계산해서 수정해야한다는 단점이 있다. 자세한 내용은 아래 IPv6쪽을 참고하도록 하자.💡추가적으로 IP datagram의 header부분만 고려한 것이므로 payload 부분에 대해서는 장담할 수 없다. 따라서 transport layer header에도 checksum field가 있는 것이다.
- Source and destination IP addresses : 출발지와 도착지의 IP address이다.💡비유하자면 실제 택배 택에 붙어있는 보내는 사람 주소와 받는 사람 주소이다. 해당 정보는 router에서 변동되지 않는다. (물론 Ethernet protocol에 존재하는 MAC address는 router를 타고감에 따라 변동된다.)
- Options : 해당 field를 통해 IP header가 extended될 수 있으나 잘 사용되지 않음
payload가 무엇을 말하는가?
페이로드(payload)는 전송되는 데이터의 실질적인 부분을 의미한다. 즉 header를 제외한 부분을 의미한다. 예를 들어 datagram의 payload는 segment이다. (즉, transport layer의 header를 포함한다.)
MTU가 무엇인가?
The length of the largest link-layer frame that can be sent by the local sending host
💡
주의할 점은 IP address는 host별로 할당되는 것이 아니라
interface 단위로 할당된다. 즉 다시 말해서 router의 경우 여러 interface가 존재하기 때문에 각 interface마다 고유한 IP 주소가 할당된다. (당연히 각 interface는 고유한 MAC주소를 가진다.)IPv6
IPv4에서 IPv6로 넘어가려고 한 가장 큰 동기는 32 bit으로 구성된 IP address가 현재 입장에서는 충분하지 않다는 것이다.
IPv4에서 변경된 점은 다음과 같다.
- Expanded addressing capabilities :
128bit를 사용함으로써 기존 32bit 주소 표현방식이 가지는 단점을 극복하려고 노력하였다.
- Fixed 40byte header : IPv4에서는 header의 크기가 변동될 수 있었던 것과 달리 IPv6에서는 40byte로 고정이다.

- Version (4bits) : 사용하고 있는 datagram의 version이 어떻게 되는지에 대한 정보를 담고 있다. 이를 통해 IPv4인지 IPv6인지 판단할 수 있게 된다.
- Traffic class (8bits) : IPv4에서 Type of Service field와 유사하다. 해당 field를 사용해서 해당 datagram의 priority를 부여하는 식으로 사용할 수 있다.
- Flow label (20bits) : 이 필드는 packet이 속한 flow를 식별하는 데 사용되며, 특정 플로우에 속한 패킷들은 네트워크 내에서 동일한 방식으로 처리되어야 함을 나타낸다. flow라는 것은 일련의 packet들을 의미하며, 이들 packet은 모두 같은 출발지와 목적지 주소를 가지고 있고, 동일한 우선 순위를 가집니다. 또한, 이들은 같은 경로를 따라 네트워크를 통과하거나 비슷한 서비스 수준(Quality of Service, QoS)을 받아야 한다.
- Payload length (16bits) : header 다음에 나오는 payload의 크기를
byte단위로 나타낸 것이다.
- Next header : 위 field는 IP datagram이 final destination에 도착했을 때만 사용되며, transport layer의 protocol이 무엇인지에 대한 정보를 담고 있다. IPv4에서
protocol field와 동일하다.
- Hop limit : 이 field를 통해 datagrams이 영원히 circulate하는 것을 막게 된다. 해당 field는 router를 한번 거칠때마다 1씩 줄어들게 되고 0에 도달하면 해당 datagram을 버리게 된다. IPv4에서
Time to limit과 동일하다.
- Source and destination address : IPv4와 의미는 동일하지만 기존 32 bit에서 128bit로 변경되었다는 차이가 있다.
이때 IPv4에서 사라진 field들도 존재하는데 이는 다음과 같다.
- Fragmentation/reassembly : IPv6는 router에서 fragmentation을 허용하지 않기 때문에 없어졌다. 만약 datagram의 크기가 전송할 수 있는 MTU보다 큰 경우에는 해당 datagram을 없애고 재전송요청을 한다.
- Header checksum : Transport layer와 link layer에서 checksum을 통해 error를 찾는 과정을 이미 수행하고 있기 때문에 redundant하다고 판단해서 삭제. 기존의 IPv4에서는 Time-to-Live가 1 hop을 뛸 때 마다 변동되기 때문에 지속적으로 계속 checksum을 update해야하는데 이게 overhead가 상당히 크다.
