Computer Science/Computer Architecture
5. Large and Fast: Exploiting Memory Hierarchy
- -
728x90
반응형
Memory Technologies
메모리를 구현하기 위해 사용되는 소자에 따라 성능이 결정됨

- Static Random Access Memory (SRAM)
- Dynamic Random Access Memory (DRAM)
- Flash memory (e.g. SSDs)
- Magnetic disks (e.g. HDDs)
💡
Access time이 아래로 갈 수록 점점 커진다.
모두 다른 전기적 특성을 가지고 만든 것. 특히 전원을 꺼도 data가 남아있는지 여부를 기준으로 나눌 수 있다.
SRAM과 DRAM은 volatile memory이고, Flash memory와 Magnetic disk이다.
→ volatile memory는 전원이 끊기는 순간 정보가 다 날아간다.
💡
Volatile memory의 경우 전원이 꺼지면 data가 날아가지만, 접근 속도가 빠르다. (Trade-off). 또한 volatile memory가 non-volatile memory가 더 비싸다 (여기서도 Trade-off)
SRAM/DRAM Technology
왜 하나는 static이고 하나는 dynamic인가?
static은 어떤 값을 쓰고 전원 공급을 끊지 않는 이상 해당 값이 유지가 된다. (시간이 지남에 따라 static하게 값이 고정되어있음). 반면, dynamic의 경우에는 해당 값이 바뀔 수 있음. 이걸 막기 위해서 지속적으로 다시 값을 써줌.
SRAM
- 메모리의 크기는 작음
- DRAM에 비해서 훨씬 빠른 data 접근 속도
→ SRAM은 큰 용량으로 쓰지 힘듦. 비싸기도 하고, 발열이 굉장히 심해짐
DRAM
- 메모리의 크기는 큼
- SRAM에 비해서 훨씬 느린 data 접근 속도
→ 따라서 주로 main memory에 사용된다.
💡
SRAM을 processor와 가깝게, DRAM을 processor와 멀게 배치하는 방식으로 memory hierarchy를 구성하게 되면, processor가 마치 크고 빠른 instruction/Data memory가 존재하는 것처럼 보여줄 수 있다.
Flash & Disk Memory
Non-volatile이다. 저장해야하는 목적으로 사용된다.
Used as a Secondary storage of a system (매우 느려서 main memory로는 사용하기 힘듦)
→ 이것들 관리는 OS에게 맡김
Unlimited Fast memory?
SRAM만으로 unlimited Fast Memory를 만드는 것은 불가능하다.
(DRAM은 일부 가능하기는 하지만, 어마어마하게 큰 것은 비용적으로 불가능하다.)
그래서 SRAM의 빠른 접근 속도와 DRAM의 널럴한 용량 제공에 대한 이점을 둘 다 어떻게 살릴 수 있을까에 대한 고민
→ 그래서 등장한 개념이 Memory hierarchy (SRAM과 DRAM을 섞어 쓰겠다.)
→ SRAM와 DRAM을 계층화시켜서 장점을 둘 다 활용하겠다는 것.
💡
SRAM에 접근을 해보고 없으면 DRAM에 접근을 해보겠다는 것.
왜 이러한 memory hierarchy가 먹히는 것일까?
Locality때문이다.
Principle of Locality
Temporal locality
If an item is referenced, the item is likely to be referenced again soon
→ 메모리에서 읽은 값을 조만간 참조할 것이다.
Spatial locality
If an item is referenced, items whose addresses are close by are likely to be referenced soon
→ 메모리에서 읽은 값 근방으로 조만간 참조할 것이다.
Example : The Sum of an Array
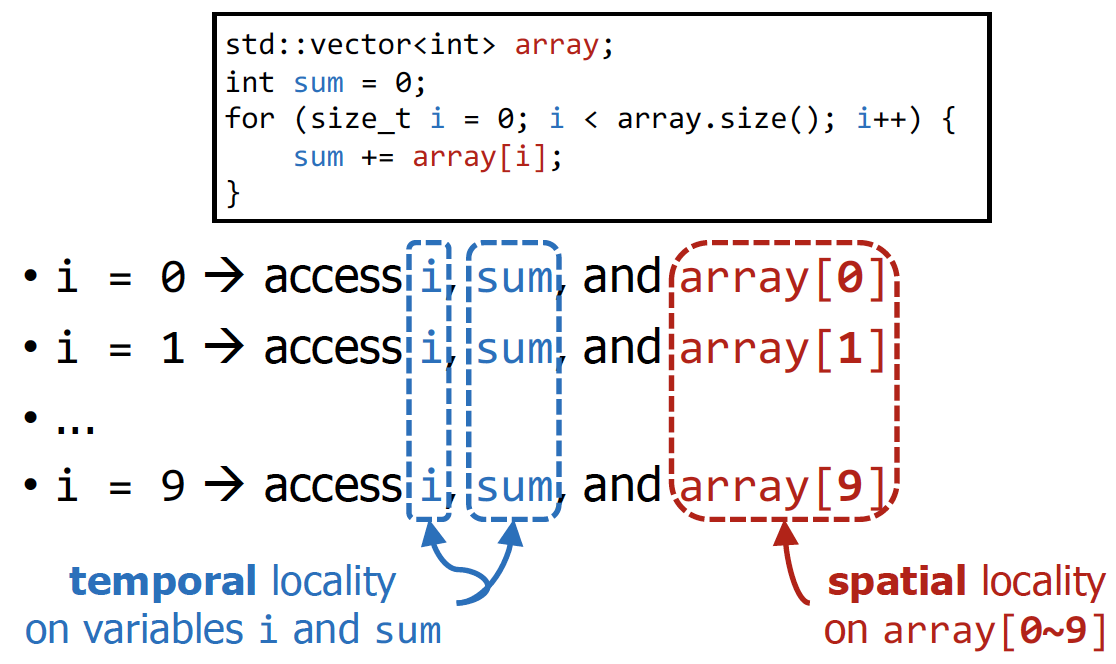
💡
각 iteration마다 i와 sum을 접근한다는 점에서 temporal locality, array는 근방에서 접근한다는 점에서 spatial locality이다.
Memory Hierarchy
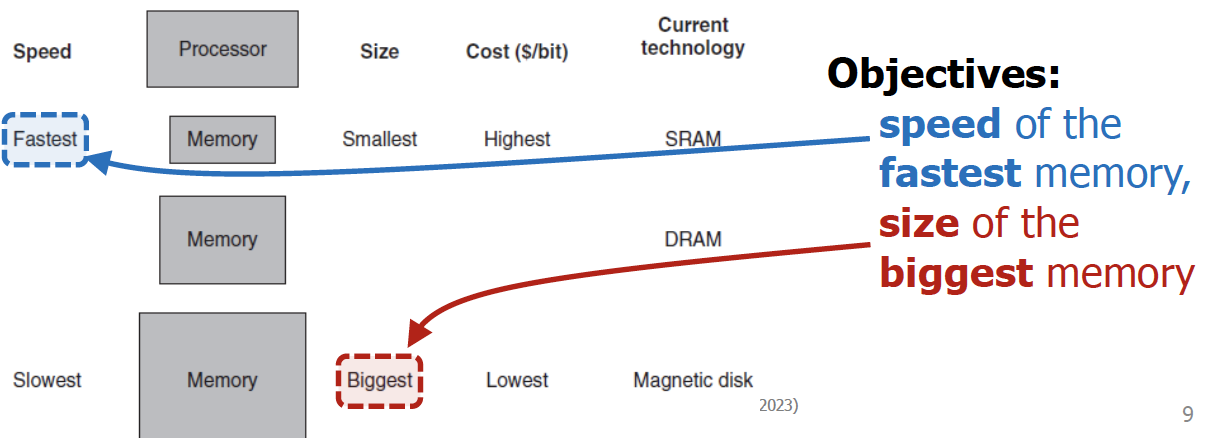
Processor에 가까울수록 접근 속도는 빠르지만 크기는 작고, 반대로 멀수록 접근 속도는 빠르지만 크기는 크다.
→ 만약 locality가 없다면 결과적으로는 DRAM에 접근하는데 걸리는 시간으로 converge하게 된다.
근데, locality때문에 memory hierarchy가 유용하게 되는 것이다.
💡
최근에 접근한 data나 그에 인접한 data를 SRAM에 넣고 성능의 향상을 노림.
즉 locality에 해당하는 데이터들은 SRAM에 넣고, 나머지들은 DRAM에 넣음. 즉 속도와 크기를 모두 다 잡겠다는 것.
💡
SRAM 안에서도 hierarchy를 둔다. SRAM의 크기가 작을수록 접근속도가 빨라지기도 하고, locality의 정도에 따라 hierarchy를 두고 싶은 것. (DRAM은 2단계로 나누지 않는다.)
💡
일반적으로 Computer Architecture에서는 memory라고 하는 것은 SRAM와 DRAM만을 의미하게 된다. 그림은 무시해도 된다.
이때 SRAM와 DRAM을 활용하여 Instruction memory와 Data memory를 구현하게 된다.
hierarchy가 무슨 의미인가?
상위 memory level에 담겨있는 data는 하위 memory level에 담긴 data의 subset이다. 즉 상위 메모리에 있는 정보는 하위 메모리에도 존재한다.
Data in a Memory Hierarchy
하드웨어적으로 data를 어떤 식으로 관리할 것인지?
💡
OS에서 배운 paging은 DRAM와 SDD/HDD 사이의 data를 어떻게 이동할 것인가에 대한 논의이고, CA에서의 paging은 SRAM와 DRAM 사이의 data를 어떻게 이동할 것인가에 대한 논의이다. 즉 구분해야 한다. (사실 virtual memroy를 도입하면 CA에서도 SDD/HDD까지의 논의로 확장시킬 수 있다.)
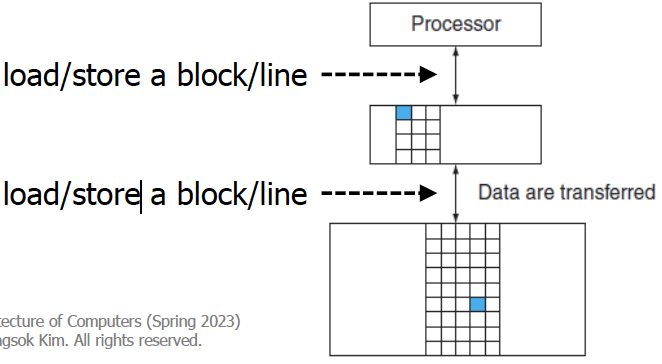
서로 다른 memory hierachy끼리 data를 주고 받을 때는 인접한 memory level 사이에서만 주고받을 수 있다. 이때 인접한 memory level 사이에 주고받는 데이터의 단위를 block(line)이라고 부른다.
💡
Processor와 SRAM은 block size가 4byte(직관적으로 생각했을 때, 1word와 크기가 같아야 한다.)이고 SRAM와 DRAM은 block size는 64byte이다. 일반적으로 하위 memory level로 갈수록 block size는 커진다.
예를 들어 lw $s2, 0($s3) 이고 $s3 = 0x1000이라고 하자.
processor와 SRAM은 0x1000~0x1003를 주고 받고, SRAM과 DRAM은 0x1000 ~ 0x1063을 주고 받는다.
💡
상위 level에 있는 값들은 하위 level에 있는 값들의 일부분이다. 데이터가 주고받는 단위를 block이라고 한다. 또한 인접한 level들끼리만 데이터를 주고받을 수 있다. 예를 들어 정의된 level이 4개면 정의될 수 있는 block의 개수는 3개이다.
Hits & Misses
Hit : Processor가 요청한 data가 해당 memory level에 있는 경우
Miss : 그 반대
💡
Miss가 나면 계속해서 더 낮은 memory로 이동해서 존재하는지를 체크. 즉 SRAM 단계에서 miss가 발생한 것들만, DRAM 단계를 체크하게 된다.
각 memory-level 별로 Hit/Miss rate을 계산할 수 있다. 이러한 계산이 중요한 이유는 이를 바탕으로 평균 메모리 접근 속도를 계산할 수 있기 때문이다.
💡
DRAM은 가장 마지막 level로 CPU가 요구하는 모든 데이터는 항상 DRAM에 담겨있다고 가정
Hit time(Hit latency) : the time to access the data in the current level. 즉 SRAM에 존재하는 data를 CPU에게 주는데 걸리는 시간이다.
Miss penalty : the time to deliver a missing block/line from the lower memory level.
💡
DRAM은 miss penalty가 없다. (여기서는 DRAM에 필요한 데이터가 다 있다고 가정. DRAM과 storage끼리는 OS에서 담당). 만약 virtual memory까지 고려하게 되면, DRAM에도 miss penalty가 발생하게 된다(Stroage 내부 영역을 swap space라고 부름).
이때 반드시 해당 memory level 입장에서 따져야한다.
SRAM에서 30개의 request가 났고, hit를 25개, miss를 5개가 났다고 가정하자.
→ 해당 SRAM 아래에 있는 것의 request의 개수는 5개임에 주의하자.
💡
해당
memory level 입장에서 각각 따져야 Hits & Misses in a 2-Level Memory
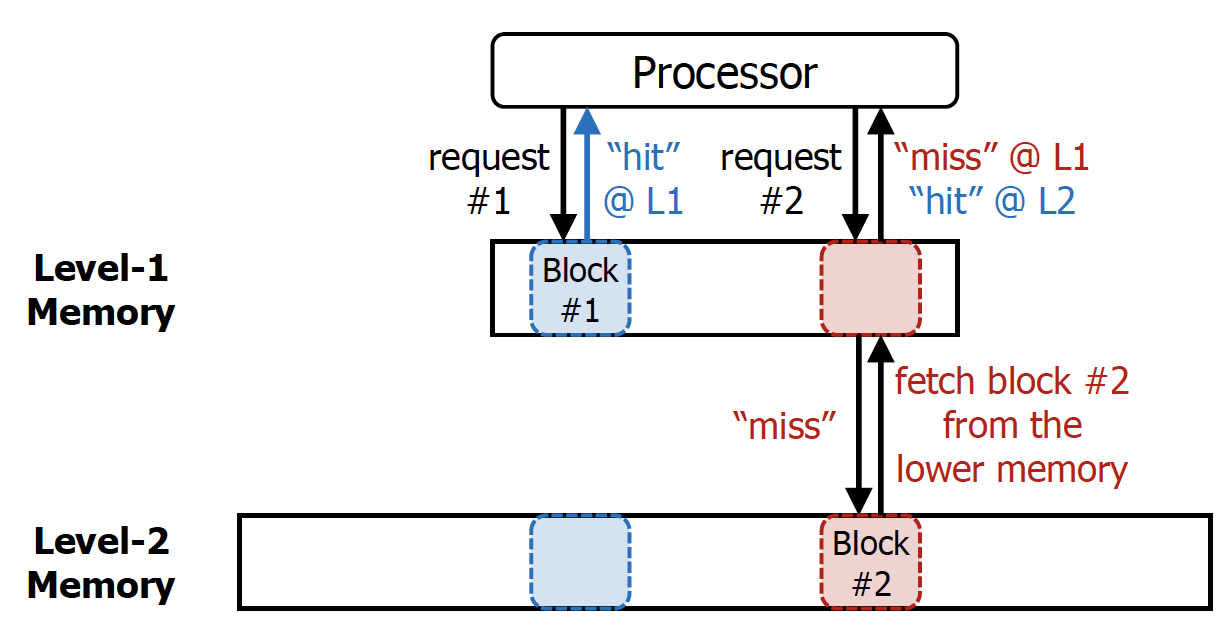
i(이때 Level-1은 SRAM, Level-2는 DRAM으로 생각해주면 된다.)
💡
MissPenalty는 수업에서는 hit이 발생하지 않아서 추가로 들어가는 시간이라고 생각해주면 된다. 대략적으로 해당 memory hierarchy보다 낮은 memory hierarchy에서 해당 memory hierarchy까지 메모리를 넘기는데까지 걸리는 시간이라고 이해하면 가장 정확하다.
💡
HitTime : 현재 memory hierarchy에서 바로 상위 memory hierarchy로 block을 fetch하는데까지 걸리는 시간
💡
대충 request에 들어가는 시간은 무시
생각해보면 위 그림은 lw인 경우인데, sw인 경우에도 어차피 대칭적일 것이므로 동일하게 취급해주면 될 것 같다.
Cache
결국, SRAM을 어떻게 관리할 것인지가 굉장히 중요한 문제가 된다
→ 즉 CPU가 어떤 명령어를 요청을 했을 때, SRAM에 어떤 메모리를 남겨야하느냐는 문제이다.
그러한 의미에서 등장한 개념이 Cache이다. DRAM와 CPU 사이에 존재하는 SRAM에 해당하는 memory level들을 Cache라고 부른다.
엄밀한 정의는 다음과 같다
Represent the level(s) of the memory hierarchy between the processor and the main memory(DRAM)

