Computer Science/Computer Architecture
4. The Processor
- -
728x90
반응형
What Happens Inside a Processor

Processor도 digital circuit이므로 datapath와 control이 존재함.
Processor Microarchitecture
ISA가 동일해도 그것을 구현하는 하드웨어를 구현하는 방식에 따라 달라짐. 소프트웨어를 건드리는 것이 아닌, 하드웨어적인 최적화를 통해서 성능을 높였다면 Microarchitecture를 개선한 것.
Microarchitecture와 관련있는 개념이 무엇인가?
- CPI : 하드웨어 측면에서는 우수함을 평가하는 척도는
clock cycle(하드웨어 측면에서는 clock frequency는 크게 중요하지 않다고 생각함) 그래서 CPI를 줄이는 것이 하드웨어적으로 중요한 choice이다.
- ISA : 무슨 ISA를 지원할 것인가에 따라서 내부 구조가 달라짐 (즉 하드웨어를 비교하기 위해서는 어느 ISA를 지원하기 위해 만들어진 것인지를 고려해야 한다.) 예를 들어 Apple의 M2 같은 경우 intel과 ISA가 다르기 때문에 사실 직접적으로 비교가 힘들다.
- Storage formats : 예를 들어 정수인지, 소수인지에 따라서 복잡도가 굉장히 달라짐. 그에 따라 만들어야하는 digital circuit이 달라짐
- CPI : 하드웨어 측면에서는 우수함을 평가하는 척도는
Two types of Digital Circuits
Combinational Circuits
Output values depend only on the current inputs
ex) ALU
Sequential Circuits
Contain state using an internal storage
Can make the states persistent through saving/restoring
ex) Register, Memory
💡
기본적으로 state를 저장하는 것들은 전부다 Sequential Circuit이라고 생각하면 된다.
Implement CPU
Step 0 : Check instructions
크게 보면 우리는 총 5가지의 명령어를 수행하면 된다.
- R-type : 무조건 ALU에 rs, rt값이 들어가서, ALU의 output을 rd에 저장
- I-type
- lw : rs와 imm가 ALU의 input으로 들어가고, ALU의 output을 memory address로 사용함. 그리고 Data memory의 output을 rd에 저장
- sw : rs와 imm가 ALU의 input으로 들어가고, ALU의 output을 memory address로 사용함. 그리고 rt값을 해당 memory address에 저장하게 됨
- beq : rs와 rt가 ALU의 input으로 들어가고, ALU의 zero output을 사용해서 branch여부를 판단하게 된다.
- 나머지 (addi) : rs와 imm가 ALU의 input으로 들어가고, ALU의 output을 rd에 저장하게 됨
Step 1 : Arithmetic Logic Unit
Combinational circuit를 활용해서 ALU를 만든다. ALU의 output값은 input에 의해서만 영향을 받는다.

Step 2 : Inputs/Outputs of the ALU

ALU는 다음 2개의 연산 중 하나를 수행하게 된다.
- Register-register operations : input으로 2개의 register value가 들어온다.
- Register-immediate operations : input으로 1개의 register value와 1개의 immediate가 들어온다.
그러면 어떻게 rt와 immediate 중에 어느 값을 사용할지 결정할 수 있을까?
multiplexer가 필요하게 된다. rs는 무조건 ALU의 input으로 활용이 되고, MUX에 control signal을 연결하여 rt와 immediate 중 어느 값을 ALU의 input으로 활용할지를 결정하게 된다.
ALU의 output은 다음과 같은 용도 중에 하나를 수행하게 된다.
- output을 register에다가 저장
- output을 memory의 address로 활용
💡
Register file : register들이 모여있는 buffer라고 생각하면 된다.
Step 3 : Data Memory
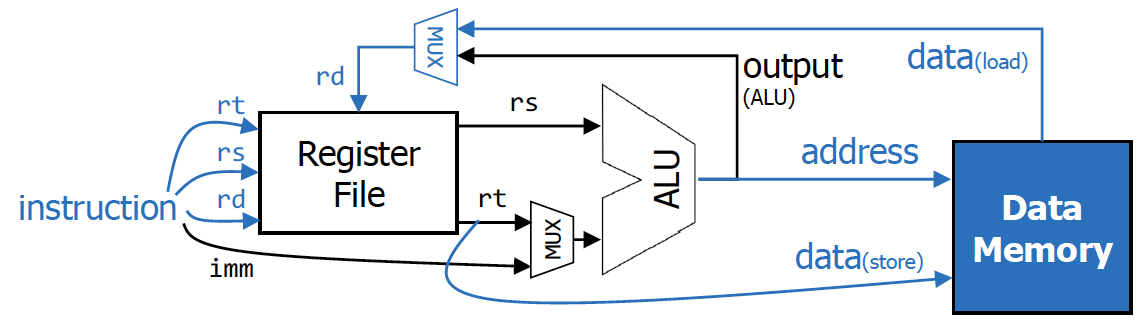
💡
실제로는 stored programming concept이라서 data와 instruction을 같은 공간에 두고 사용하지만, 설명의 편의를 위해 각각
instruction memory와 data memory 라는 것을 도입하였다.Instruction을 통해 rt,rs,rd 값을 통해 ALU에 어떠한 값을 보내줄 것인지를 알 수 있게됨.
Step 4 : Instruction Memory

복잡도를 낮추기 위해서 Instruction memory가 있다고 생각
또한 instruction fetch이후 PC 값이 4증가한다.
Step 5 : Branch-IF-Equal Instruction

branch 명령어들을 지원하기 위해서 등장한 개념
→ 결과적으로 PC 값을 수정해야하는 일이 발생함
💡
정확하게는 $pc = ($pc + 4) + (offset << 2)

💡
위 MUX의 control bits는 ALU의 zero와 branch를 AND gate을 통과한 결과가 들어가게 된다.
Step 6 : Control

💡
Data memory의 경우 control signal이 2개이다. (MemWrite / Memread)
💡
Register쪽에서 읽는 것은 register 번호만 제공하면, 해당 register에 저장된 값이 바로 output으로 나오게 된다. 반면, register를 쓰는 것은
RegWrite이 assert(1)이 되어야만 쓸 수 있다.Steps to Execute an Instruction
Instruction이 실행되는 단계를 총 5단계로 구분할 수 있다.
- Instruction Fetch (IF)
- Instruction Decode (ID)
- Execute (EX)
- Memory Access (MEM)
- Writeback (WB)
각각 하나씩 살펴보도록 하겠다.
Instruction Fetch (IF)

