Computer Science/Computer Architecture
2. Instructions : Language of the Computer
- -
728x90
반응형
MIPS : A PL for MIPS CPUs
MIPS is an ISA defining all sort of things of a CPU
MIPS is a PL for specifying what the CPU should do.
- Programming model & paradigm
- Syntax
- Semantics
Programmer-Visible State (PVS)
Programmer visible state refers to the set of data that can be accessed and modified by a programmer within a computer program. This includes variables, objects, and other data structures that are explicitly declared or defined within the code.
MIPS의 특징
Imperative programming
: 명령어들을 써서 CPU의 상태를 바꿔가는 식으로 진행하는 프로그래밍 (Declarative programming과 반대되는 개념)
Imperative programmingIn computer science, imperative programming is a programming paradigm of software that uses statements that change a program's state. In much the same way that the imperative mood in natural languages expresses commands, an imperative program consists of commands for the computer to perform. Imperative programming focuses on describing how a program operates step by step,[1] rather than on high-level descriptions of its expected results. https://en.wikipedia.org/wiki/Imperative_programming
https://en.wikipedia.org/wiki/Imperative_programming
- All instructions are executed sequentially
MIPS의 PVS는 무엇인가?
- A CPU core
- Registers
- Memory
Load-store architecture

메모리에 직접 접근이 안되고, 프로그래머 입장에서 무조건 명시적으로 load, store를 써서 메모리와 레지스터 사이의 이동을 지정해야함. (레지스터는 32개밖에 없음)
→ Memory access / ALU operations로 나뉨
3개의 operand를 가짐
Bits & Data Sizes
💡
메모리 주소는 byte단위로 넘어간다.
What is word? and what is the size of word?
One word in computer architecture refers to the natural unit of data used by a particular computer architecture or processor. It typically refers to the
maximum amount of data that a processor can handle in a single operation, such as a single instruction or a single memory access.
- ISA 차원에서 Data size를 결정
- Unsigned와 Signed의 최댓값이 다른 것 주의
- 메모리의 크기는
byte(0부터 시작) ( word)왜 메모리의 크기가 byte일까?
주소값을 표현할 수 있는 비트수가 32개이므로, 0 ~ 만큼의 주소 범위를 가질 수 있음

- 레지스터는 32개 존재 (이 중 몇 개는 special 목적으로 사용)
- 바이트 단위로 메모리 access가능하다.
- 일반적으로 MIPS는 읽어올 때
4byte단위로 읽어온다.
만약 특정 bit만을 포인터를 하고 싶은 경우는?
특정 byte를 다 읽고, 어디까지 읽을 것인지를 추가적으로 해당

레지스터는 이름을 따로 부름 (zero 레지스터는 무조건 0으로 만듦)
(이름은 쓴다는 것은 어셈블리 레벨에서 이름을 쓴다는 것. 실제 바이너리 machine code에서는 숫자로 어차피 바뀜)
→ 메모리의 인덱싱 단위는 Byte (그래서 Memory[0]의 다음 word는 Memory[4])
MIPS : Data Placement
[Byte Order 바이트 오더] 빅엔디안(Big Endian)과 리틀엔디안(little endian) - 1편
안녕하세요~~!! 오늘도 시작되는 말랑이몰랑이 블로그 포스팅입니다~ ㅎㅎ 오늘은 네트워크나 통신쪽을 공부한다면 알고 있어야 할 Byte Order 의 빅엔디안과 리틀엔디안에 대한 개념을 완전하게 잡아보는 시간을 가져보도록 합시다. 시작하기 전.. 우리나라 책은 왼쪽에서 오른쪽으로 읽죠? 지금 여러분이 읽고 있는 블로그처럼요~ 그런데, 혹 일본 만화책을 읽어본 경험이 있으신가요? 일본만화책을 읽을 때는 오른쪽에서 왼쪽으로 읽어요. (dave님 오타지적 감사드립니당~) 이렇듯, 국가별(?)로 읽고 쓰는 방식이 다른데, 컴퓨터도 마찬가지입니다~~! 컴퓨터도 결국에는 메모리에 써져있는 어떤 이진수의 데이터 값들을 읽어서 판독하고 이해하는거잖아요~~ 우리가 왼쪽에서 읽어야 한다, 오른쪽에서 읽어야 한다 등의 모두..
 https://jhnyang.tistory.com/172
https://jhnyang.tistory.com/172
Little endian과 Big endian을 따질 때, 1Byte는 최소 단위이다. 즉, 1Byte 내부적으로는 딱히 구분하지 않는다. (1byte 내부적으로는 little-endian을 따르고 있음)
Big-endian과 Little-endian의 정확한 정의는 무엇인가?
데이터를 읽고 쓰는 기준
이름이 이렇게 불리게 된 이유
비트 기준으로 높은(큰) 친구가 낮은 주소부터 시작되어서 Big-endian이라고 부름
반대로 낮은 친구가 낮은 주소부터 시작되는 것을 Little-endian이라고 부름
big-endian과 little-endian 중 어느 것이 선호되는가?
Modern computer architectures process the
lowest address first. In Little Endian format, the least significant byte of a multi-byte value is stored at the lowest memory address, and the most significant byte is stored at the highest memory address. This means that the computer reads the data in the same order that it is stored in memory, starting with the least significant byte.
Big-endian의 정의