💡
Cache는 없을수도 있고 4단계 layer까지 존재할 수 있다.
CPU 입장에서는 접근해야하는 memory 주소를 계산하고, 일단 1차적으로 Cache에 요청하게 된다. 만약 hit가 나게 되면, 해당 메모리에 data를 저장하거나 주게 된다.
→ 이러한 형태의 cache behavior를 cache serves the requests 라고 부른다.
💡
CPU에서 sw 명령어를 수행하더라도, 완료했다는 signal를 CPU에게 보내야 한다. 즉 lw, sw 모두 신호가 CPU에게 최종적으로 가게 된다.
그렇다면 Cache입장에서는 다음과 같은 기능을 수행해야 한다.
- CPU가 요청한 memory가 해당 Cache에 있는지를 판단해야 한다. (즉 hit인지 miss인지 판단해주어야 한다.)
- 만약 존재한다면, 어떻게 해당 data는 access할 것인가? (
data access라고 부른다.)
Direct-Mapped Caches
Assumptions
- CPU는 lw, sw 명령어를 요청한다. 즉 4byte 단위로 메모리 request를 한다고 가정.
- Cache를 구성하는 block의 size 또한 4byte라고 가정
Concepts
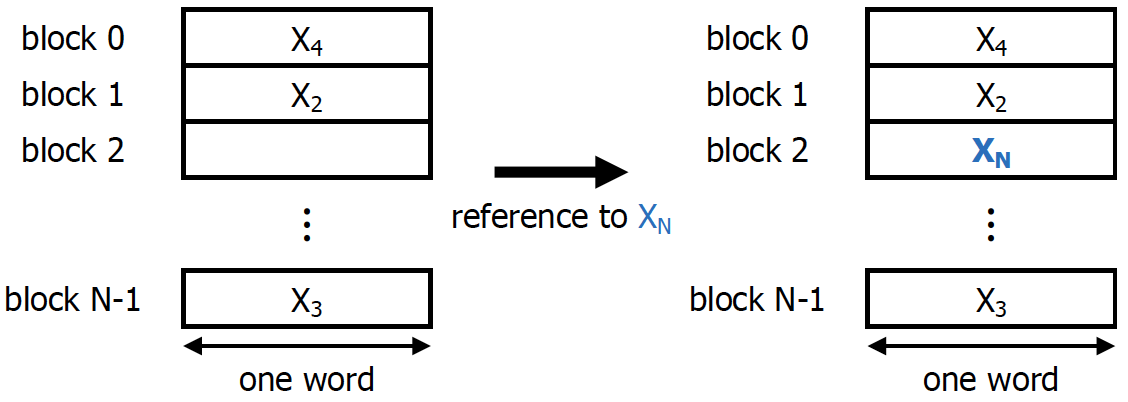
Direct-Mapped Cache는 1word는 1개의 memory block에만 mapping할 수 있다는 concept이다. (즉 저장될 수 있는 block이 1개로 고정)
💡
4Byte의 크기를 가지는 block이 N개 있는 상황이므로 Cache의 크기는 4N Byte이다.
주로 Word address % N을 통해서 어느 memory block을 담길지를 결정하게 된다. 32bit machine을 기준으로 개의 word가 존재하는데, 각 word가 개의 cache block 중 1개의 block에만 저장될 수 있다고 제약을 거는 상황이라고 이해하면 된다.
💡
이때 각 word가 들어갈 수 있는 cache block은
deterministic 하다. 즉 하위 memory level로 밀려났다가 다시 cache로 오더라도 동일한 위치에만 저장될 수 있다. 따라서 해당 data가 있는지 알기 위해서는 어느 cache block에 대응되는지를 계산하고, 해당 cache block에 해당 data가 있는지만 확인해주면 된다.위 상황에서처럼 cache에 N개의 block이 존재를 하고, 해당 cache가 Direct-Mapped 방식이라면 N-block direct-mapped cahce 라고 부른다.
Mapping a Word to a Cache Block
앞서 논의한 바와 같이 32bit machine의 경우 word address를 가질 수 있다. 이러한 word address를 block address 라고 부른다.