- Instruction memory로부터 명령어를 가져옴
- PC값을 4 증가시킴
Instruction Decode (ID)

- Fetch된 Instruction으로부터 명령어 단위로 parsing
- Control signal 설정
- Source register로부터 값을 읽음
Execute (EXE)

- ALU 연산을 수행한다.
Memory Access (MEM)

- lw 같은 경우는 ALU 연산 결과를 통해 나온 메모리주소에 저장된 값을 읽음
- sw 같은 경우는 ALU 연산 결과를 통해 나온 메모리 주소에 rt값을 저장함.
Writeback (WB)

- lw의 경우는 메모리의 값을 register에 저장
- ALU instruction의 경우(R-type)의 경우는 ALU의 연산결과를 register에 저장
💡
저장되는 register가 어느 register인지도 결과적으로 구분해야 한다. R-type의 경우에는 rd이지만, lw의 경우나 addi의 경우에는 rt이다. 즉 WB을 하는 명령어 중 R-type이면 rd, I-type이면 rt이다.
Adding the Control Unit
Control unit은 instruction을 해석해서 적합한 control signal을 보내줌
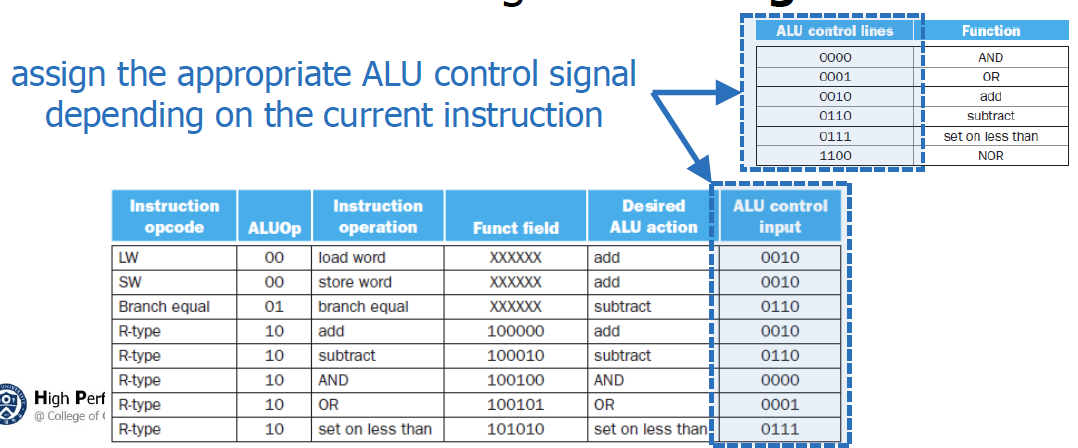
ALU입장에서 어떤 연산을 해야할지 결정하기 위해 control unit 사이에 협약이 필요하게 됨.
→ 즉 ALU가 어떤 연산을 지원하고, 어떤 명령어를 주어야 해당 연산을 수행하는지를 고려해야 한다.
lw, sw가 뭘 해야하는지를 잘 생각해보면, ALU가 덧셈 연산을 반드시 수반해야한다는 것을 인식할 수 있다.
beq 입장에서는 첫번째 input과 두번째 input이 같은지 확인해야 한다.
→ 따라서 두 input을 빼야 한다. (그러면 zero가 1이 될 것)
A Single-Cycle “Processor”