낮은 주소에 큰 bit들이 오는 경우
Little-endian의 정의

낮은 주소에 작은 bit들이 오는 경우
MIPS : Two key Principles
Instruction과 data는 구분되는가?
메모리에 Instruction과 data를 둘 다 저장해둠! 명령어와 데이터가 둘 다 똑같은 데이터 다 라는 생각을 하게 됨. 프로그램 안에 명령어와 데이터가 있지만, 둘 다 컴퓨터 입장에서는 0과 1로 인코딩 된 대상에 불과하기 때문

instruction의 경우 register에 올려놓을 필요가 없음.
(일반적으로 프로그램을 수정하는 것이 아니기 때문) >
MIPS : Design Principles
- Simplicity favors regularity : 최대한 ISA를 만들고 싶은 것. 모든 data나 instruction은 패턴을 가져야한다. 이에 따라 모든 명령어는 32bit의 크기를 가짐. 레지스터도 마찬가지로 32bit (4byte)
- 정확히 3개의 operand를 가짐
- Smaller is faster : CPU안에 있는 register의 크기를 키우면 속도가 느려짐. 접근 시간이 증가하는 것 때문에 속도가 느려진다고 생각하면 된다. 그래서 32개의 register만으로 해결하고자 하는 것.
- Good design demands good compromises : 동일한 instruction format을 포기하는 대신, 동일한 길이의 instruction을 보장 (즉, 모든 것을 다 동시에 좋게 하기 힘듦)
MIPS : Instructions
- 기본적으로 3개의 Operand를 가짐
- 기본적으로 3개의 operand 중 맨 앞이 destination register이다.
💡
store 명령어 같은 경우, 맨 앞이 destination register가 아니라 source register라는 점을 주의해야 한다.
- Data transfer같은 경우 data의 사이즈가 중요한다.
1. Arithmetic instruction
💡
2개의 input operand와 1개의 input operand로 구성됨 / 메모리에 access 불가능
32개의 레지스터를 사용 (단, 모두 다 사용할 수 있는 것은 아니고 1, 2개 정도만 input으로 받을 수 있음)
항상 새로운 값이 생성되고, 해당 값을 1개의 register에 저장.
사칙 연산 생각하면 됨
어떻게 읽어야 하는가? (매우 중요)
과 를 더해서 에 저장한다.
(항상 앞에는 destination register가 나옴, 뒤의 2개는 input이다. 뒤 2개는 source register라고 부른다.)
레지스터를 1개만 읽는 경우도 존재함.
해당 insturction에서 상수를 뭐라고 부르는가?
immediateex : addi (t_0 : destination register, t_1 : source register)
→ 20이라는 명령어에 내재된 숫자를 더하라는 의미
그래서 add”i” 라고 부르는 것
2. Data transfer instruction
💡
Data transfer의 기준은 byte 단위이다. 즉 byte 단위로 메모리에 접근 할 수 있고, 주소 또한 바이트 단위로 구획되어 있다. 사실 일반적으로 1word (4byte) 단위로 움직인다. (왜냐하면 레지스터의 크기가 32bit이므로)
Data transfer가 왜 필요한가?
Arithmetic instruction은 32개의 레지스터만 접근이 가능하다. 즉, 이렇게 되면 큰 양의 데이터를 다룰 수 없게 된다. 그래서 레지스터와 메모리 사이의 data transfer가 필요한 것.
특징
반드시 Data transfer에서는 이동할 데이터의
size를 명시해야 한다.ex) lw: load word (특정 메모리주소부터 4byte를 레지스터로 옮기는 명령어)
base-register라는 개념을 도입하고, 해당 base-register로부터 offset을 더한다. (왜냐하면, 단순히 주소값을 표현하면, 32개의 bit를 전부 다 사용해야하므로 base-register를 기준으로 얼마만큼 움직이는지를 고려한다.)
ex ) : 가 base register이다.