- Byte address를 Block address로 변환한다.
- Block address를 Cache block에
Modulo연산을 통해 대응시키게 된다.
💡
L1 cache의 경우에는 block의 크기가 word이기 때문에 word address와 block address를 구분할 필요가 없지만, 일반적으로 하위 level의 cache의 경우에는 block의 크기가 word보다 크다. 따라서 word address를 block address로 바로 쓸 수 없다. 따라서 정확하게는 두 용어를 구분해야 한다.
Validating the Target Block
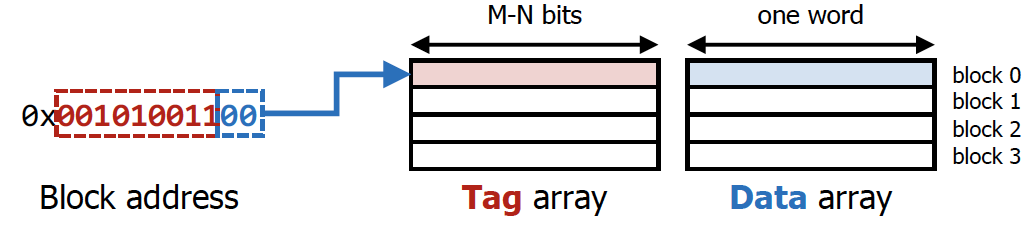
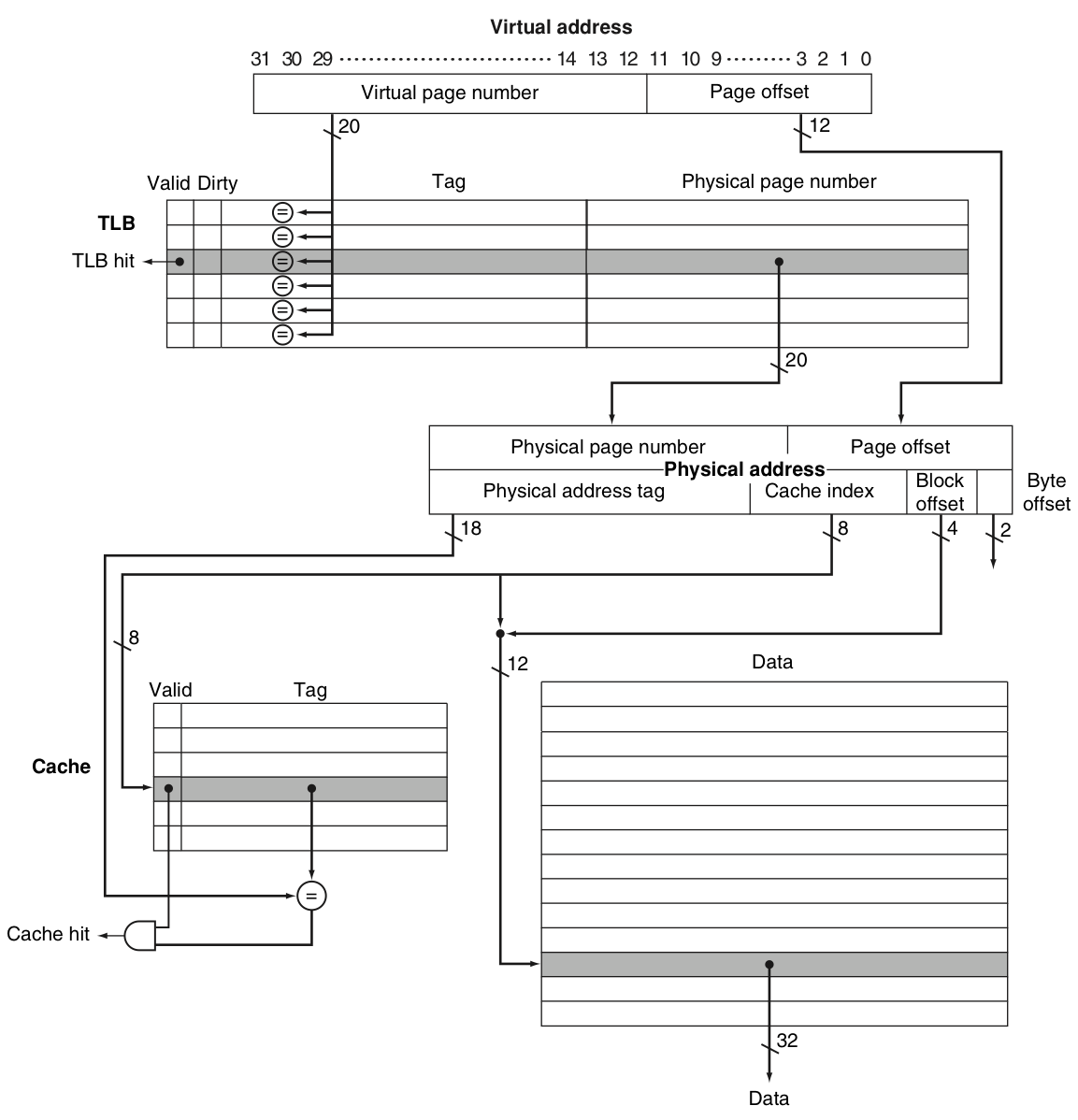
Cache block이 총 4개라고 가정하면, 각 Cache block이 관여하는 block address는 총 개이다.
따라서 해당 Cache block에 어떠한 block address가 들어갔는지를 판단해주기 위해서, 나머지 28개 bit(Tag)를 Tag array에 넣는다. 위 상황에서는 001010011이 Tag이다.
💡
정확하게는 Cache block의 index를 판단할 때 고려한 bit를 제외한 나머지 bit을
Tag로 사용하는 것이다. (그러면 유일성이 보장된다.)즉 CPU가 요청한 block address를 통해 계산된 Tag와 저장되어 있는 Tag의 값이 같은지 여부를 통해 hit 여부를 판단하게 된다.
Checking an Empty Cache Block

추가적으로 cache block이 비었는지 여부도 관리해주어야 한다.
→ 사실 생각해보면 어떤 bit가 들어는 있을 것인데, 이게 유의미한 값인지를 판단해주어야 한다.
그래서 valid bit 가 필요하게 된다. 즉 Tag를 비교하기 전에 valid bit가 무엇인지 여부를 판단한다.
- 해당 valid bit가 1이면, cache block이 valid word를 가지고 있다는 의미이다.
- 해당 valid bit가 0이면, cache block이 empty라는 의미이다.
💡
부팅시에 valid bit을 0으로 초기화한다.
Accessing a Cache Block
CPU가 lw, sw를 Cahce에게 요청을 한 상황이라고 가정하자.
- Calculate the target cache block
- CPU가 요청한 32bit의 byte 단위의 메모리 주소를
Right-shift연산을 통해 block address를 구한다.
- block address에
Modulo연산을 통해 대응되는 cache block를 구한다. (Take the N least-significant bits of the block address)
- CPU가 요청한 32bit의 byte 단위의 메모리 주소를
- 해당 target cache의 valid bit이 1인지를 판단한다
- block address를 통해 tag를 구하고, target cache의 tag block에 저장되어 있는 tag값이 일치하는지 여부를 판단한다.
→ 일치하면 cache block에 저장되어있는 data를 읽거나 수정하면 된다.
Example : Accessing a Cache
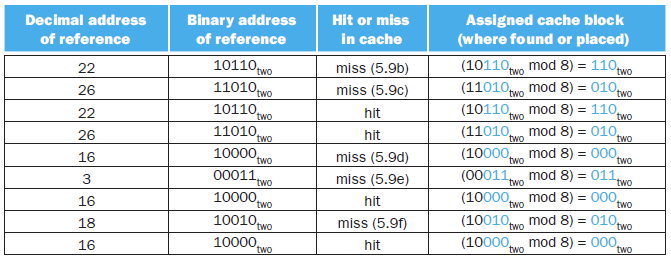
Suppose an empty 8-block direct-mapped cache
→ 즉 초기 valid bit가 전부 0이고, block address의 LSB의 3bit 를 활용해서 판단해주면 된다.
- Initially, all the cache blocks are empty and the valid bits are set to 0 (사실상 valid bit만 0으로 바꿔주면 된다.)
- Access to block address → miss (empty)
- tag :
- Index :