- Options
IPv4 to IPv6
IPv4 기반으로 설계된 것들을 어떻게 IPv6과 호환될 수 있게끔 할 것인가?
이를 해결하기 위해 tunneling 기법이 사용되었다.
자세한 내용은 다음 링크를 참고하도록 하자.
그렇다면 IPv4에서 IPv6로 전환되는 과정에서 문제가 없을까? 더욱이 IPv4를 IPv6가 호환한다고해도, 이미 배포된 IPv4 시스템들은 IPv6 datagram을 처리할 수 없다는 지점이 문제가 될 수 있다.
이를 해결하기 위해 현재 대부분 채택하고 있는 방식은 tunneling 이다. 이 방식은 IPv6 패킷을 IPv4 네트워크를 통해 전송할 수 있게 해준다. 송신측에서는 원본 전체 IPv6 packet을 새로운 IPv4 packet의 data field(payload)에 넣어서 encapsulation하고, 이 encapsulation된 IPv4 packet을 네트워크를 통해 전송한다. 수신층에서는 이렇게 도착한 IPv4 packet으로부터 원래의 IPv6 packet을 decapsulation 하여 처리한다.
💡
즉, IPv6 datagram
전체가 IPv4의 data field (payload)로 취급해서 전송하는 것이다. 즉 IPv6의 header파일까지 전부 IPv4의 payload안에 들어가 있다.💡
이때 중간에 있는 노드들은 현재 자신들이 처리하고 있는 IPv4 datagram이 IPv6 datagram을 포함하고 있다는 사실을 모르고 있다.
💡
단, 주의할 점은 도착지가
tunnel의 끝 으로 변경된다는 점을 주의해야 한다. (사이에 있는 destination이 E 로 바뀐 것을 잘 봐주면 된다.) 즉 다시 말해서 중간에 있는 IPv4의 header에 있는 destination IP address는 터널의 끝에 해당하는 IP address로 변경된다. 주의할 지점은 IPv6 header에 존재하는 destination IP address는 그대로 유지되므로 원래 목적지에 대한 정보는 유지할 수 있다는 점이다.도착지 기준으로 IPv6 datagram이 data field에 포함되어있는지 여부를 체크해주면 된다.
Question : where is the TCP header? Where would a link layer header be?
- TCP header는 transport layer에 추가되는 것이다. 따라서 IPv6를 IPv4로 encapsulation하는 경우, TCP header는 IPv6 datagram의 일부인 payload 안에 존재하게 된다.
- Link header는 전체 datagram을 감싼다. (왜냐하면 Link layer가 Network layer보다 더 하위 layer이기 때문이다.)
IPv4와 IPv6를 구분하는 방법
전체적인 흐름은 TCP와 UDP에서 판단했던 것과 거의 유사하다.
Pv4나 IPv6를 사용하는지에 대한 정보는 일반적으로 데이터 링크 계층 (Link Layer)의 헤더에 포함되어 있다. 이것은 네트워크 장비가 패킷을 올바르게 처리하고, 해당 패킷이 어떤 프로토콜을 사용하는지 알 수 있도록 해준다.
예를 들어, 이더넷 (Ethernet) frame의 header에는 Type 또는 EtherType 필드가 있습니다. 이 필드는 상위 계층인 네트워크 계층의 프로토콜 타입을 나타낸다. EtherType 값이 0x0800이면 IPv4를, 0x86DD면 IPv6를 사용한다는 것을 의미한다.
따라서 link layer에서 packet을 받았을 때 해당 필드를 확인하면 그 위의 네트워크 계층에서 어떤 IP 버전이 사용되었는지 알 수 있다.
💡
IP protocol의 Header에 version field에도 해당 정보가 존재하기는 한다. Version field는 사용 중인 IP 버전을 나타낸다. 이 Version 필드가 어떤 값을 가지느냐에 따라 packet의 구조와 처리 방식이 달라지게 된다.
그러면 왜 Ethernet frame header에도 있고 IP datagram header에도 해당 정보가 존재하는걸까? 하나만 있으면 안되냐?
Ethernet frame header에 잇는 type 혹은 EtherType은 단순히 IPv4 또는 IPv6만을 구분하는 것이 아니라 ARP, VLAN 등과 같은 다양한 프로토콜들을 구분하는데 사용된다. 따라서 두 정보 모두 다 필요하다.
DHCP
ISP는 인터넷에 연결된 모든 장치에 대해 고유한 IP 주소를 할당할 책임이 있다. ISP는 자신이 관리하는 IP 주소 블록을 여러 고객(조직)에게 분배한다.