sw $s1, 20($s2) : 여기서 s1은 destination register가 아님 (직관적으로 생각해봐도 이상함) 그럼 뭐임?
store 명령어들에 한 해서 맨 앞에 등장하는 것은 destination register가 아니라 source register이다.
# Assume that $s1 contains the value 100 # and $s2 contains the value 0x80000000 # The instruction below stores the value in $s1 to memory address 0x80000014 sw $s1, 20($s2)
load half : 16 bit만 옮기는 것
double word에 관련된 명령어는 없음 (따라서 load나 store에서 가장 큰 명령어 단위는 1word)
MIPS : Instruction Format
어셈블리 코드를 binary machine code로 바꿀 때 필요한 규칙
규칙들 중 첫번째 : Instruction format
32개의 bit에서 각각의 0,1이 무슨 역할을 하고 있는지 이해해야 한다. 구분할 수 있는 기준이 instruction format

32개는 field로 나뉘고, 각 field가 담당하는 역할이 존재
각각의 역할
op : opcode, 어떤 operation을 하고 있는지에 대한 정보
rs : source register 1번째
rt : source register 2번쨰
rd : destination register
shamt : shift를 얼마나 할 것인지.
funct : opcode에 존재하는 것 중 정확히 무엇이냐
즉, 19페이지가 중요 (Source register와 destination register가 같을 수 있다.)
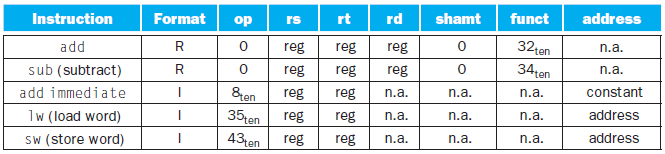
여기에서 Format이 무엇일까?
사실 6 5 5 5 6으로 쪼개는 것을 R타입으로 나누는 것
I타입이면 쪼개는 기준이 달라짐.
MIPS : Instruction Types
왜 3가지 종류의 instruction type이 존재하는가?
뒤에 나오는 operand의 타입이 다름. 이에 따라 찢기는 기준도 달라짐.
종류
- R : Two source register & one destination register (shift operation은 예외)
- I : One source register, one destination register, one immediate
- J : Jump (IF/else)

총 정리
2줄 요약
- 변환 규칙은 R, I타입 모두 동일하게 앞에 있는 얘를 맨 뒤로 뺀다.
- 기본적으로 맨 앞에 오는 것을 operator의
주체라고 생각하면 좀 더 쉽게 생각할 수 있다. (기본적으로는 맨 앞에 오는 것이 destinatnion register)예를 들어 lw $s1, 20($s2)의 경우는 word만큼 부르는 주체가 s1 (즉, s2 + 20에 해당하는 주소에 담긴 정보를 s1에 저장하는 것)
sw $s1, 20($s2)의 경우는 word만큼 저장하는 주체가 s2 (즉, s1에 해당하는 정보를 s2 + 20에 해당하는 주소에 저장하는 것)
sll $t2, $s0, 4 : s0에 해당하는 정보를 왼쪽으로 4바이트 이동시켜서 t2에 저장 (즉, t2가 destinatnion register로 취급)
R타입
변환 규칙 : 무조건 맨 앞에 있는 얘가 rd로 감
- Case 1 : shift operation (sll, srl) : 레지스터가 1개만 옴
rs는 비워두고, rt만 채움
- Case 2 : Normal case : 레지스터가 총 3개가 옴
맨 앞에 오는 것은 rd에 두고, 나머지 뒤에 오는 것들은 순차적으로 rs, rt에 넣는다.
I타입
변환 규칙 : 무조건 앞에 있는 얘가 rt로 가고, 뒤에 있는 얘가 rs로 간다.
주의 : store에 관련한 얘들만 의미가 조금 다르다. 단, 변환 규칙은 그대로 적용된다.
[MIPS] #1 기초 연산 명령어 정리
MIPS 레지스터 구조 Name Register Number $zero 0 $at 1 $v0 - $v1 2-3 $a0 - $a3 4-7 $t0 - $t7 8-15 $s0 - $s7 16-23 $t8 - $t9 24-25 $gp 28 $sp 29 $fp 30 $ra 31 R-format Instructions opcode (6bit) rs (5bit) rt (5bit) rd (5bit) sa (5bit) funct (6bit) add rd, rs, rt add $t0, $s1, $s2 //$t0 = $s1 + $s2 0 17 18 8 0 32 //opcode rs rt rd sa funct opcode : 0 funct : 32 sub rd, rs, rt sub $t2, $s3, $s4 //$t2 = $s..
https://meeenomino.tistory.com/4
MIPS : Logical Operations
Shift operations (e.g. sll, srl) : R타입임에 주의
Utilize the R-type instruction format
e.g. sll $t2, $s0, 4
shamt : unsigned integer로 저장됨
💡
앞서 설명한 것처럼 source register가 1개밖에 없고, 그래서
rs register 영역을 0으로 비워둔다는 점을 매우 주의해야 한다.Bitwise/Bit-by-bit operations