→ 하위 memory hierarchy로부터 해당 정보를 가져오고, valid bit를 바꾼다. 당연히 Tag도 수정해야 한다.
- Access to block address → miss (empty)
- tag :
- index :

→ 하위 memory hierarchy로부터 해당 정보를 가져오고, valid bit를 바꾼다. 당연히 Tag도 수정해야 한다.
- Access to block address → miss (empty)
- tag :
- index :

→ 하위 memory hierarchy로부터 해당 정보를 가져오고, valid bit를 바꾼다. 당연히 Tag도 수정해야 한다.
- Access to block address → miss (empty)
- tag :
- index :

- Access to block address → miss(
conflict)- tag :
- index :

→ 위 상황에서는 기존에 있던 데이터를 밀어내고 새로운 데이터를 불러옴 (이래서 conflict라고 하는 것)
Implementation
하드웨어에 block address가 주어졌다고 가정했을 때, 위 정보를 tag field와 cache index를 결정해야 한다.
→ cache index는 cache block이 몇 개 있는지에 따라 결정된다는 점을 유의해야 한다.
Realistic assumptions
- 32bit memory addresses
- A direct-mapped cache
- cache blocks (i.e. bits for the cache index)
- words per cache block (= byte)
→ 따라서 block address는 개 만큼의 LSB를 날려주면 된다.
💡
Tag는 결과적으로 32bit address에서 상위
Data array의 크기는?
word
Tag array의 크기는?
상황을 쉽게 하기 위해서 cache block을 가지고, words/block이라고 가정하자. (즉 20bit가 tag로 사용된다.) 이를 하드웨어적으로 구현한 결과는 다음과 같다.
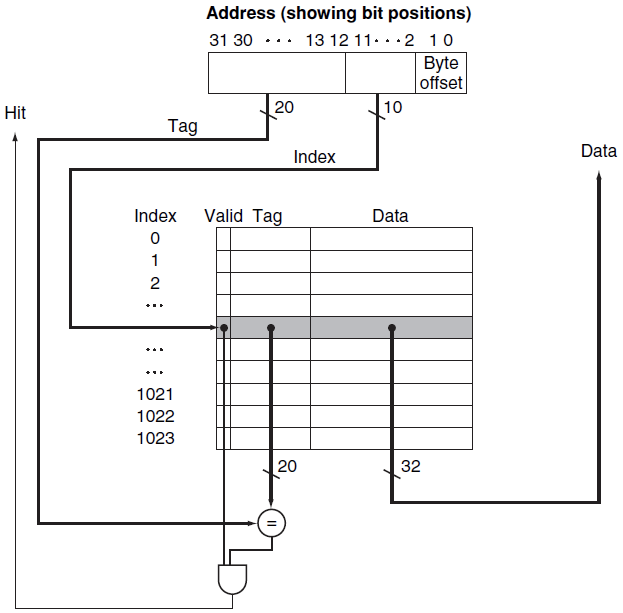
💡
Cache의 크기는 Data array의 크기만 계산하게 된다. 4KiB = 4096B. 또한 Cache 크기가 같아도, 하드웨어적으로 어떻게 생겼는지 직접적으로 알 수 없다. Data의 크기와 index의 크기를 조정해주면 된다. 그래서 index가 몇개까지 있는지 정보까지 줘야 정확하게 알 수 있다.
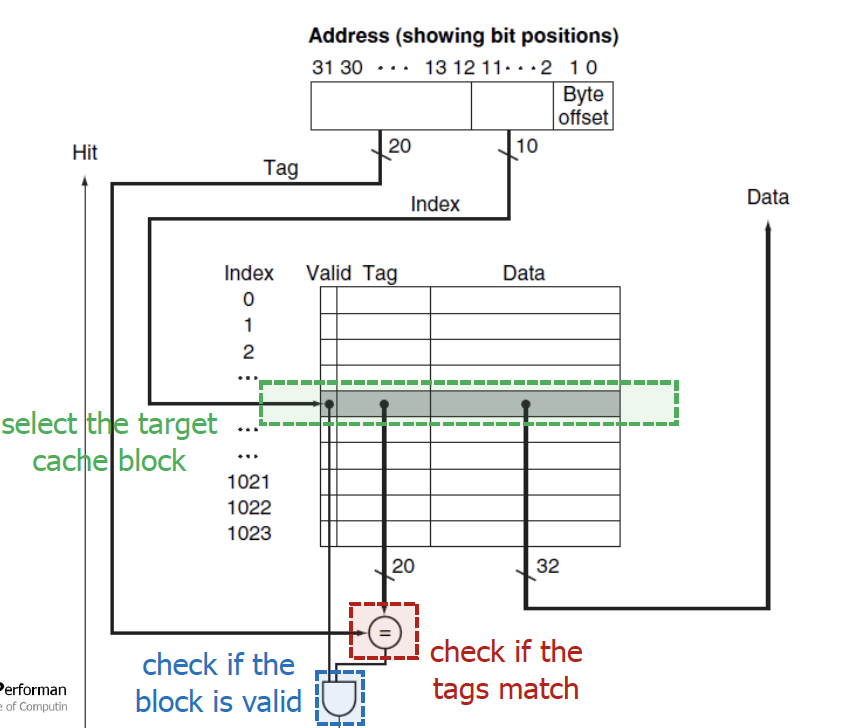
Miss Rate vs Cache Block Size

64byte만큼 L1의 block size를 잡았을 때 miss rate가 제일 낮음이 실험적으로 증명됨. (64byte/line)
→ 사실 생각해보면 block size를 1word로 잡으면 안됨. 그러면 locality를 이용하지 못하게 됨. 64byte로 잡으면 spatial locality를 충분히 활용할 수 있게 된다.
Handling Cache Misses
Miss는 2가지 종류가 존재하게 된다.
- Cold miss : 해당 cache에 유효한 데이터가 없는 경우 (i.e. valid = 0)
- Conflict miss : 유효한 데이터가 있지만 tag가 달라서 conflict가 발생한 것
결국 하위 memory level에서 load를 어떻게 할 것인지만 고민해주면 된다.
Handling Writes
여러가지 방법이 존재할 수 있다. 예를 들어 sw 0x1000을 실행하고 싶고, 현재 SRAM에는 해당 정보가 없다고 가정하자. 그러면 해당하는 정보를 들고와서 cache에 넣는다고 가정
→ 그러면 Cache에 있는 값과 DRAM에 있는 값이 inconsistency가 발생하는 문제가 발생하게 된다.
Inconsistency : 여러 level에 대해서 똑같은 주소에 대한 값이 여러개가 존재할 수 있게 된다. 하지만, write를 하는 과정에서 각 값이 달라질 수 있게 되는 문제가 발생할 수 있다.
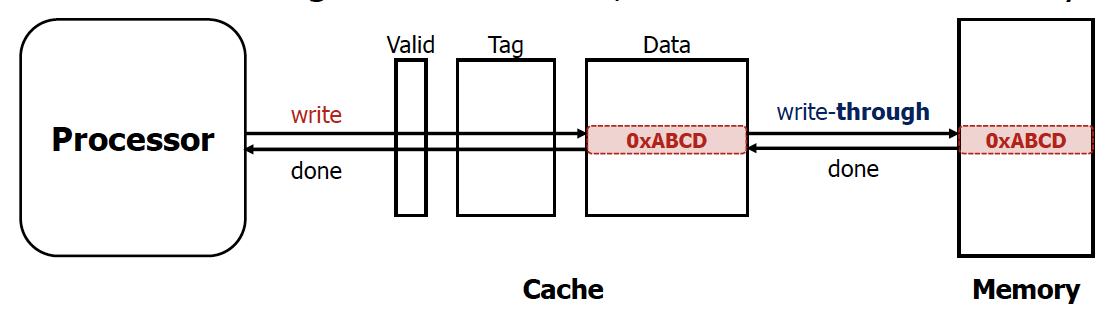
→ 모든 memory level에 write를 함으로써 위 문제를 해결할 수 있다. 이거한 구로를 wirte-through cache라고 한다.
💡
즉 Cache에 값을 쓰면, 해당 값을 메모리에도 쓰게끔 하는 것. 그리고 끝나면 끝났다고 신호를 보냄
하지만, write는 반드시 memory를 access를 해야한다는 문제점이 발생한다. (즉 inconsistency 문제는 해결할 수 있으나, 속도가 매우 느려짐)
사실 잘 생각해보면 DRAM에 쓰는 동안 CPU가 그 다음 명령어를 실행해도 될 것 같다. 왜냐하면 CPU가 Cache를 건너뛰지 않기때문이다. 그래서 등장한 개념이 Write buffer 이다. (Cache에는 최신 값이 있을 것이므로)
💡
Write buffer는 Wirte through의 variation이다.
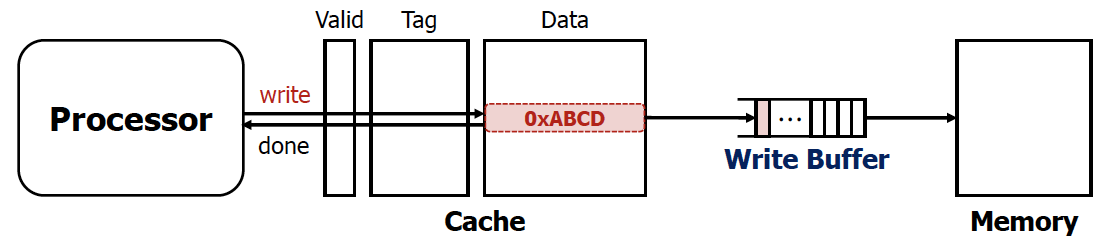
- Memory에 쓰기까지의 시간을 기다리지 않아도 됨
- CPU는 우선적으로 Cache에 있는 데이터부터 읽기 때문에 가능한 접근
하지만 Write buffer도 유한하다는 측면이 존재한다. 만약 Write buffer가 꽉 차 있는데 sw를 하고 있으면 문제가 발생하게 된다.
그래서 등장한 개념이 write-back cache이다.
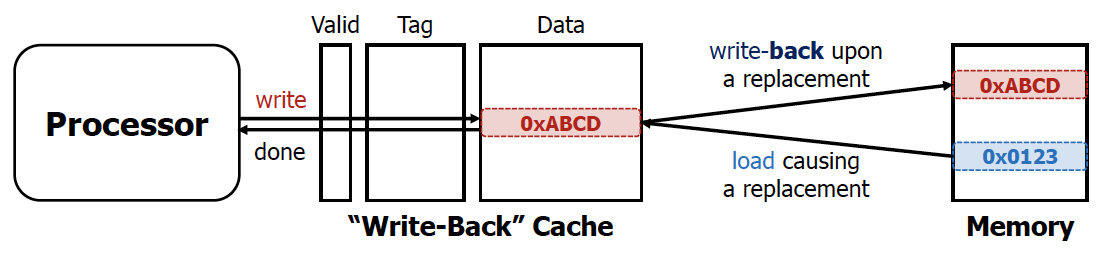
conflict miss가 발생할 때만 한방에 memory에 저장한다. 이전의 write buffer의 경우 buffer가 다 차면 cpu의 작동이 멈춰야한다는 문제점이 발생한다.
Measuring Cache Performance
Cache의 effectiveness를 어떻게 계산해야할 것인가?
얼마나 시간이 빨라졌는지를 계산해보도록 하자.
💡
실제로는 모든 명령어가 1cycle에 끝난다고 장담할 수 없다. 메모리 접근이 1cycle안에 끝난다고 장담할 수 없으므로 memory access할 때까지 stall해야하는 시간도 고려해야 한다.
이때
💡
hit이 발생하면 1cycle 내에 끝낼 수 있다고 전제
💡
추가적으로 은 프로그램 당 read opeation의 개수이다. program으로 나눠주는 이유는 프로그램의 크기나 실행 시간이 다양할 수 있기 때문이다. 프로그램마다 쓰기 연산의 총 횟수를 직접 비교하는 것보다, 쓰기 연산의 빈도를 프로그램의 총 접근 횟수로 정규화하여 cache miss ratio를 측정하는 것이다.
→ 교재에서는 read miss rate + write miss rate를 miss rate로 정의한다.
💡
Write의 경우 Read보다 훨씬 더 복잡함. 정확하게는 write through인지 write buffer를 쓰는 녀석인지에 따라서 계산을 다르게 해야 한다.
Cache misses의 경우는 write의 경우에도 동일하다.
하지만 만약 write buffer의 경우 buffer가 터지면 추가적으로 시간이 소요된다. 이러한 시간을 write-buffer contention 이라고 한다. 따라서 WriteBufferStalls는 0이라고 간주하면 된다.
💡
여기서는 write through의 buffer가 달린 형태라고 가정한다.
결과적으로
이때, read-missrate와 write-missrate는 같다고 가정한다.
또한, read-misspenalty와 write-misspenalty가 같다고 가정한다.
💡
즉 read와 write를 구분하지 않고 퉁칠 수 있다.
💡
아래는 특정 instruction의 수 * 해당 특정 instruction에 miss가 얼마나 발생하는지 * missPenalty이다. 즉 이러한 관점으로 아래 문제를 접근해보아야 한다.
따라서 misses/instruction , MissPenalty을 줄이는 것이 목표이다. (instructions/program을 줄이는 것은 프로그래머의 몫이다.)
💡
물론 도 가능하다. 즉 1. 프로그램에 속하는 instruction의 수를 줄이거나, 2. instruction당 발생하는 miss의 수를 줄이거나. 3. missPenalty를 줄여야 한다.
이때 program안에 있는 instruction의 수는 컴파일러가 결정하므로, 변경할 수 없다고 가정. 추가적으로 MissPenalty를 줄이는 것도 현실적으로 어려움이 많다. 그래서 명령어 당 miss를 줄이는 것이 목표가 된다. 즉, miss rate을 줄이는 방향으로 목표가 설정되게 된다.
Example
Assumptions
- Cache miss rates : 2% for instruction, 4% for data
- Cache miss penalty = 100 cycles
- Processor’s Cycles-Per-Instruction (CPI) = 2
- Frequencies of all loads and stores = 36%