💡
여태까지 다룬 모든 내용이 한번에 들어가있는 그림 (Processor = datapath + control)
instruction[31-26] : opcode
→ 위 내용을 바탕으로 signal을 설정해서 해당하는 unit에 signal을 보냄
ALU control unit은 무엇인가?
opcode에다가 function field까지 고려하는 역할. Control unit은 무슨 type인지만 알 수 있게 됨
→ 그래서 instruciton[5-0]이 ALU control에 꽂혀있는 것
💡사실 무슨 명령어인지 판단하기 위해서는 정확하게는 op와 funct를 다 봐야하는데, op만 보고 Control signal을 만들고, funct는 ALU control에서 판단해서 어떠한 연산을 ALU에서 수행해야하는지 결정하게 된다.
예를 들어 R-type이라는 것만 알아서 RegWrite를 1을 시킴.
→ 즉 rd register에다가 새로운 값을 쓸 것이다라는 의미를 알려줌
ALUSrc가 0이면 Read data2가 들어감. 1이면 immediate가 들어감
Control Signals for the Datapath
opcode를 보고 발생하는 control signal (총 8가지)
RegDst : add $10, $11, $12라고 할 때, 10이라는 값이 RegDst로 들어가게 됨. (5bit짜리 signal)
Branch : branch와 관련되어 있는 연산인지 아닌지 판단 (branch 연산이면 1로 설정)
MemRead : 데이터 메모리의 값을 읽어야 하는 경우 1 (lw)
MemtoReg : MUX에 대한 control signal (register에다가 어떤 값을 쓸 것인지 결정)
ALUOp : ALU가 어떤 연산을 수행해야하는지 결정하는 control signal (4bit)
MemWrite : 데이터 메모리의 값을 써야 하는 경우 1 (sw)
ALUSrc : ALU의 2번째 값으로 들어가는 것이 rt일 것인지, immediate일 것인지 결정
RegWrite : Register file을 write하는 명렁어인지 판단 (write하는 명령어이면 1로 설정)
💡
PCsrc : branch 명령어이냐 아니냐를 판단하는 signal. 정확하게는 PCsrc라는 control signal은 존재하지 않고, ALU의 zero와 Branch control signal의 AND Gate 연산결과를 PCsrc로 사용한다.
Example : R-Type Instructions
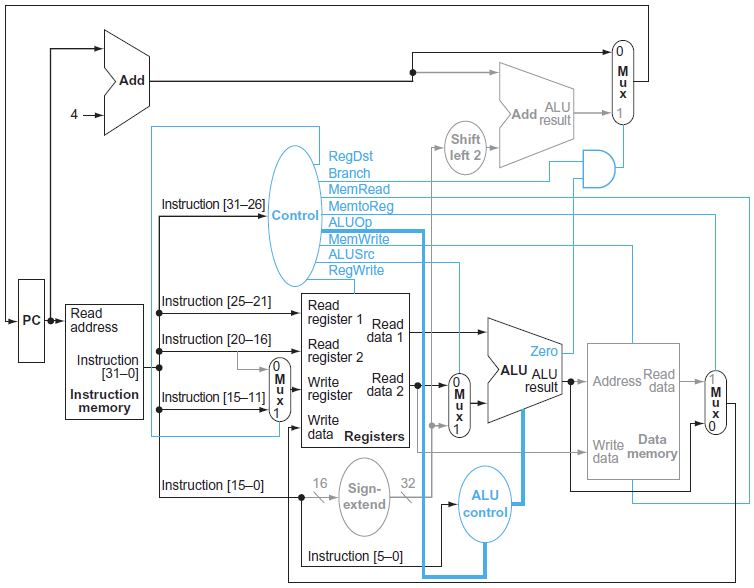
💡
기본적으로 2개의 register 값을 받아서 ALU연산을 거친 뒤, 해당 값을 register에 저장하는 과정을 거치게 된다. 또한 MEM과정은 거치지 않는다.
memory write/read를 0으로 설정
추가적으로 ALU control한테 function field값을 넣어주어야 한다.
또한 immediate파일을 사용하는 것이 아니므로 ALU의 2번째 input을 rt값을 사용한다. (그래서 ALUSrc가 0으로 설정됨)
위에 있는 mux는 pc + 4와 pc + 4 + immediate << 2 중 어느 것을 사용해야하는지를 결정해야 한다. 따라서 branch를 0으로 설정한다.
또한 sign extend의 경우 immediate를 쓸 일이 없으므로 사용하지 않음
Example Load Instructions
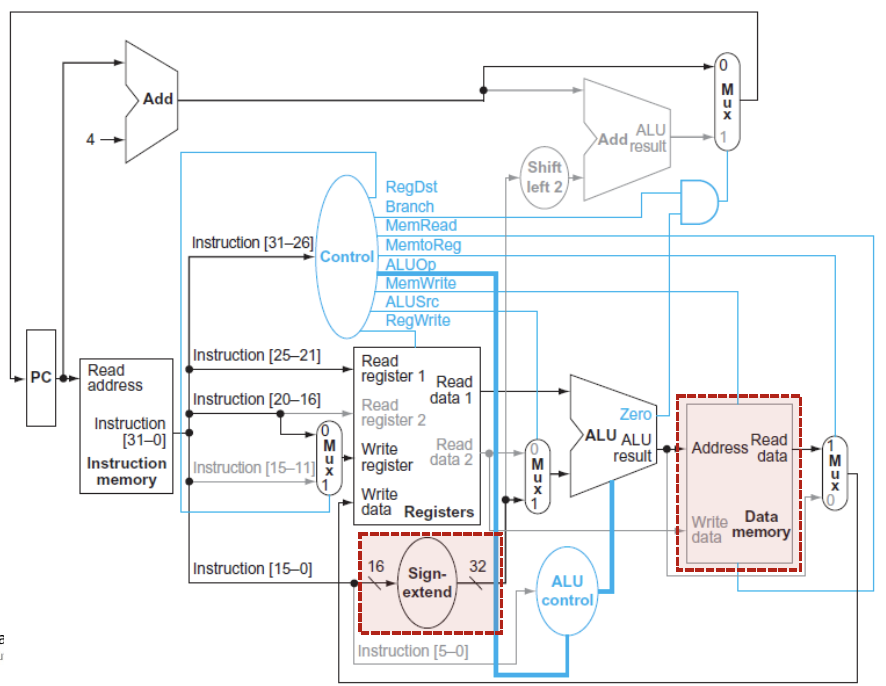
rt 레지스터를 가져오는 것이 아니라 immediate를 써야하기 때문에 ALUSrc가 1로 설정이 됨.
그리고 읽어온 값은 rd에 써야하므로 RedWrite가 1로 설정
추가적으로 Write register가 뭔지를 결정해야한다. (R-type과 I-type의 경우 위치가 다르게 된다.)

추가적으로 ALU control은 function field는 고려하지 않음
→ opcode만 봐도 충분함. (그래서 funct field가 xxxxxx로 표기되어 있는 것)
MemRead는 1, MemWrite는 0으로 설정
→ 이때 데이터의 값을 가져오는 상황이므로 MemtoReg가 1로 설정
Example : Branch-If-Equal

결국 branch에서 중요한 것은 내부에 있는 MUX의 control signal 값이 중요하다.
💡
해당 control signal은 ALU의 zero와 Branch의 AND 연산값이라는 점을 기억해야 한다.
Cons of Single-Cycle Processors
- 모든 명령어가 1개의 cycle이 반드시 걸린다는 점이 문제점
→ lw를 제외하고 절대적으로 필요한 시간이 적음에도 불구하고 모두 다 동일한 시간이 걸리는 것이 문제.
예를 들어 lw가 0.01%를 차지하고, 나머지가 99.99%가 있다고 했을 때, lw가 요구하는 시간에 bound된다는 문제가 존재하게 된다.
💡5단계 다 거치는 명령어는 lw가 유일하다.
- clock period (Clock cycle time)이 증가하면, 연산을 먼저 다 끝냈어도
idle상태에 존재할 수 밖에 없다.→ 다음 rising edge를 기다릴 수 밖에 없으므로 그렇다.
→ 위 과정에서 성능의 손해를 보게 된다. 그래서 등장한 개념이 Pipelining
Pipelining
여러 명령어들을 동시에 실행시키는 것
→ 5단계들은 서로 겹치지 않는다. 그래서 그 영역들을 겹치게끔 해서 시간을 줄이겠다는 것이 목표이다. (각 단계별로 다른 명령어를 실행하게끔 하겠다.)
💡
각 단계에서
쓰이는 자원이 다르다는 것이 위 아이디어의 핵심Doing a Lot of Laundry