그런 다음 각 조직 내에서는 네트워크 관리자가 이러한 IP 주소를 추가로 분배할 수 있다. 이때 DHCP (Dynamic Host Configuration Protocol)가 사용된다.
DHCP는 네트워크에 연결된 컴퓨터나 기타 장치들에게 동적으로 IP 주소와 기타 네트워크 설정을 제공하는 프로토콜이다. DHCP 서버는 특정 IP 주소 범위를 가지고 있으며, 요청이 들어올 때마다 해당 범위에서 사용 가능한 IP 주소를 장치에 할당한다.
따라서 요약하면, ISP가 처음에 큰 블록의 IP 주소를 조직에 제공하고, 그런 다음 조직 내의 DHCP 서버가 이러한 주소를 개별 장치들에게 분배하는 것입니다.
추가적으로 다음과 같은 정보를 추가적으로 제공한다.
- 할당된 IP address
- subnetmask
- default gateway
- address of its local DNS server
추가적으로 DHCP는 기본적으로 server에서 일어나지만 router 도 DHCP 기능을 내장할 수 있다.
DHCP procedure
DHCP protocol은 다음과 같은 4단계의 step으로 구성된다.
- DHCP server discovery : host 입장에서 맨 처음으로 해야할 일은 DHCP server를 찾는 일이다. 이를 찾기 위해서
DHCP discover message를 보낸다. 이를 위해서UDP packet를 port67번으로 보낸다.→ 문제는 현재 자신이 어떤 subnetwork에 속해있는지 알지 못하고, DHCP server의 주소 또한 알지 못한다는 것이다. 그래서
broadcast address를 사용한다. 이는 255.255.255.255이다. 추가적으로 host의 source IP address는 0.0.0.0으로 설정한다.💡단, 주의해야할 점이 subnetwork에서 host의 수를 구할 때 언급했던 broadcast와는 별개이다. 255.255.255.255는 네트워크 상의 모든 기기에 패킷을 보내는 데 사용되고, 특정 subnet의 broadcast 주소는해당 subnet에 속한 host에게 packet을 보내는데 사용된다.💡MAC broadcast address가 아니라IP broadcast address를 사용한다는 점을 주의해야 한다.💡만약 prefix가 255.255.255/24라고 가정하면 서로 다른 2개의 broadcast의 목적이 겹치는 것이 아닌가라고 생각할 수 있지만, 사용되는 상황과 목적이 다르기 때문에 실질적으로 구분할 수 있다.
- DHCP server offer : DHCP server가 DHCP discover message를 수신하고 이에 대한 응답으로 해당 host에게
DHCP offer message를 보낸다. 단, 마찬가지로 이 message의 receiver의 IP는 255.255.255.255이다. 즉 broadcast시킨다. 추가적으로 도착자의 port는68로 설정한다. (일종의 약속이다.)💡잘 생각해보면 DHCP server입장에서도 도착지의 IP주소를 모르는 상황이므로 broadcast밖에 답이 없다.이때 network 상에는 여러 개의 DHCP server가 존재하므로, 여러 DHCP server offer를 받게 되고 이들 중 적절한 것을 선택해야 한다.
DHCP offer message에는 다음과 같은 정보들이 포함되어 있다.
- Transaction ID : Client와 server 사이의 DHCP message 교환을 추적하는데 사용된다. host가 DHCP Discover message를 보낼 때 해당 message에는 고유한 Transaction ID가 포함되는데, 이에 대한 DHCP offer message도 동일한 Transaction ID가 포함된다. 이를 통해 자신이 보낸 요청에 대한 답이라는 것을 알 수 있다.
- Proposed IP address
- Network mask
- IP address lease time : 얼마나 IP address를 유지시킬 것인가에 대한 정보이다. 일반적으로는 수 시간에서 몇 일 정도이다.
- DHCP request : 여러 DHCP offer 중 하나를 host가 선택하고 이에 대한 응답을 보낸다. 이를
DHCP request message라고 부른다. 해당 message에는 DHCP server가 제안한 parameter (Transaction ID, Proposed IP address, etc) 가 포함된다.
- DHCP ACK : DHCP request를 DHCP server가 수신한 이후, 해당 parameter에 대한 승인을 의미하는
DHCP ACK message를 보냄으로써 DHCP protocol이 종료된다.