I : 명령어 개수
💡
Ideal한 process 상황을 체크해보는 것이 중요하다는 측면에서 중요한 계산이다.
Average Memory Access Time
💡
MissPenalty : miss해서 추가적으로 발생하는 시간으로 이해해야 이 식이 naive하게 이해할 수 있다.
평균적으로 데이터를 접근하는데 걸리는 시간을 AMAT라고 한다.
💡
이러한 측면에서도 MissPenalty를 Miss가 발생했을 때 추가적으로 요구되는 시간이라고 해석하는 것이 자연스럽다.
예를 들면 다음과 같은 상황을 생각할 수 있다.
특정 processor의 clock period가 ns/clock, miss penalty가 20cycle, miss rate가 0.05 miss/inst, cache access time을 1cycle이라고 했을때 AMAT는 다음과 같다.
💡
사실상 cycle이 주어지면 시간이 주어진 것과 같다.
💡
일종의 AMAT를 해당 memory hierarchy에서 바로 위 layer로 block을 보내는데까지 기대되는 시간이라고 이해하면 된다.
Reducing Cache Misses
앞서 언급한 것처럼, 결과적으로 시간을 CPU time을 줄이기 위해서는 cache miss의 수를 줄이는 것이 굉장히 중요하다. 이를 위해서 여러가지 방법이 존재할 수 있겠지만, 그 중 하나의 방법이 Directed-mapped cahce를 수정하는 것이다. (뭔가 대응할 수 있는 cache의 개수가 다양해지면 miss가 나는 횟수를 줄일 수 있지 않을까하는 추측해서 비롯됨)
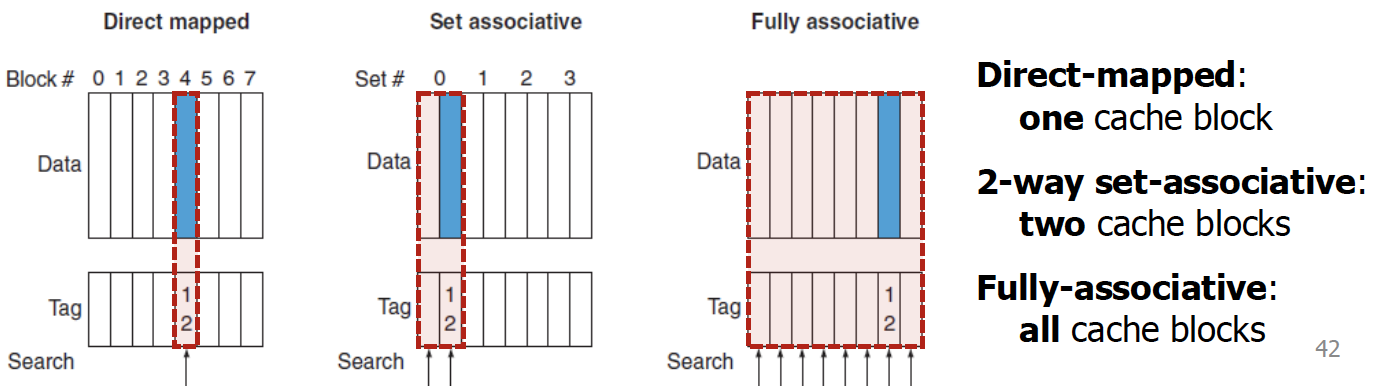
Directed-mapped cache의 경우에는 대응할 수 있는 cache block이 1개 로 유일하다. 이러한 제약을 푼 cache 형태로 Fully-associative 와 Set-associative cache이다.
→ Allow a data block to be mapped to multiple cache blocks
즉 set associative는 여러 개의 cache block에 들어갈 수 있게끔하는 것이고, fully associative는 모든 cache block에 들어갈 수 있게끔 허용하는 것이다.
Set associative의 경우에는 기존의 cache block을 set를 구분한다.
→ 일종의 상위 block을 더 둔 것이라고 생각해주면 된다.
💡
즉, set associative는 하나의 set에 대응되는 cache block에만 들어갈 수 있도록 허용하는 것이다. 한번 더 상위 계층을 만들었다고 생각해주면 된다. 즉 사실상
하나의 set 에만 대응되게끔 하는 것이다.이때, set associative를 N-way set-associative 라고 부르기도 하는데, N-way라는 의미는 1개의 set에 N개의 cache block이 들어간다는 의미이다.
Set-Associative Caches
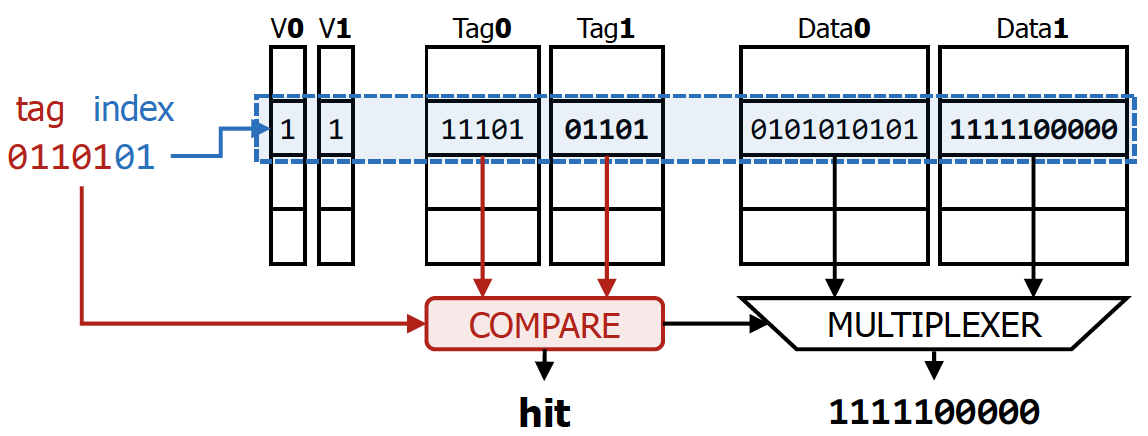
Set associative가 됨에 따라서 고려해야하는 cache block이 늘었다.
- 대응되는 set을 찾아야함
- set 내부에 있는 tag와 valid bit을 확인해야 한다.
💡
즉 Directed mapped cache에서 대응되는 cache block의 index로 사용하던 것이, 대응되는 set의 index로 사용된다고 이해해주면 된다. (이에 따라 index로 사용하는 bit수가 줄어들게 된다.)
추가적으로 set 내부적으로는 cache가 여러 개 존재하기 때문에 MUX를 통해 정보를 빼내게 된다.
💡
MUX의 control bit는 tag와의 비교를 통해 정보가 들어가게 된다.
Real-World Implementation