💡
sll, srl의 의미 : shift left logical, shift right logical
MIPS : Representing Text
1개의 단어를 저장하기 위해서 1개의 byte 가 필요함
→ 그래서 등장한 것이 Load byte, Store byte라는 개념이 등장
Load byte (lb) : I type
ex) lb $t0, 0($sp) : sp + 0번째에 있는 주소에서 1byte만큼의 정보를 들고와서 t0에 저장
→ t0는 rt에 저장, sp는 rs에 저장, 0은 immediate에 저장
💡
이때 들고온 1byte는 $t0의 가장 낮은 주소에 저장된다.
Store byte (sb) : I type
ex) sb $t0, 0($gp) : gp + 0번째 있는 주소에 t0에 있는 값을 저장
→ t0는 rt에 저장, gp는 rs에 저장, 0은 immediate에 저장
💡
정확히는 $t0의 가장 낮은 주소에 저장된 1byte값을 메모리에 저장함
Conditional Branches
branch 명령어의 실행결과에 따라서 그 다음 실행될 명령어가 달라짐
요즘에는 좋아져서 Label을 지정해둘 수 있음
(MIPS에서는 이것을 지원해서 레이블링을 통해서 jump를 할 수 있다.)
Branch if equal (beq)
마지막 : 점핑 할 레이블(레이블을 사용할 시 2진수로 1-1매핑은 안됨)
beq r1, r2, L1 : r1과 r2가 같으면 L1으로 점핑
(만약 if 코드가 if(r1 ≠ r2)일 경우 beq로 매핑됨)
→ 생각하는 것이 반대여야함 (매우 중요)
사실상 L1, L2는 c에서의 포인터와 비슷한 기능
(어셈블리 레벨에서는 레이블이지만 머신 레벨에서는 포인터랑 다를바가 없음)
Branch if not equal (bne)