💡
위 경우에는 최대 동시에 4개의 빨래를 진행할 수 있음
각 단계별로 clock signal을 줘야 한다.(하드웨어는 signal을 기준으로 작업을 수행할 수 있으므로)
→ 즉, clock frequency가 증가되게 됨. (즉 한 clock당 1개의 단계가 수행되게끔)
pipelineing은 throughput은 증가, latency는 변화하지 않음
(단위 시간당 처리할 수 있는 명령어의 개수는 증가하지만, 각 명령어를 실행하기 위해 걸리는 시간은 바뀌지 않음)
💡
Pipelineing은
throughput 관점에서는 굉장한 이점이 있음. 명령어가 걸리는 시간은 바뀌지 않음 (시험 출제될 듯?)
IF : Instruction
ID, WB : Register
EX : ALU
MEM : Memory
왜 ID와 WB가 동시에 Register를 쓰는데 문제가 안생기는지?
1개의 cycle을 나눔 (0 → 1로 바뀔 때, 1 → 0으로 바뀔 때 전부 다 signal을 사용할 수 있게끔으로 수정)
그리고 ID는 후반부 clock에 쓰고, WB는 전반부 clock에 쓰게끔
위 trick을 통해 conflict를 피하는 것
일반적으로 clock 중 앞을 쓸 것인지 뒤쪽을 쓸 것인지에 대한 convention
저장하는건 앞쪽, 읽는것은 뒤쪽. IF, ID는 읽는 것이므로 뒤쪽 clock에 사용하는 것. WB는 써야하므로 앞쪽
💡
ALU는 1cycle을 다 쓴다고 가정
Benefits of Pipelining
계산의 편의를 위해서, 각 stage가 실행되는데 걸리는 시간이 같다고 가정. 또한 계산의 편의를 위해 앞, 뒤에 존재하는 것은 무시
→ 그래서 전체 instruction을 state의 개수로 나누게 됨.
그래서 시간을 줄이려면 state의 개수를 늘리면 됨
→ 명령어의 실행을 잘게 작을 수록 throughput은 늘어남. (명렁어를 실행시키는데 걸리는 시간은 똑같음)
최신 cpu의 경우 30stage정도로 굉장히 나눠 놓음
💡
Pipeline의 결과 최대 IPC는 1이다.
Not perfectly balanced

clock period : 200ps/clock
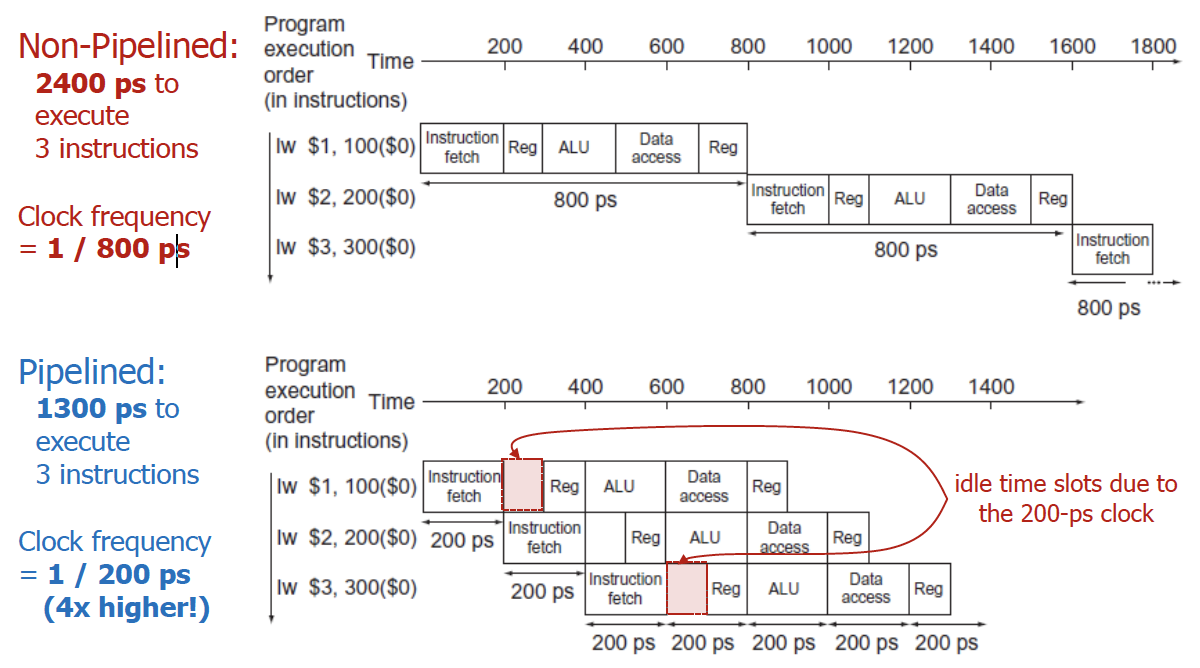
Pipeline을 하지 않게 되면, 제일 오래걸리는 것을 기준으로 bound된다. 그래서 800ps에 bound된 것.
💡
추가적으로 single cycle의 경우에는 과목 취지상으로는 lw의 execution latency는 800ps, sw의 execution latency는 700ps라고 답하는 것이 맞다. 추가적으로 pipeline의 경우에는 과목 취지 상 제일 긴 200ps * 5 = 1000ps라고 답변을 해주어야 한다.
💡
Pipeline을 하게 되면 제일 긴 연산을 기준으로 bound된다. 100ps에 끝나는 연산도 있지만, 200ps인 연산도 있기 때문에 200ps에 bound되는 것이다.
Write과 Read를 동시에 하는 것을 막기 위해서 Reg는 뒤쪽에 일을 하게 되었음.
→ 전부 다 pipelining을 그려보면 전부 다 씀
근데, pipeling을 하려고 보니, 대기 시간이 생겼음.
이 문제 때문에 한 명령어를 실행하는데 걸리는 시간이 더 오래걸림
💡
Write와 Read를 동시에 하는 것을 막기 위해서 idle time을 중간에 줘야하는 문제가 생김. 이 때문에 latency는 일반적으로 같거나 증가하게 됨
즉 latency를 희생하더라도, throughput을 증가시키는 것.
추가적으로 pipelineing의 장점은 clock frequency를 증가시킬 수 있다는 것. (Stage를 처리하는데 필요한 시간 중 제일 큰 것으로 줄일 수 있게 된다.)
Implementing Pipelining
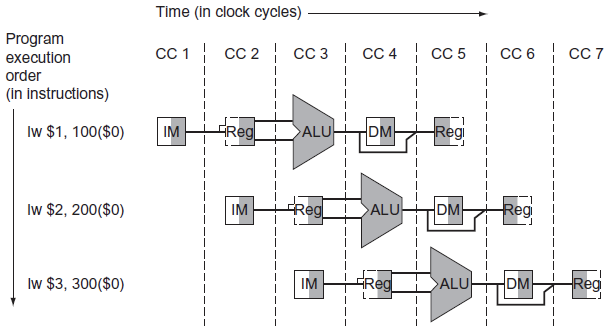
Step 1 : Datapath를 재배치

💡
WB stage에도 Register를 건드리게 되는 점을 주의해야 한다.
위 그림에서 pc+ 4 + (imm << 2)가 왜 EXE 단계에 있는지 의문을 가질 수도 있다. 그 이유에 대해 살펴보자면 다음과 같다.