위 그림은 4-way set-associative cache를 하드웨어적으로 구현한 결과이다.
- Logical address를 block address로 변경한다.
→ block size가 4byte라고 가정하면 하위 2개의 bit를 제외하면 된다.
- block address를 사용하여 set의 index를 구한다.
→ 위 그림에서는 256개가 있으므로 하위 8개의 bit를 활용해서 set의 index를 구해주면 된다.
- 나머지 bit는 tag로 활용해주면 된다.
- 1개의 set에 4개의 block이 들어가있는 상황이므로 이에 대응되는 valid bit, tag bit를 전부 다 확인해주어야 한다.
Fully-Associative Caches
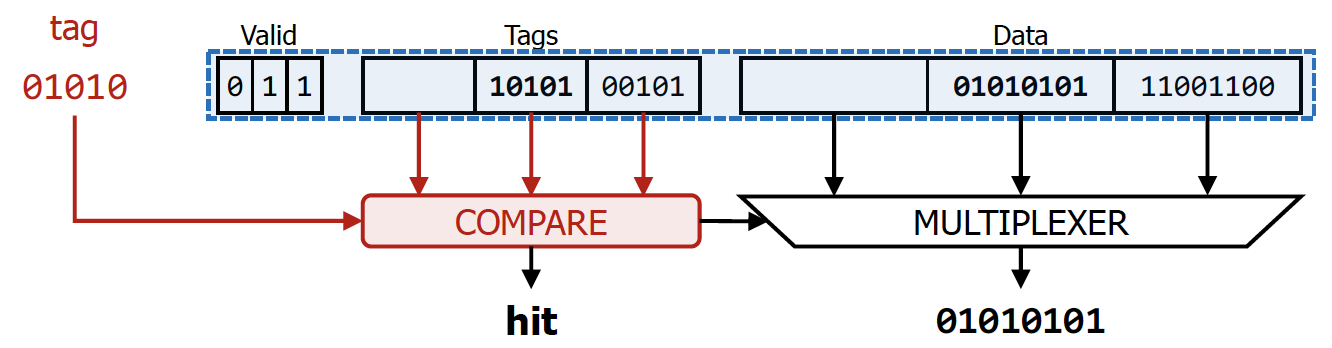
그냥 단순히 N-way set associative cache라고 생각하면 되는데, N이 존재하는 block의 개수라고 생각하면 된다.
→ 이에 따라 index는 0이 되게 된다.
💡
즉, block address bit 전부를 tag로 사용하게 된다고 생각해주면 된다. 직관적으로 set안에 들어가있는 cache의 개수가 커질수록 tag와 index를 나누는 기준이 점차 오른쪽으로 이동하게 된다. (index bit은 결국 set의 개수에 의해서 결정되기 때문이다.)
따라서 직관적으로 느낄 수 있겠지만, implementation cost가 굉장히 커지게 된다.
Handling Cache Misses
Directed mapped cache의 경우에는 miss가 난 경우 굉장히 단순하게 진행해주면 됐었다.
cold miss인 경우 해당 cache에 정보를 채우면 되고, conflict miss의 경우 기존에 있던 정보를 evict 시킨 후에 정보를 채우게 된다.
💡
만약 write back cache의 경우, conflict miss가 발생했을 때 propagate한다는 점까지 챙겨두도록 하자.
하지만, fully/set-associative의 경우에는 대응되는 set안에 들어간 cache block 중에 select 해야하는 문제점이 생긴다.
→ 그러면 어느 것을 evict 시킬 것인가? LRU (Least recently used)를 통해 결정한다.
💡
사실 위 내용은 OS에서도 나오는 내용이다. page replacement algorithm에서도 결국 특정 page를 swap out시켜야하는데, 어떠한 page를 swap out시킬지를 결정해야하는 문제를 해결하기 위한 방법들 중 LRU 가장 대표적이다.
LRU policy를 이용하여 temporal locality를 최대로 이용하려는 것이다.
Reducing the Miss Penalty
Set associative 방식을 고려하게 된 궁극적인 이유는 miss rate를 줄이기 위함이다. 예를 들어 directed mapped cache 방식의 경우 다른 block은 비어있는데, 특정 block만 선호되는 경우에는 문제가 발생할 수 있다. 이러한 상황에서 set associative 방식처럼 일종의 relaxation을 시켜주게 되면 miss rate를 줄일 수 있게 된다.
💡
set associative/fully associative 방식을 사용해도
miss penalty 는 줄지 않는다.그렇다면 miss penalty를 줄이기 위한 방법이 없을까?
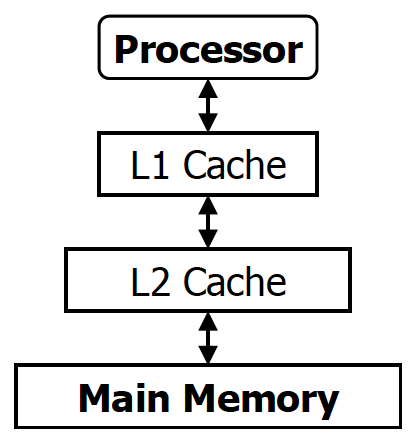
이러한 관점에서 해결책으로 등장한 개념이 multi-level cache이다. 지금까지는 CPU가 맨 위에 있으면 그 아래에 SRAM, 그 아래에 DRAM이 있다고 가정했었다. 위 상황에서는 miss가 나게 되면 바로 DRAM의 상대적으로 느린 속도를 체험하게 된다. 따라서 메모리의 계층화를 통해 miss penalty를 줄이려고 하는 것이다.
💡
multi-level cache를 통해 AMAT를 줄이려고 하는 것
즉 요약하면 다음과 같다.
set associative와 fully associative를 통해 miss ratio를 줄이려고 하는 것이고, multi-level cache를 통해 miss penalty를 줄이려고 하는 것이다. 줄이는 대상이 다르므로 매우 주의해야 한다.
이때 main memory(DRAM)은 backup storage로 사용이 된다. 즉, program을 돌리기 위한 instruction과 data를 다 가지고 있다고 가정한다. (물론 virtual memory를 도입하게 되면 이야기는 달라지기는 하지만, 당장은 이렇게 가정한다.)
💡
추가적으로 process에 가까운 cache가 숫자가 더 낮다. 즉 L1 cache가 processor와 더 가깝다.
Problems of the Main Memory
- 만약 실제 main memory의 크기가 작으면 어떻게 되는가?
→ out-of-memory issue로 인해서
실행할 수 없는문제가 발생한다. 즉 32bit machine의 경우 4GB의 logical address를 다 사용할 수 있다고 간주하는데, 만약 실제 physical memory가 1GB밖에 없다면 문제가 발생할 수 있다.
- 만약 main memory의 사이즈를 바꾸면 어떤가?
→ recompile해야하는 문제점이 존재한다. 예를 들어 physical memory가 1GB를 가정하고 프로그램을 짜고 컴파일한 것을 실제 physical memory가 4GB인 CPU에서 돌리면 효율성 측면에서 recompile해야하는 문제점이 발생한게 된다.
→ 이러한 측면에서 크고, 고정된 사이즈 의 main memory를 program에게 하여금 사용하고 있다는 착각을 부여하는 개념이 virtual memory 이다.
💡
Application level에서는 물리적으로 얼마나 많은 memory가 있던 간에 커다란 가상 메모리가 있는 것처럼 illusion을 제공하자는 것. 32bit machine의 경우에는 4GB가 있다고 제공해주는 것.
Virtual Memory