💡
host가 DHCP ACK를 수신한 이후로는 DHCP server로부터 할당받은 IP주소와 subnet mask를 lease 기간동안 사용하면 된다.
Link layer
A Link layer address is variously called a LAN address , a physical address , or a MAC address
대표적인 protocol로 Ethernet과 Wi-Fi가 있다.
- Ethernet: Ethernet은 주로
유선 네트워크에서 사용되며, 장치 간에 데이터를 프레임 단위로 전송한다. Ethernet은CSMA/CD(Carrier Sense Multiple Access with Collision Detection)라는 방법을 사용하여 네트워크 상의 충돌을 관리하였습니다.
- Wi-Fi: Wi-Fi는 무선 네트워크를 위한 프로토콜이다. Wi-Fi도 이더넷과 마찬가지로 데이터를 프레임 단위로 전송하지만, 무선 통신의 특성상 충돌 감지가 어렵기 때문에
CSMA/CA(Carrier Sense Multiple Access with Collision Avoidance)라는 방법을 사용하여 충돌을 최소화한다.
이들 프로토콜 모두 MAC(Media Access Control) 주소라는 고유한 식별자를 사용하여 송수신 장치를 구분하며, 상위 계층에서 오는 데이터(예: IP 패킷)를 encapsulate하여 실제 전송하는 역할을 한다.
그 외에도 PPP(Point-to-Point Protocol), HDLC(High-Level Data Link Control), ATM(Asynchronous Transfer Mode), Frame Relay 등 다양한 링크 계층 프로토콜이 있다.
MAC Address
It’s important to note, however, that link-layer switches do not have link-layer addresses associated with their interfaces that connect to hosts and routers. This is because the job of the link-layer switch is to carry datagrams between hosts and routers; a switch does this job transparently, that is, without the host or router having to explicitly address the frame to the intervening switch.
💡
즉, host와 router의 경우 각 interface 별로 IP address 및 MAC address를 가지지만 switch의 경우에는 MAC address 및 IP address를 가지지 않는다. 따라서 link layer에서 packet 전송은 end to end 방식으로 처리되는 것이다. switch는 단지 이 과정을 통과하는 packet를 적절한 방향으로 전달하는 역할만 수행하는 것이다.
추가적으로 IP address와의 차이점을 기억해야 한다. host가 움직이는 경우 IP address는 변동될 수 있지만, MAC address는 일정하다.
주의할 점은 MAC address에도 broadcast address 가 존재한다는 점이다.
→ FF:FF:FF:FF:FF:FF 이 broadcast address이다.
이때, ARP와 DHCP는 이용하는 broadcast가 다르다는 점을 굉장히 주의해야 한다.
ARP : MAC broadcast address이용
💡
반드시 같은 subnetwork 상에 존재한다는 것이 확실할 경우에는 MAC broadcast address를 사용하는 것이 낫다. 이때 ARP를 쓰는 상황은 반드시 destination address가 동일한 local network에 있다는 것을 담보할 수 있으므로 MAC broadcast address를 이용하는 것이다.
DHCP : IP broadcast address이용
💡
MAC 주소 기반의 통신은 같은 LAN(Local Area Network) 내에서만 가능하다. 반면에 DHCP 요청을 처리하는 서버가
로컬 네트워크 바깥에 있을 수도 있다(예: 중앙화된 데이터 센터). 이 경우, 해당 요청은 여러 라우터와 스위치 등을 통해 전달되어야 한다. 따라서 DHCP는 IP 기반 broadcast address를 사용한다.Ethernet

- Destination address (6bytes) : 도착지에 해당하는 MAC address
- Source address (6bytes) : 출발지에 해당하는 MAC address
- Type field (2bytes) : Network layer에서 어떤 protocol을 쓰고 있는지에 대한 정보를 담고 있다. 이 field 정보를 통해서 IPv4인지, IPv6인지에 대한 정보를 알 수 있다. (물론 다른 protocol을 쓰고 있는 경우도 판단할 수 있게 된다.)
- CRC (Cyclic redundancy check) field (4bytes) : frame에 bit error가 있는지 체크하는 목적
- Preamble (8bytes) : network device들이 비트 동기화를 수행하는 데 도움을 준다. 비트 동기화란, 데이터를 전송하고 수신하는 장치 간에 클럭 속도를 맞추는 과정이다. 즉, Preamble은 Ethernet 장치가 frame의 시작 시점을 정확히 인식하고 data stream에서 개별 비트를 올바르게 읽을 수 있도록 돕는다.