사실 점프 2번임 (else 명령어)
- i == j 가 bne로 바뀌는 것 잘 보기
항상 점프를 뛰게 하는 방법
beq zero, zero : 항상 zero register는 항상 0임을 보장할 수 있으므로
Loops
Set on less than (slt) instruction
slt rd, rs, rt : R-type
→ rd값에 저장된 것을 활용해서 beq를 사용해주면 원하는 기능을 수행할 수 있다.
beq로 하면 안됨?
zero register가 있으므로 0과 비교하는 것이 default
slti instruction (I type)
slti $t1, $t2, 1
→ immediate를 사용한다는 점에서만 다름
→ t2 < 1이면 t1에 1을 저장
Case/Switch Statement
1. Replace with a chain of it-then else
2. Indirect branches (jr instruction : R-type)
→ Use a jump register (jr) : value값을 기준으로 어디로 jump를 뛰어야하는지 일종의 hash table을 만들어 놓고 해당 값을 jump register에다가 넣는 것. (jump register는 J타입을 사용)
Supporting Procedure/Functions
One way to abstract multiple operations
cpu입장에서는 함수를 구분하지 않지만, 프로그래밍 측면에서 함수를 사용하는 것이 더 좋기 때문에 지원하는 것.
함수를 지원하게 하려면 순차적으로 명령어를 실행하다가 특정 위치의 명령어를 실행하게끔 하는 기능을 지원해야함. (사실 beq, bne를 사용해서 기능적으로는 가능하지만, parameter도 제대로 넘겨야하고, return해야하는 주소도 관리해야한다는 측면에서는 구분된다.)
Function Calls
레지스터들을 활용해서 함수 기능을 지원함
~ : four argument registers
~ : two value registers to return values (리턴 해야하는 값들이 레지스터에 저장되는 것)
: return address register to store the point of origin
Jump-and-link (jal) : J-type
ProceduresAddress : 레이블과 같다고 생각
왜 굳이 jump and link?
점핑할 뿐만 아니라 돌아와야하는 주소뿐만 아니라 돌아올 주소를 ra에 쓰는 행위까지 하므로
→ jal이 알아서 ra에 알아서 채움 (직접 핸들링할 이유가 없음)
사용방법
jal ProcedureAddress
# Example # quicksoft function call addi $s3, $s3, 1 move $a1, $s3 move $a2, $s2 jal quickSort
Jump register(jr)
함수가 끝나면 jr $ra를 하면 됨.
함수를 호출할 때는 jal, 끝나고 돌아갈떄는 jr를 씀.
Calle function / Caller function
Calle function : call을 당하는 함수
Caller function : calle function을 호출하는 함수
Function call procedure
- Caller : put the parameter values in registers a_0 ~ a_3
- Caller : Use jal A to branch to the callee function A
- Callee : Perform calculations, put the result in v_0 ~ v_1
- Calle : Return control to the caller with jr $ra
현재 실행하고 있는 명령어 주소를 트래킹하는 것이 굉장히 중요