즉 실제의 physical memory가 얼마나 되었는지에 관계없이, 무조건 32bit machine 기준으로 4GB의 가상의 메모리를 program마다 제공해주는 것.
Implementing Virtual Memory
이를 실질적으로 구현하려면 secondary stroage가 필요하게 된다. main memory에 다 담아둘 수 없는 것들은 storage에 담아두게 되는데, 해당 목적으로 할당된 storage의 일부 영역을 swap space 라고 부른다.
💡
즉, OS차원에서 swap space를 할당해놓고, physical memory가 부족하면 swap space에 넣는다.
즉 process라는 개념은 CPU가 알지 못하고 OS가 아는 상황이므로, 해당 문제에 대한 해결을 OS에게 맡기는 것.
그러면 실질적으로 virtual-to-physical address translation이 필요하게 된다. 즉 virtual address를 실제 physical address로 translation시키는 작업이 필요하게 되는 것이다.
Step 1 : Add Secondary Storage
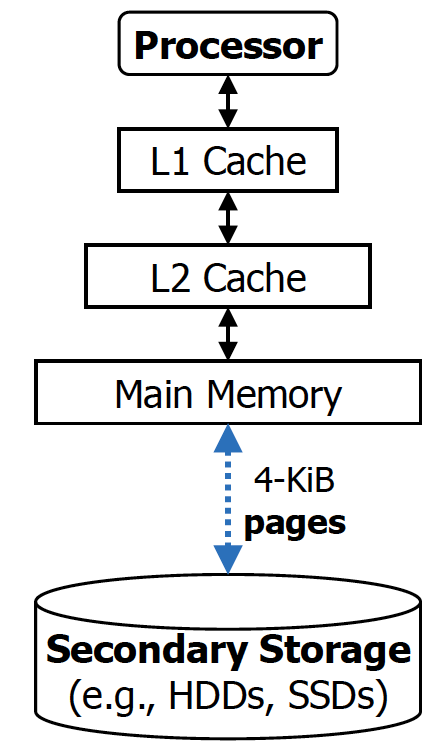
Main memory의 데이터를 백업해두기 위해서 secondary storage를 사용하는 것.
💡
즉, 이전까지는 process를 돌리기 위한 모든 정보(data나 code 등등)이 main memory에 있다고 가정했지만, virtual memory 개념이 등장하면서 데이터의 일부는 secondary storage에만 존재할 수도 있게 된다.
이때 main memory와 secondary storage 사이에 주고 받는 block을 page 라고 부른다.
💡
processor와 L1 cache, L1 cache와 L2 cache, L2 cache와 main memory사이의 데이터가 움직이는 것은
하드웨어적으로 관리를 하는 반면, main memory와 secondary storage는 OS가 하게 된다. 해당 작업을 하드웨어가 잘 진행할 수 없는 이유는 storage는 메모리가 linear address 형태가 아니기 때문이다. 실제로는 file-system이라는 secondary storage를 abstraction하는 interface가 있어서, file-system이 정의하는 방식으로 메모리를 저장하고 읽어야 한다. 근데 이러한 file-system은 software적으로 구현되기 때문에 OS에게 해당 역할을 넘기는 것.
Step 2 : Address Translation
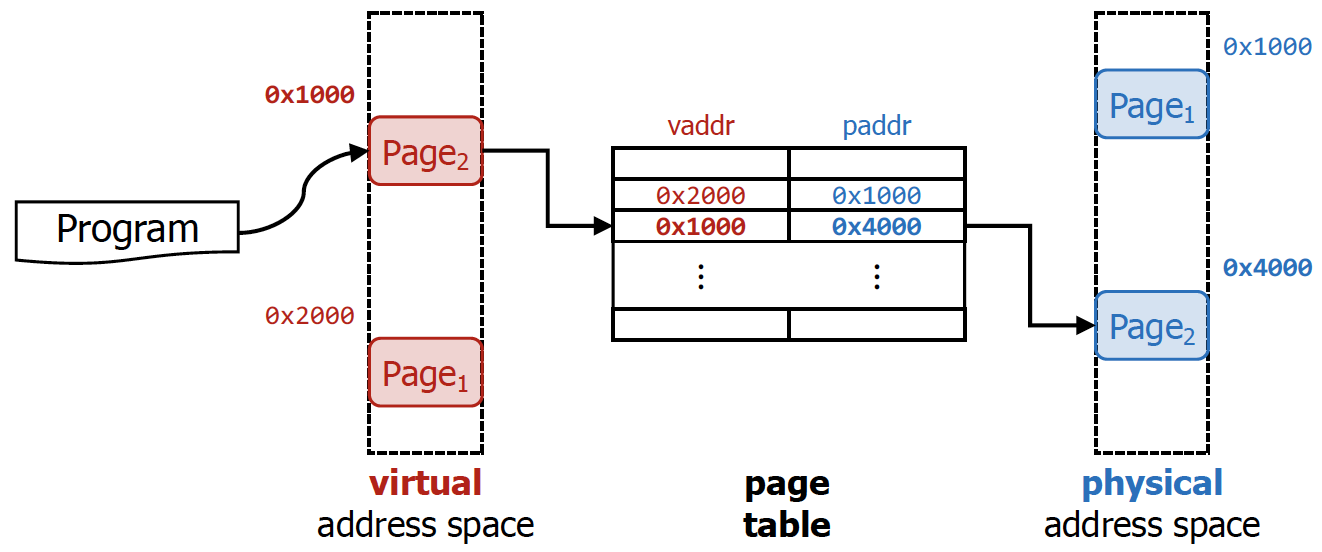
프로세스마다 page table을 만들고, 해당 page table을 토대로 physical address로 변환하게 된다.
→ 프로그램이 0x1000에 lw를 하면 하드웨어가 자체적으로 page table을 보고 physical address로 변환하는 작업을 거치게 된다.
이때 page table에 entry를 넣거나 뺴거나 하는 작업은 OS가 진행하게 된다. (왜냐하면 OS는 process가 어떠한 작업을 하고 있는지 알고 있기 때문이다.) 하지만, 실질적으로 명령어를 실행시키는 주체는 하드웨어이기 때문에 특정 명령어를 실행시킬 때 page table을 look-up을 해서 virtual address를 physical address로 변환하는 작업을 거치게 된다.

해당 작업을 수행하기 위해서는 다음과 같은 작업을 거치게 된다.
- virtual address를 page 크기를 기준으로 자른다.
- 자른 것을 기준으로 왼쪽이 virtual page number이고, 오른쪽이 page offset이다.
💡
즉 결과적으로 virtual page number를 physical page number로만 변환시켜주면 된다.
주의해야할 점은 virtual page number의 bit수와 physical page number의 bit수가 다를 수 있다는 것이다. 만약 32bit machine의 경우 virtual memory address는 항상 32bit이다. 실제 physical memory의 크기가 1GB라고 하면, physical memory address는 실질적으로 30bit이다.
→ 이렇게 되면 physical page number에 해당하는 bit수는 18bit밖에 안된다.
💡
즉 20bit에 해당하는 virtual page number를 18bit에 해당하는 physical page number로 변환하게 되는 것이다.
Step 3 : Handle Page Faults
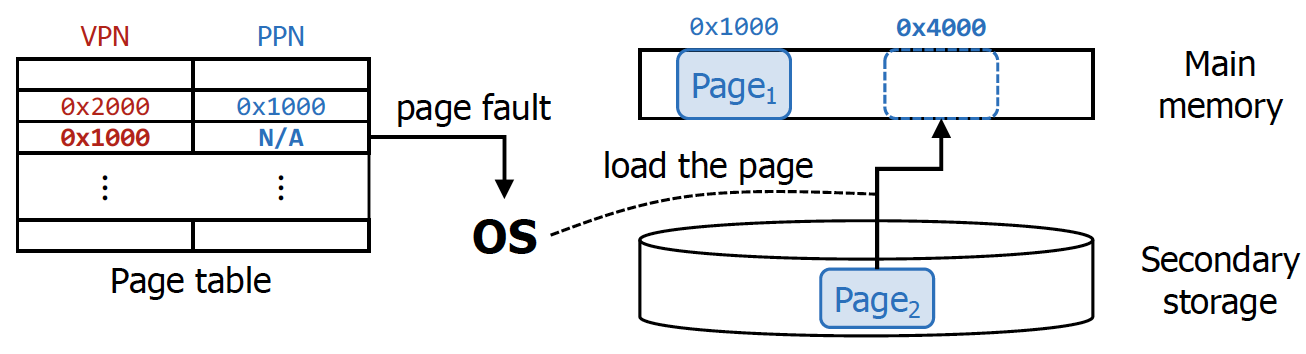
원하는 주소가 main memory가 아니라 storage의 swap space에 있을 수 있다.
→ 위 예시처럼 대응되는 physical frame이 존재하지 않는다고 page table에 저장되어있는 것이다.
만약 위 상황처럼 대응되는 physical frame이 존재하지 않는다면, CPU는 실행중이던 작업을 멈추고 page fault interrupt를 실행시킨다 (CPU는 cache와 main memory에 정보가 있다는 전제하에 실행시키고 있는 것. storage에 관한 부분은 OS가 알고 있으므로 처리해 달라고 요청하는 것이다.)
그렇게 되면 interrupt handler를 운영체제가 실행시키고, swap space에서 해당 데이터를 찾아 physical frame에 할당하고 page table을 업데이트하고 CPU execution을 resume하게 됨.
Pros & Cons of Virtual Memory
Pros
- 프로그래밍 차원에서 굉장히 장점 (physical memory에 대한 정보를 프로그래머가 몰라도 된다.)
- 운영체제 입장에서 서로 다른 processor가 남의 data를 보지 못하게 막는 역할을 수행하는 장점이 있음 (protection)
Cons
- performance degradation
💡
기존에는 L2 cache에서 miss가 나면 바로 main memory로 가면 됐는데, virtual memory를 사용함으로 인해 page table을 거쳐서 memory translation을 해야한다는 단점이 존재한다.
추가적으로 page table의 크기가 상당히 커서 탐색을 하는데 시간이 많이 걸린다는 단점도 존재한다.
💡
page table은 main memory에 있기 때문에 실질적으로 DRAM을 2번 접근하는 효과가 발생되는 단점이 발생한다.
Adding Virtual Memory Support