- IF로 아직 당겨올 수 없음. (어떤 명령어인지 아직은 모르는 단계)
- rs, rt 명령어를 기준으로 beq연산 여부를 처리해야하므로 ID로 뺄 수 없음 (즉 해당 정보는 ID가 끝나야 알 수 있다.)
→ 실질적으로 MEM까지 가야 beq여부를 처리한다. ALU의 연산을 기준으로 PC + 4 + immediate << 2 를 쓸 것인지, PC + 4를 쓸 것인지를 결정하게 됨. 해당 정보는 IF로 넘어가게 됨.
Step 2

Datapath가 하나의 명령어를 실행하는 것이 아니므로, 5개의 명령어에 대한 정보를 들고 있어야 한다.
→ 해당 정보를 가지고 있기 위한 하드웨어 구조는 latch이다.
→ 임시로 값들을 저장해두는 역할을 수행함.
만약 latch를 쓰고 clock마다 초기화된다면, 이전에 대한 정보들이 다 날아가는 문제점이 발생하게 된다. 그래서 control signal을 중간중간 저장할 필요가 존재한다.
latch는 pipeline state간에 정보를 저장하는 역할을 수행한다.
→ 각 pipeline이 제대로 수행하기 위해 필요한 데이터들을 latch에 저장해둠 (즉 해당 pipeline에 필요한 정보가 latch에 다 있다. signal 이런것도 전부 다. 정확하게는 이후의 pipeline에서 써야하는 input값도 다 저장해둔다.)
IF는 없어도 되는게, Instruction memory로 부터 바로 불러오기때문에 latch의 역할을 대신 수행해주고 있다고 생각해주면 된다.
Executing lw on the Pipeline
Instruction Fetch state
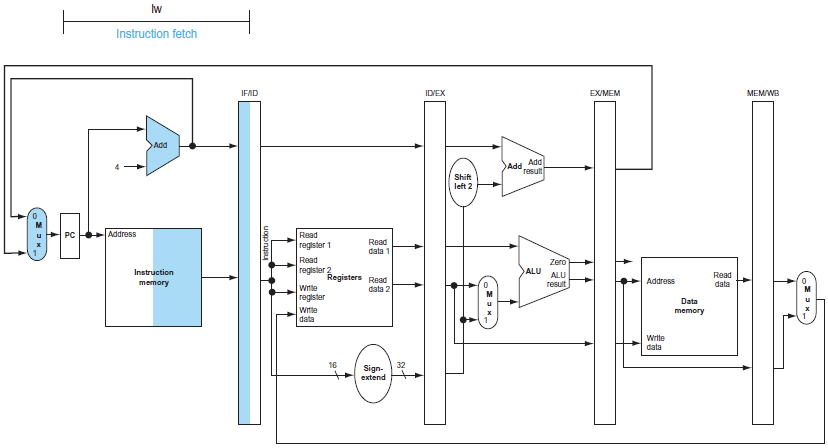
명령어와 PC + 4값이 latch에 바로 저장해둠
→ 만약 branch 명령어를 결정하기 위해서는 PC + 4값이 필요하므로, 미리 백업해둠.
추가적으로 Latch의 경우에도 문제가 발생하게 된다.
→ 읽는 친구와 쓰는 친구가 동시에 발생할 수 있다.
사실 이 부분은 고려하지 않아도 됨.
→ 데이터를 읽는 행위는 clock이 시작할때쯤, 쓰는 행위는 clock이 끝날때쯤에 발생하므로 문제가 발생하지 않는다.
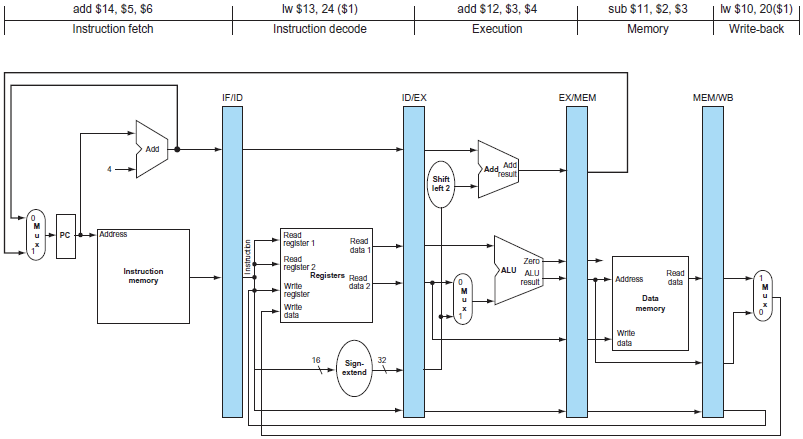
정리해야할 점
- 무조건 Decode 단계가 끝날 때 어떤 명령어인지 안다고 생각해야 한다.
→ 즉, Execute 단계에서 필요할 수도 있는 정보들은 전부 다 latch에 넘긴다고 이해해야 한다.
- beq의 경우에는 naive하게 돌아가지는 않는다. 정확하게는 branch를 탈지 말지는 memory access 단계에서 결정하게 되는데, pipeline상 바로 이전의 명령어는 이미 execute단계에 있기 때문에 모순이다.
→ 중간고사때 교수님이 언급하셨던 것처럼 불필요한 명령어를 둠으로써 해결할 수 있다.
💡실체적으로는 beq 명령어가 등장하게 되면 쉬도록 강제하는 방향으로 진행하기도 한다.
- Execution process는 1개의 cycle을 전부 다 사용한다고 가정
Pipeline Hazard
이상적으로는 IPC는 1를 달성할 수 있다.
💡
이 측면에서는 single-cycle instruction과 동일하다.
→ 1초 내에 몇 개의 명령어를 끝낼 수 있는지를 고려해보면, pipeline을 사용하면 5배까지 늘릴 수 있다.
하지만, 반드시 그렇게 될 수 없다. hazard때문.
→ Pipeline hazard가 발생하면, 특정 cycle 동안에는 매 사이클에 명령어를 수행하지 못하게 된다. (이 경우에는 IPC가 1보다 더 작아짐)
💡
당연하게도 hazard가 발생하지 않은 경우에는 IPC는 1이다.