💡
추가적으로 Ethernet는
unreliable 하다. 즉 CRC를 통해 bit error를 체크하고는 있지만, TCP 처럼 수신 여부나 문제가 있다는 정보를 송신자에게 보내지 않고 단순히 오류가 있으면 버린다. 따라서 재전송 메커니즘이나 오류 복구 같은 기능은 상위 layer에서 처리해야 한다. TCP의 경우에는 ACK signal을 통해서 알 수 있고, UDP의 경우에는 도착한 data를 보고 알 수 있다.Switch
Switch의 역할은 단순히 도달한 link layer frame을 outgoing link로 forwarding해주는 것이다. 앞서 언급한 것처럼 Switch는 IP address나 MAC address가 없기 때문에 sender나 receiver가 그 존재에 대해서 알지 않아도 전송할 수 있다. 이러한 기능은 Filtering 과 Forwarding 으로 제공되는데, Filtering은 어떠한 interface로 frame이 나가야되는지 결정하거나 해당 frame을 버리는 기능을 수행한다. 반면 Forwarding은 Filtering에서 결정된 interface로 해당 frame을 이동시키는 역할을 수행한다.
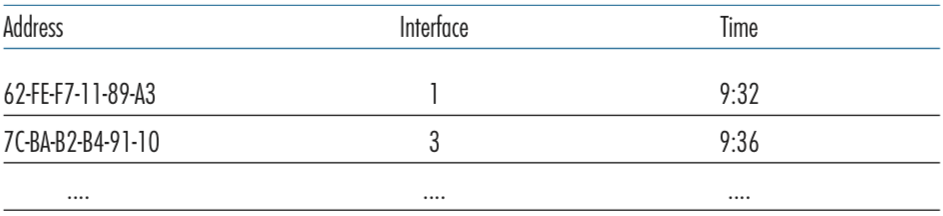
이러한 정보는 switch table 에서 확인할 수 있다.
다음과 같은 경우를 생각해보자. interface x로 destination MAC address가 DD:DD:DD:DD:DD:DD 인 frame이 들어왔다고 가정하자.
- 해당 MAC address가 switch table에 존재하지 않는 경우 : 들어온 x를 제외한 모든 interface의 output buffer에 해당 내용을 복사하고 모든 interface를 통해 해당 ㅈ어보를 전송한다.
- 해당 MAC address가 switch table에 존재하는 경우
- Interface field에 x가 적혀있는 경우 : 이미 거기서 온 상황이므로 해당 frame을 버린다.
- Interface field에 x가 아닌 다른 것이 적혀있는 경우 : forwarding function을 통해 interface y로 frame을 보낸다.
Switches Versus Routers
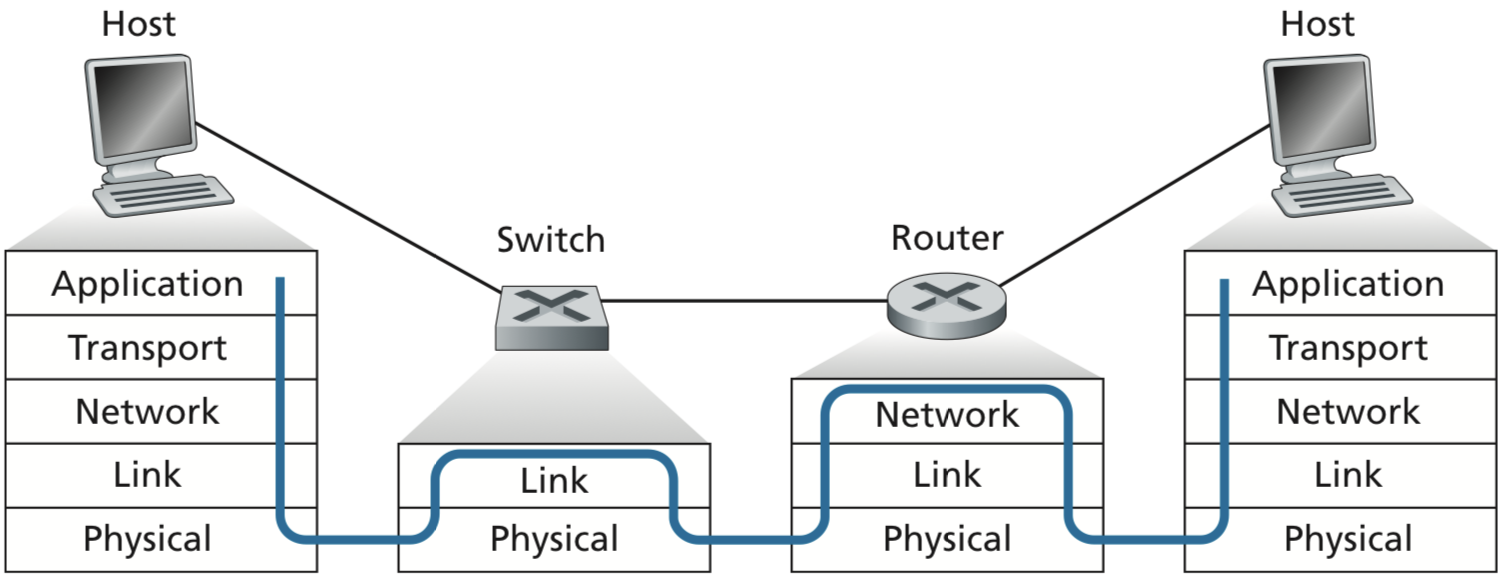
기본적으로 router와 switch는 packet를 store하고 forward한다는 측면에서는 공통점을 가지지만 switch는 MAC address 를 이용해서 forwarding한다는 점에서 큰 차이를 보인다. (Router는 기본적으로 IP address 를 사용해서 forwarding한다.)