→ 항상 저장하고 있는 register PC (Program counter)
→ read-only (PC 레지스터가 알아서 업데이트)
store PC + 4 (왜 4냐면 word단위가 4이기 때문)
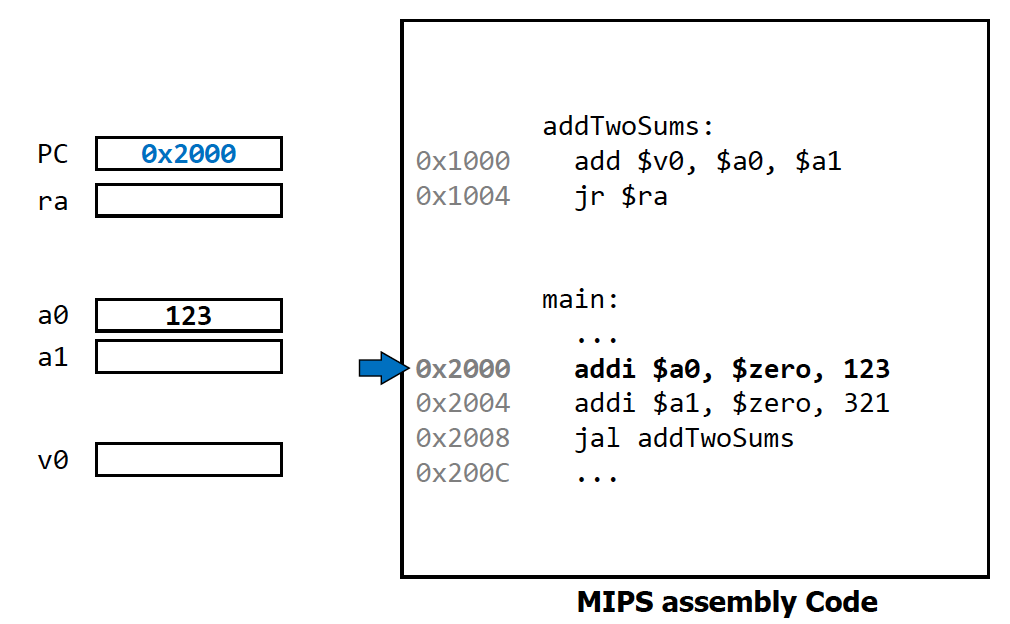
addTwoSums 같은 레이블은 주소를 잡아먹지 않음 (일종의 포인터 느낌)
만약에 더 레지스터가 필요한 경우에는 어떻게 할 것인가?
데이터를 메모리에 저장해두고 해당 데이터가 저장된 메모리의 시작 주소를 argument로 넘길수도 있음 (일종의 call by reference)
stack이라는 공간이 메모리 상에 존재
현재 레지스터에 담긴 것들을 미리 백업해둬야하는데 그때 필요한 것들이 stack. 함수 콜 할 때 레지스터에 있는 값들을 stack에 다 저장해둠. pop/push를 하려면 stack pointer도 핸들링 해야함.
calle function의 경우 t_0 ~ t9는 맘대로 써놓음
하지만 매번 메모리에 저장하기는 귀찮으니까, 몇 개의 register의 경우는 calle function이 건들지 않게끔 약속 → 이런 것들이 s0~ s7 (saved register)
백업할 것들이 있으면 s0~s7에 해놓고, 더 해놔야하면 stack pointer를 이용해서 메모리를 할당을 해놓음. (물론 여러 번 함수콜을 하다보면 s0~ s7에 있는 것들도 스택에 저장해야할 수 있음)
Spilling Registers with a Stack
Stack pointer는 쌓아둘수록 lower address로 이동
→ recursive function같이 caller, calle의 관계가 중첩됨에 따라 s영역도 stack에 저장해야하는 상황이 존재할 수 있다.
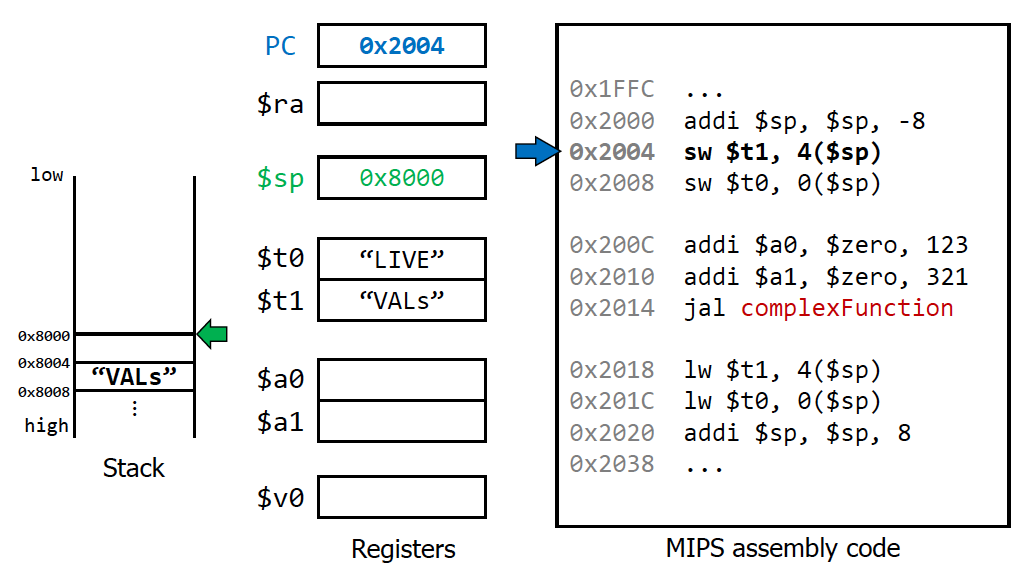
jump and link를 하게 되면 $ra 즉 return address register에 현재 PC값 + 4로 돌아옴.
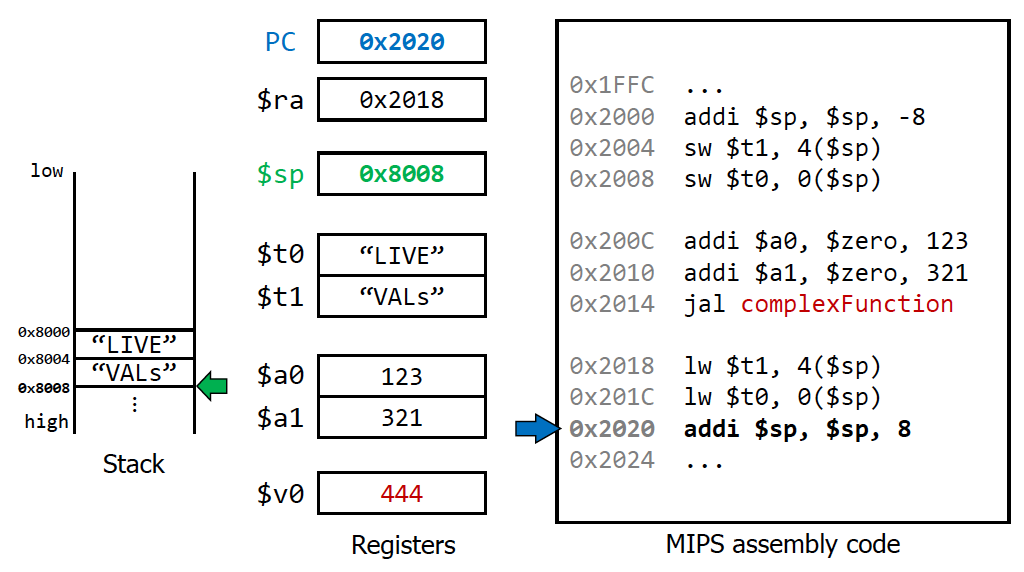
맨 위 3줄을 그대로 거꾸로 아래로 진행해주면 된다. (맨 아래 3줄)
register spilling을 하고 다시 레지스터를 복구
일반적으로는 v0를 읽는 것은 레지스터를 복구한 이후에 진행하게 된다.
(항상 코딩하는 입장에서는 항상 신경을 써야한다.)
Nested Procedures (매우 중요)
Callee function can invoke another function
생각해보면 ra 값을 nested procedure를 호출하기 전에 spilling하지 않는다면 main함수로 다시 돌아갈 수 없다.
따라서 단순히 temporary register뿐만 아니라 다른 레지스터도 spilling하게 되는 상황이 발생한다.
추가적으로 a0 ~ a3 (argument register)도 덮어씌워짐.
Caller function 입장
- argument register 저장 (a 레지스터 4개) : 16바이트
- temporary register 저장 (t 레지스터 10개) : 40바이트
즉 함수를 호출할 때 마다 56바이트 잡아먹음.
→ 이런 이유때문에 out-of-memory issue
Callee function 입장
- ra register를 저장
- s register도 저장 : 8개 총 32바이트
왜 callee가 spilling할까?
caller가 해도 되고, callee가 해도 되긴 함. 근데 callee가 하는 것이 가장 확실함.
추가적으로 nested되면서 callee function이 caller function으로도 기능하기 때문에 callee입장에서 spilling해야 한다.
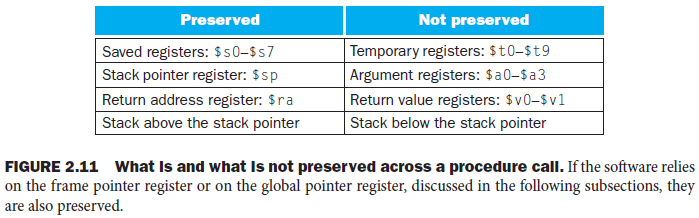