hazard에 의해서 pipeline이 stall된다고 표현한다.
예를 들어, 1000개의 instruction을 실행했어야하는데 600개밖에 실행시키지 못한 경우에는 400개가 stall이다.
Definition
Stall : the clock cycles which a pipeline state cannot execute the next instruction
Hazard : the situation which incur pipeline stalls
Structural hazard
현실에서는 floating point operation의 경우 상당히 overhead가 크다. 즉, 복잡한 arithmetic operation은 1cycle내에 끝내지 못한다. (대략 10cycle정도 걸린다.) 즉 EXE를 끝내는데 10cycle이 걸리는 것. 이러한 HW의 충분한 resource가 있지 않아서 매 clock cycle마다 instruction을 끝낼 수 없는 상황. 추가적으로 IF와
💡
HW를 잘 만들면 위 문제를 극복할 수 있긴하다.
Data hazard (Read After Write dependency)
Data dependancy로 인한 hazard
ex) add $t2, $t0, $t1 → sub $t4, $t2, $t3 (이 경우는 read after write이다.)
앞에 t2가 업데이트되는거는 WB단계인데, rs와 rt는 Decode의 후반부에서 latch에 넣음
→ 그래서 add의 WB과 sub의 Decode state를 맞춰줘야하는 문제점이 발생 (이렇게 되면 IPC가 1이 될 수 없음)
add의 WB와 sub의 ID를 맞추면 문제가 생기지 않나?
생기지 않는다. WB이 초반부 cycle에 진행되고 ID는 후반부 cycle에 진행되기 때문에 괜찮다.
해결방법
사실 생각해보면 WB할 때까지 기다릴 필요가 없다. t2에 저장될 값은 EXE 단계가 끝나면 이미 가지고 있다. 따라서 해당 값을 처리하자마자 sub의 input으로 주면 stall 시간을 단축시킬 수 있다. 이처럼 추가적인 하드웨어를 집어넣어서 미리 정보를 받는 받는 것을
forwarding혹은bypassing이라고 한다.
Control hazard
사실 미리 고민했던 문제
beq의 MEM와 그 다음 instruction의 F를 align을 해야한다.
→ 그 과정에서 2 cycle이 stall이 발생한다.
💡
정확하게는 MEM의 첫번째 half cycle에서 PC register값을 업데이트 한다고 생각해야 한다. 그래야 2번째 half cycle에서 해당 PC값을 읽어서 대응되는 instruction memory값을 가져오게 된다.
그러면 4cycle동안 2개가 끝나므로 IPC가 1/2로 줄어든다.
💡
PC register에 대한 Read-After-Write dependency를 가진다고 이해해도 된다.
Data Hazard
발생하는 근본적인 원인이 무엇인가?
앞에 실행되는 명령어의 destination register를 쓰려고 하기때문에 발생
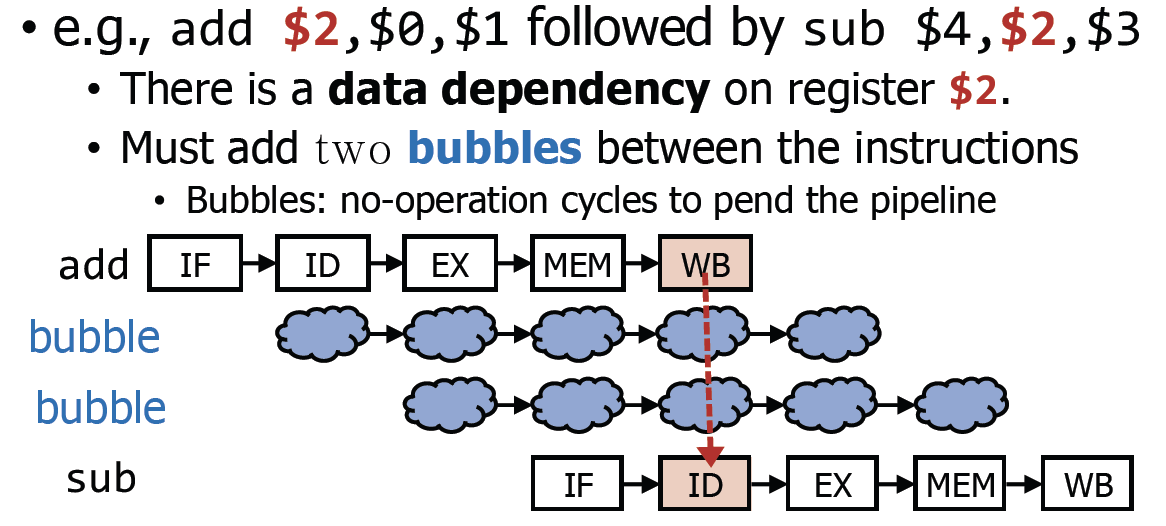
Bubble은 어떻게 만드는가?
add $zero, $zero, $zero
→ 사실 bubble이라는 것은 어렵게 생각하지 말고, 어떤 동작을 하는데 사실 크게 고려하지 않아도 되는 것이다. Latch에 control signal부분을 전부 다 0으로 만들어주면 메모리를 읽지도, 쓰지도 않는 상황이므로 크게 고려하지 않아도 된다.
그래서 Bubble을 중간에 끼워넣어야 한다.
Read Write dependency가 있는 경우 2개의 bubble을 넣어주어야 한다.
Resolving Data Hazard