Conclusion
- TCP를 사용하는 경우에는 TCP connection을 형성할 때 아래 과정이 진행된다고 생각해주면 된다. 해당 과정을 어차피 한번 거치면 ARP cache에 IP address와 MAC 사이의 대응관계가 저장된다.
- sender가 destination의 IP 주소를 기반으로 같은 subnetwork에 있는지를 검사한다.

- 동일한 subnetwork상에 존재
→ ARP cache에 해당 IP주소에 대한 MAC address가 존재하는지를 검사한다.
→ 없는 경우 ARP broadcasting을 통해 destination의 MAC 주소를 확보한다.
- 동일한 subnetwork상에 존재하지 않는 경우

→ forwarding table을 확인한다. 해당 정보가 적혀있는 경우 대응되는 gateway의 IP주소를 확보하고, 없는 경우 default gateway의 IP 주소를 확보한다.
→ 해당 gateway의 IP 주소에 대한 MAC address가 ARP cache에 존재하는지 검사하고

→ 없는 경우 ARP broadcasting을 통해 해당 gateway의 MAC 주소를 확보한다.
- 동일한 subnetwork상에 존재
- MAC 주소를 기반으로 해당 Frame을 전송한다.
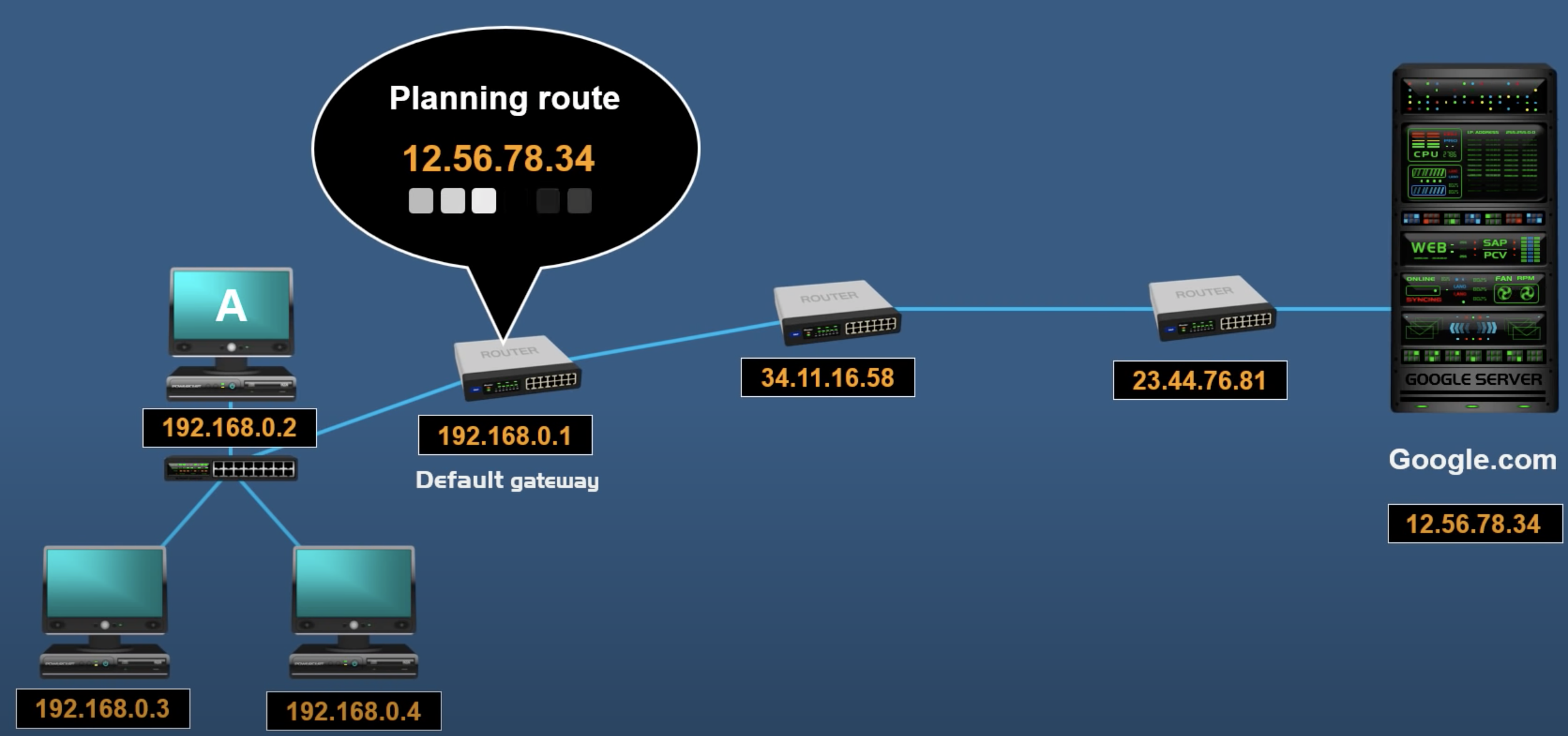
- 도착한 곳을 기준으로 destination IP주소와 같은 subnetwork에 있는지를 검사한다.

- 동일한 subnetwork상에 존재 : 1.a 과정을 반복하고 최종적으로 전달한다.
- 동일한 subnetwork상에 존재하지 않는 경우 : 1.b 과정을 최종 destination에 도착할 때까지 반복한다.
- IP address : used to locate and get to the final destination
- MAC address : used at
each stepon its way to the final destination→ MAC address는 동일한 subnetwork에 있는 network device끼리 data를 전송하는데 사용된다.
💡
비유하자면 datagram이 우리가 실제로 붙이고자 하는 택배이고, frame은 택배차량이라고 생각해주면 된다. datagram에 속하는 IP address가 실제 우리가 원하는 최종 도착지와 출발지이고, frame에 해당되는 MAC address는 택배 차량의 출발지와 도착지에 해당한다고 생각해주면 된다.
Procedure with OS perspective
When a packet arrives at the Network Interface Card (NIC), the next steps in most systems proceed as follows:
- Interrupt Generation: When a packet enters the NIC, the NIC sends an interrupt to the CPU. An interrupt is a signal to the CPU that says "There's something important that needs immediate attention".
- Interrupt Handler Invocation: When this interrupt occurs, an interrupt handler in the operating system is invoked. This handler contains code to handle specific types of interrupts (in this case, network packet reception).
- Packet Reading: The interrupt handler reads the packet from the NIC and copies it into memory (Direct Memory Access (DMA) may also be used). Afterward, this packet is passed to the network stack in kernel space.
- Protocol Stack Processing: The network stack processes through various layers of OSI model including Data Link Layer (Layer 2), Network Layer (Layer 3), Transport Layer (Layer 4) etc. At each layer, necessary processing happens according to its protocol(Ethernet, IP, TCP/UDP etc).
- Application Layer Data Delivery: Finally when it reaches Application Layer, operating system delivers data to application through corresponding socket.
💡
참고로 router도 CPU가 존재한다. 그래서 NIC로부터 interrupt를 받는다.
💡
4번 과정에서 Network layer까지 decapsulation을 진행한 뒤 destination IP와 나의 IP가 다르다면 상위 layer로 올라가지 않고 Link layer로 다시 내려오게 된다.
Port number
- A
portis Not a physical connection
- It is a
logical connectionthat’s used by program and services to exchange information
- It specifically determines which
programorserviceon a computer or server that is going to be used
💡
Port number를 특정 network service나 process를 식별하는 역할을 한다.