preserved : callee function을 부를 때 수정되지 않는 register
not-preserved : callee function을 부를 때 수정될 수 있는 register
caller function의 경우는 그래서 not preserved에 속하는 register를 spilling하고 callee 입장에서는 preserved영역에 있는 것들을 spilling
Allocating Space on the stack
Stack의 용도
- spilling 역할
- local variable들을 저장하는 역할
→ 만약 local variable에 큰 배열을 넣게 되면 stack을 너무 잡아서 그래서 프로그램이 뻗음.
Frame pointer
Used as a stable base register within a function for local memory references.
→ 이것을 통해서 해당 함수에서는 fp ~ sp 구간 영역들만 접근이 가능하다.
$gp register가 무엇인가?
In MIPS assembly language, the term "gp register" typically refers to the global pointer register. The global pointer register is a special-purpose register that is used to point to a fixed location in memory that contains global and static data.
In the MIPS architecture, the global pointer register is usually given the name
$gpand its value is initialized by the operating system when a program starts running. The$gpregister can be used to access global variables and data, as well as to calculate the address of static variables.
my_function:
addi $sp, $sp, -16 # Make room for 4 saved registers
sw $s0, 0($sp) # Save $s0 on the stack
sw $s1, 4($sp) # Save $s1 on the stack
sw $ra, 8($sp) # Save $ra on the stack
sw $fp, 12($sp) # Save $fp on the stack
addi $fp, $sp, 16 # Set $fp to the start of the current stack frame
# ... code to perform function logic ...
lw $fp, 12($sp) # Restore $fp from the stack
lw $ra, 8($sp) # Restore $ra from the stack
lw $s1, 4($sp) # Restore $s1 from the stack
lw $s0, 0($sp) # Restore $s0 from the stack
addi $sp, $sp, 16 # Deallocate stack space used by the function
jr $ra # Return to the calling function즉, function을 시작할 때, 건드리면 안되는 영역들을 미리 따로 빼서 저장해둠. 이전의 fp도 미리 저장해둔 상태이다.
만약 저장한 부분을 건드는 문제는 어떻게 해결하는가?
전적으로 프로그래머가 조정해야 한다. (fp로 해당 함수가 건들 수 있는 영역은 설정해 둔 상태이다.)
MIPS Register Conventions