위 과정 때문에 2개의 idle이 발생하게 된다.
그래서 하드웨어 최적화 기법이 등장함
Data forwarding (혹은 data bypassing이라고도 불림)
사실 넣은 bubble만큼 performance가 떨어짐

사실 잘 생각해보면 계산 자체는 EXE가 끝날 때부터 latch에 존재한다. 이걸 활용해서 bubble을 없애보자는 것
→ 만약 sub의 ID에서 값을 저장할 때 add의 EXE 후의 ALU가 생성한 값을 저장하면 어떨까?
Data forwarding을 활용하면 bubble이 필요없을까?
Nope

위 경우에는 반드시 bubble을 1개 넣을 수 밖에 없다. (EX가 필요로 하는 데이터는 MEM이 끝나야 생성되므로)
이거를
load-use data hazard라고 부른다.💡
Data Forwarding in Hardware

위 예시에서는 sub와 and/ sub와 or사이의 data dependancy가 존재하는 상황
→ sub의 ALU가 생성해낸 값을 rs/rt 모두 다 넣어줄 수 있어야 함
→ 즉 ALU의 2가지 input 모두로 다 들어갈 수 있게끔 해야 한다.
→ 그래서 앞에 MUX를 하나 붙어야겠다. (즉 이전의 MUX의 결과값이 하나의 input으로 들어갈 수 있게 된다는 점이 바뀌게 된다.)
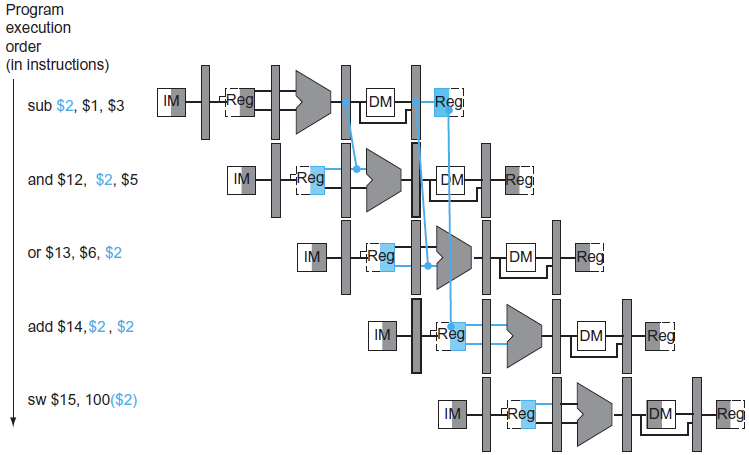
EXE/MEM latch와 MEM/WB latch에서 forwarding할 필요성도 존재하게 됨
이유가 무엇인가?
- EXE의 결과를 가져오는데, 2단계 이후까지 가져올 수 있어야 한다는 점에서 EXE/MEM latch와 MEM/WB latch에서 forwarding해야한다.
- load-use data hazard의 경우는 메모리로부터 값을 가져와야 하기 때문에 해당 정보는 MEM/WB에 존재한다.
즉 3개의 서로 다른 latch를 input으로 넣을 수 있어야 한다.
💡
4, 5번째 명령어는 data forwarding을 할 필요가 없다. 실질적으로 앞에 2개의 bubble이 이미 들어가 있는 형태이다.

어느 값을 쓸 것인지를 어떻게 판단할 것인가?
Forwarding unit이 담당
그렇다면 해당 unit은 어떤식으로 판단하는가?
잘 보면 Forwarding unit은 rs와 rt의 주소와 EX/MEM에 대응되는 명령어의 rd 주소 및 MEM/WB에 대응되는 명령어의 rd 주소를 확인하고 있다. 이 값을 기준으로
ForwardA와ForwardB값을 결정할 수 있게 된다. 정확하게는 Latch의 WB에 해당하는 데이터를 살펴보면 된다. 거기에 rd에 대한 값이 저장되어있다.
추가적으로 MUX가 3개의 input이 있으므로 ForwardA와 ForwardB는 2개의 bit이다.

WB에 에 대한 정보가 Forwarding unit에 계속 들어감
→ 사실 생각해보면 destination register에 대한 정보가 WB에 다 들어가있으므로 dependancy를 판단하기 위해 필요한 정보는 WB에 들어가 있다. (정확하게는 rd값을 수정했는지에 대한 정보가 WB에 들어가있다.)
💡
EX/MEM의 regWrite과 MEM/WB의 regWrite가 Forwarding Unit에 들어간다. 즉 Write back을 수행하는 명령어 여부는 해당 control signal을 통해 알려주게 된다.
Exact procedure

- destination register에 값을 쓰는지 여부를 체크한다.
(sw/branch는 안씀)
- 근데 그 register가 zero가 아니어야 한다.
- rd와 일치하는지 체크 (각각 ALU의 first, second input을 비교)
그런데 이런 상황이 존재할 수 있다.
만약, EX/MEM에 있는 rd 주소와 MEM/WB에 있는 rd 주소가 현재 ID/EX에 있는 rs나 rt값이 동시에 같은 경우가 발생하면 어떻게 될까?
다음 내용을 참고하도록 하자.
Detecting MEM Hazard

위 경우에는 2가지 모두 다 고려해야 한다
→ 둘 중에 무엇을 가져와야하는지를 결정해야 한다.
💡
사실 이 경우에는 가까운 쪽 데이터를 가져와야 한다. (이게 프로그래머 입장에서 naive한 접근이므로)