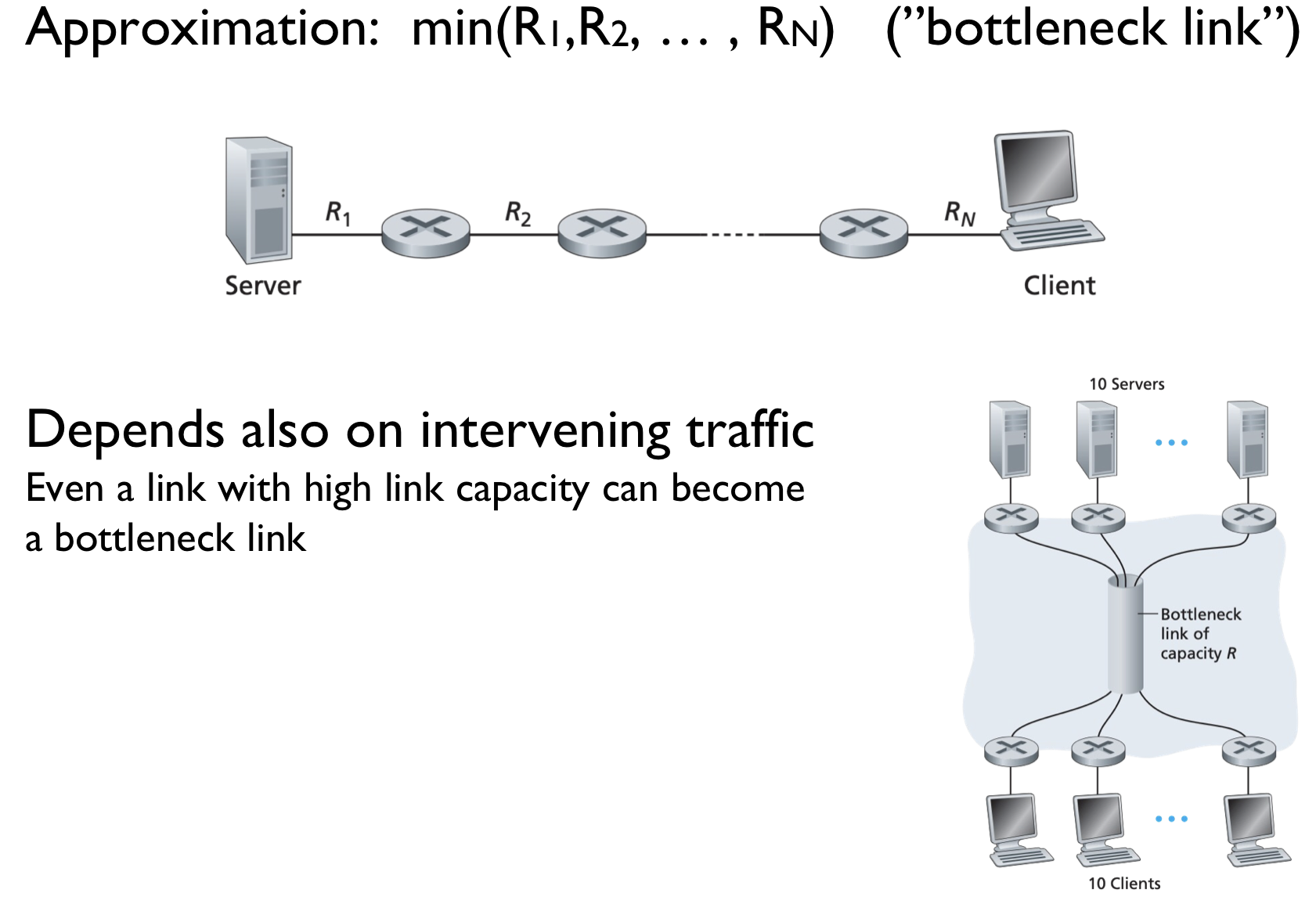
Difference between Link Capacity and Throughput
- Link Capacity (bandwidth) : maximum amount of data that can be transferred over a given path, or link, per unit of time
- Throughput : actual amount of data that is successfully transferred from one place to another in a given period of time.
- Goodput : rate of data passed to the
application layer→ Application level throughput이다.
💡
즉, Link capacity는 이상적인 최댓값이고, throughput은 현재 해당 link/path에서 특정 기간동안 얼마나 전송되고 있는지에 대한 값을 의미한다.
💡
즉, 그래서 throughput이 bottleneck link나 intervening traffic에 의해서 영향을 받는 것이다.
반응형
Contents
소중한 공감 감사합니다