Processor는 OS가 만들어놓은 page table이 DRAM에 어떻게 저장이 되는가를 알아야하고, 현재 실행하는 명령어가 어느 process의 것인지, 또한 해당 process에 해당하는 page table의 base address는 어디인지에 대한 정보를 알아야 한다.
해당하는 정보는 page table register에 존재한다. 여기에는 현재 실행중인 process의 page table의 base address가 저장되어 있다.
page table의 각 entry를 PTE(Page Table Entry)라고 부른다.
Problem 1 : Large Page Tables
앞에서 언급한 것처럼 단순히 page table을 구현하게 되면 그 크기가 굉장히 커질 수 있게 되는 단점이 존재한다.
예를 들어 virtual address가 48 bit이라고 가정하면, VPN의 크기는 36ibt가 된다. 따라서 개의 서로 다른 PTE가 있어야한다는 것을 의미하게 된다.
일반적으로 page table의 크기는 8byte(36bit VPN, 38 bit PPN 가정)정도 되므로 각 page table마다 0.5TB가 되는 문제가 발생하게 된다.
Solution
- Large memory pages
→ page table의 offset에 해당하는 bit수를 늘리면 VPN의 크기는 준다는 것을 활용
- Inverted page table
결국 문제가 발생하는 근본적인 이유는 process마다 4GB에 해당하는 virtual memory를 주기 때문이다. 그래서 PPN에서 VPN으로 가자는 것. 즉 physical frame에 대응되는 virtual page를 구하자는 역발상
- Multi-level page table
page table을 몇 단계로 찢자

결국 핵심 아이디어는 한번에 VPN에서 PPN으로 변환하지 말고, 여러번 page table을 거치면서 address translation을 하자.
Problem 2 : Slow Page Table Accesses
Page table을 이용하게 되면서 DRAM memory access가 실질적으로는 2번 발생하는 문제가 생긴다. 특히 multi-level page table을 사용하게 되면 이러한 문제는 더욱 심각해진다.
Solution

Translation Lookaside Buffers(TLBs)를 사용
즉, page table의 일부 entry를 cache에 두자는 것
→ 최근에 address translation을 한 것들은 TLB에 저장을 해서 locality를 활용하자는 것
Problem 3 : Which Address for $s
최근 CPU는 한 프로세스의 명령어만 실행시키는 것이 아니라, 여러 프로세스의 명령어를 섞어서 실행하게 됨. 따라서 logical address가 같아도, 대응되는 physical address가 다를 수 있다는 점을 기억해야 한다.
💡
만약 두 프로세스가 동일한 물리 메모리 위치를 참조하는 데이터를 가지고 있다면, 이들이 동일한 논리 주소를 사용하지 않을 수 있습니다(프로세스마다 가상 메모리 공간이 다르기 때문에). 따라서 한 프로세스가 데이터를 수정하면, 다른 프로세스의 캐시에는 여전히 수정되지 않은 데이터가 남아있을 수 있습니다. 이렇게 되면 캐시 일관성이 깨지게 됩니다.
Solution
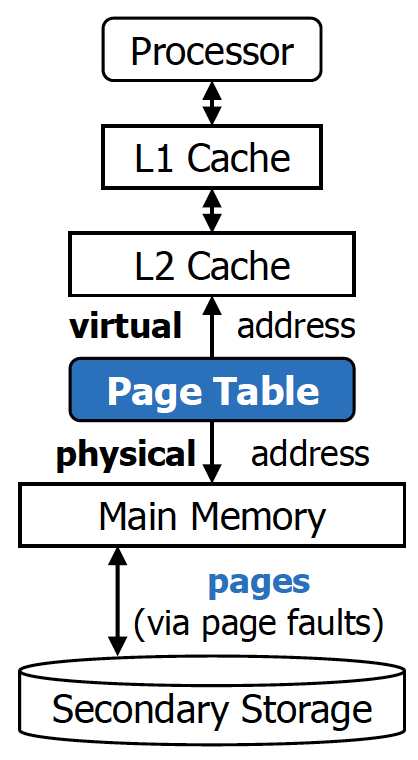
L1 cache부터 physical address를 사용하게끔 하자.
→ 이러한 cache를 Physically-addressed cache 라고 부른다.
원래는 L1 cache, L2 cache를 지나 page table 후 main memory로 접근하게 되는데, physically address cache의 경우는 L1 cache와 L2 cache도 address translation을 거친 후의 physical address로 cache block을 관리하게 된다.
따라서 CPU가 lw 혹은 sw명령어를 날리게 되면, 제일 먼저 TLB와 page Table을 보고 virtual address를 physical address로 바꾼다. 이러한 physical address를 가지고 L1 cache, L2 cache, main memory까지 접근하게 된다.
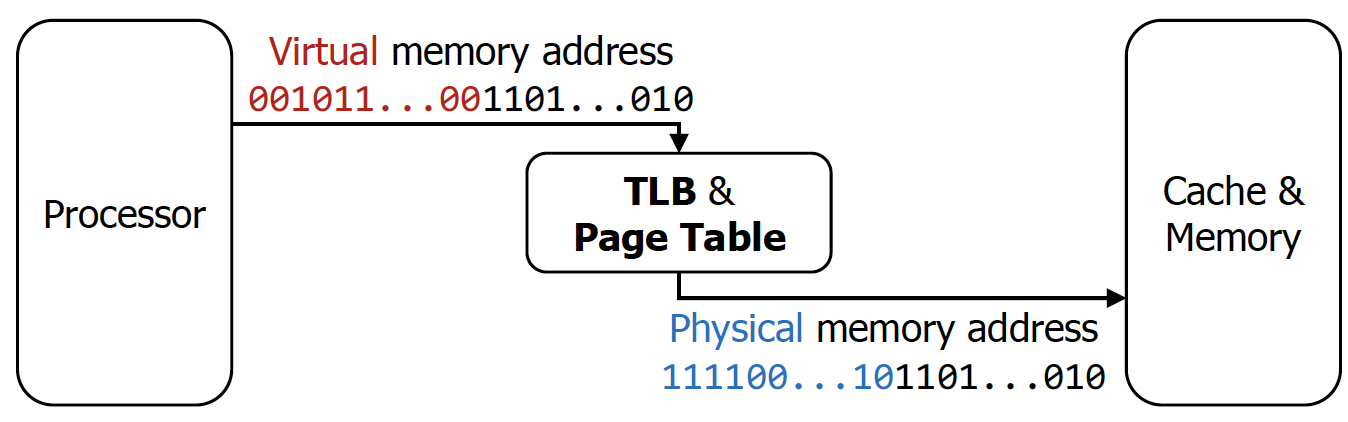
Virtual Memory + Caches + TLBs
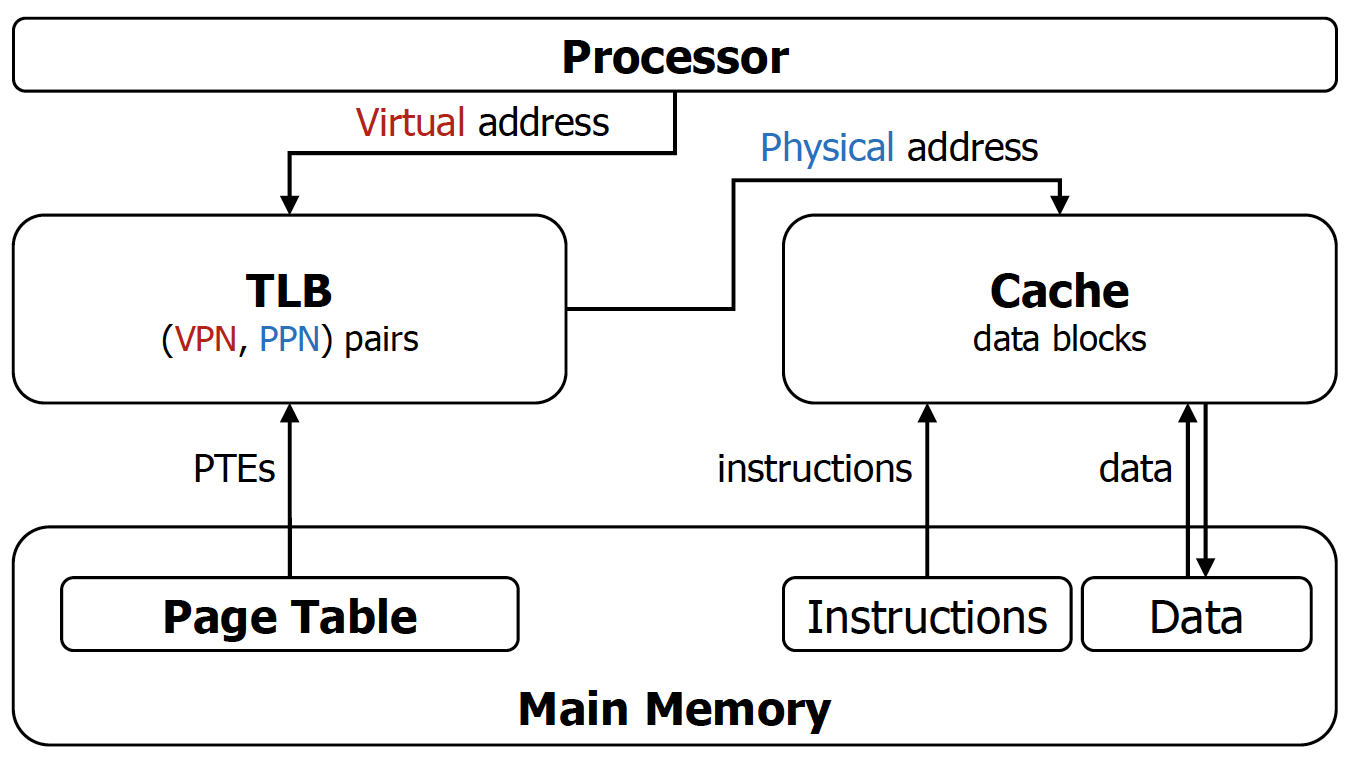
- CPU가 lw, sw 명령어를 날린 상황 (안그러면 memory access할 이유가 없음)
- 일단 TLB를 보고 해당 정보가 있는지 확인
- 해당 정보가 없으면 DRAM으로부터 page table entry를 받는다.
- 해당 정보를 가지고 cache에 physical address를 넘겨주게 된다.
→ 이미 physical address라서 main memory까지 쭉 사용할 수 있다.
반응형
Contents
소중한 공감 감사합니다