💡
가까운 쪽도 같은지를 체크하는 과정을 거치게 됨 (EX/MEM에 있는 것을 priority를 주겠다는 것)
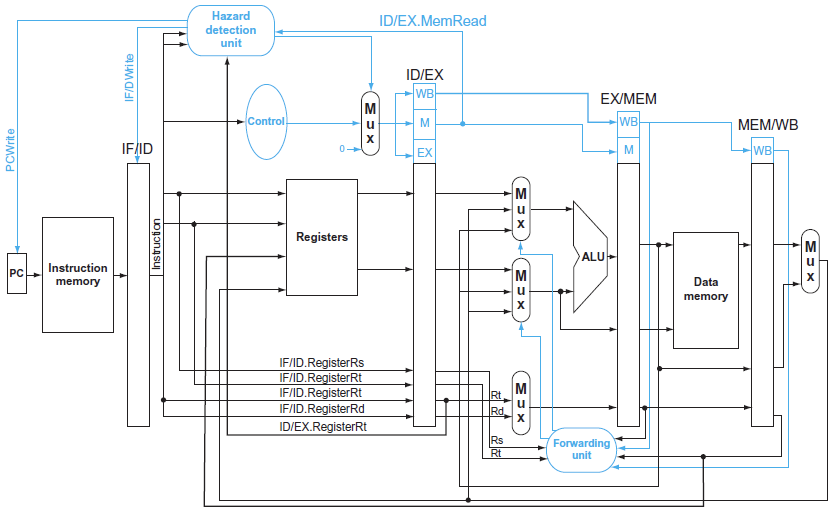
Procedure (load-use data hazard detection)
- ID/EX MemRead : 해당 값이 0인지 1인지를 본다. lw라면 해당 값이 1일 것이다.
→ 이 값을 보고 바로 직전의 명령어가 lw 명령어라는 것을 판단할 수 있게 된다.
더 전에 볼 수는 없는지
불가능하다. ID가 끝나야 어떤 명령어인지 판단할 수 있기 때문이다.
- destination register가 rs나 rt값에 해당하는지 체크해야함
→ 그래서 Hazard detection unit에 rs와 rt값이 들어가게 됨
→ 그리고 ID/EX latch에 있는 rt를 체크해야한다. (lw이므로 I type이라 destination register가 rt에 들어가 있다는 점을 유의해야 한다.)
- 여기까지 정보를 토대로 load-use hazard가 발생했는지 여부를 판단할 수 있다.
- 일단 그 다음으로 오는 명령어가 IF가 실행되는 것을 반드시 막아야 한다.
→ pc register가 pc + 4로 되는 것을 막아야 한다
💡정확하게는 add의 IF를 거치면 이미 +4로 넘어가 있기는 하지만, 그 다음에 바뀌는 걸 막는 것예를 들어 add 명령어가 실행시킬 때 pc값이 1004라고 하면, IF 명령어가 끝났을 때 이미 pc는 1008로 바뀌어 있다. 우리가 하고자하는 것은 1012로 바뀌는 것을 막고 싶은 것
→ 그래서 그걸 막기 위해서 필요한 값이 PC/Write. 해당 값이 1일때만 PC값을 업데이트하게 된다.
💡0x1000 → 0x1004 → 0x1008 → 0x1008 로 pc값이 바뀌는 것즉 사실상 sub에 해당하는 IF를 2번 수행하는데, 맨 처음의 과정에서 PC값이 +4가 되는 것을 PC/Write가 0으로 설정함으로써 막고, IF/ID latch를 업데이트 하는 것을 IF/ID write control signal을 0으로 설정함으로써 막는다.
lw F D E M W
add F D E M W
sub F F D E M W (PC값을 업데이트 하는 것을 막았으므로 동일한 F를 2번하게 되는 것이다.)
💡
사실상 add에 해당하는 F 뒤에 아무것도 하지 않는다는 것은 WB, M, EX에 해당하는 bit를 전부 다 0으로 만든것. 이 때문에 memory를 읽지도 않고, 쓰지도 않으므로 그냥 뻘짓을 하는 것이다.
Control Hazard

💡
MEM의 첫번재 half cycle에서 PC값을 업데이트한다. 그래서 MEM과 F를 align시켜주면 된다는 것이다.
💡
F는 cycle의 후반부에 정보를 읽기떄문에 align시킬 수 있다.
사실 근데 생각해보면,
- rs와 rt에 들어있는 값이 같은지 여부
- branch 여부
- immediate
위 3가지 정보 전부 ID에서 얻을 수 있는 것들이다. 단, 1번을 처리하기 위해서 같은지를 판단하는 장치를 ID로만 옮겨주면 된다.
💡
제일 중요한 지점은 이렇게 해도 반드시 1개의 bubble은 들어간다는 것이다. 결과적으로 pc를 업데이트하기 위해서 필요한 정보들은 ID가 거의 끝날때쯤 준비된다. 즉, 1cycle의 거의 후반부쯤이다. 이 상황에서 IF는 이미 PC register에서 PC값을 읽었기 때문에 문제가 발생한다. 따라서 반드시 1개의 bubble은 들어야한다.
그래서 beq 뒤에 1개의 명령어가 반드시 실행되는 것을 MIPS에서는 강제하였다.
💡
즉, user입장에서 강제로 bubble을 반드시 넣어주는 것을 강제한 것
→ 이를 branch delay slot이라고 부름.
💡
이건 MIPS ISA의 특징이다.
그래서 이게 아까우니까 branch를 탈까/안탈까를 예측하고 예측하고자 하는 것
→ 이를 branch prediction이라고 함
이걸 써서 성능을 개선함
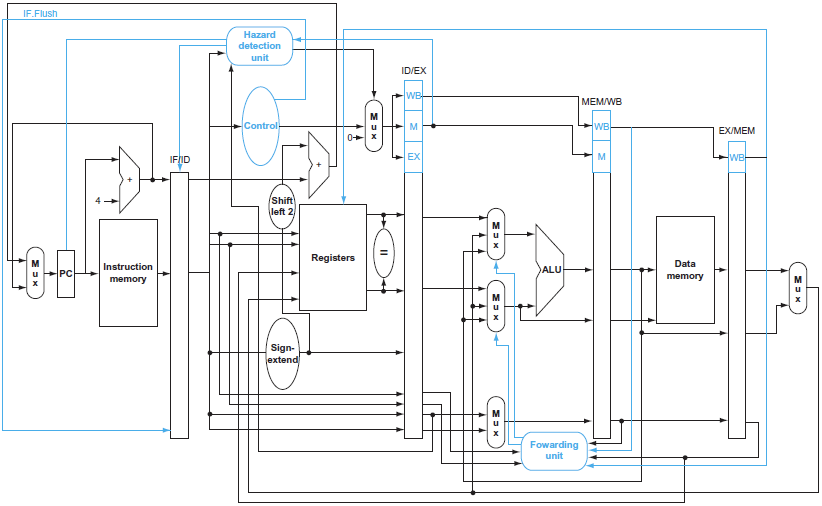
다 반영된 것
→ ID에서 branch 판단이 끝나도록 다 반영이 된 것
반응형
Contents
소중한 공감 감사합니다