gp : heap의 주소를 추적하는 레지스터
at : 현재 어느 레이블인가(디버깅 목적)
MIPS Addressing
메모리를 어떻게 접근하냐 == 메모리 주소를 어떻게 접근하냐
결국 우리가 원하는 데이터에 접근하려면 저장된 주소를 알아내야한다.
→ 이런 것을 memory addressing이라고 부름
Addressing : 32-bit Immediates
I-type instructions support 16bit immediates
Problem : 16비트밖에 immediate를 쓸 수 없다.
→ 하나의 solution : base register를 1개를 둔다 : 사실 이것도 번거로움
따라서 다른 명령어가 필요한데, 사실 생각해보면 상위 주소를 조작할 수 있는 명령어가 있으면 쉽게 뛸 수 있다.
Load upper immediate (lui) instruction

→ 그래서 등장한 개념이 lui (load upper immediate) : 상위 비트가 immediate로 채워짐
lui $s0, 61(0x003D에 해당)을 하면 s0에 0x003D0000이 됨.
→ 추가적으로 ori(or immediate)를 사용해서 하위비트도 수정할 수 있음
ori $s0, $s0, 2304(0x0900)를 하면 s0에 0x003D0900이 됨.
J type instruction format

가장 많은 범위를 immediate으로 해야 점핑할 수 있는 범위가 커지므로
J type는 최대한 많은 범위를 immediate으로 준다. (op코드는 6bit로 그대로 둔다.)
💡
jr는 R-type이고 뒤에 레지스터가 온다. 또한 jal의 경우 $ra 레지스터에 돌아올 값까지 쓰고 뛴다는 점을 유의하도록 하자.
💡
그리고 정확하게는 10000으로 jump하는 것이 아니다.
immediate << 2 하고 현재 pc값과 or 연산 취한 결과에 해당하는 곳으로 jump를 뛴다.
I -type instruction format
Branch는 여전히 I-type를 사용
왜 branch는 I-type을 사용하는가?
점프는 무작정 메모리의 최대한 넓은 범위로 넘는 것이 목표
branch는 현재 명령어의 실행 결과를 보고 가까운 곳으로 뛴다는 특성이 있기때문 (현재 실행되고 있는 명령어의 주소를 기준으로 뜀. 즉 PC의 값을 기준으로)

exit만 봤을 떄는 해당 숫자는 모르지만, binary코드 단으로 보면 PC를 기준으로 얼마나 떨어졌는지가 immediate위치에 들어가게 된다.
Relative addressing
기준이 PC의 값이다.
브랜치의 경우에는 register가 PC로 잡는것이 타당함. (따로 레지스터를 잡지 말고)
→ 보니까 현재 위치를 기준으로 주소의 차이가 2^16 보다 적게 차이가 나네.
그래서 브랜치의 경우에는 offset만 써도 된다. (base register가 없어도 됨)
💡
In reality, however, the base address becomes ($pc+ 4). : MIPS에 한해서만. 이에 따라 pc + 4를 기준으로 . 사실 바이트 단위로 움직이므로, 그냥 + 1을 4bit로 이해를 하자.
→ PC addressing의 경우와 pseudodirect의 경우 address에 적힌 값 * 4
loop:
lw $t1, 0($t0) # Load word from memory at address $t0 and store in $t1
add $s0, $s0, $t1 # Add $t1 to the sum in $s0
addi $t0, $t0, 4 # Increment address in $t0 by 4 bytes
slti $t2, $t0, 100 # Set $t2 to 1 if $t0 is less than 100, 0 otherwise
bne $t2, $zero, loop # Branch to loop if $t2 is not equal to 0💡
branch는 실제로는 PC-relative addressing을 사용하고, 사실 loop라고 하는 것도 인식하기로는 현재 위치에서 -4명령어 만큼 뒤로 간다고 인식한다. 즉 bne $t2, $zero, -4라고 인식한다. (byte기준으로는 -16byte이지만 word단위로 취급하면서 처리할 수 있는 주소의 범위가 4배만큼 증가한다.)

💡
conditional branch의 경우 현재 실행시키고 있는 PC 값을 기준으로 그리 멀리 떨어져 있지 않은 곳으로 점프하는 상황이므로 현재 PC를 기준으로 pc-relative addressing을 사용하는 것이 일반적이지만, jump-and-link 같은 명령어들의 경우 가까운 주소로 점프한다고 할 수 없다.
💡
pseudodirect는 J-type이 쓰는 relative addressing으로 위의 식은 잘못되었다. J-type의 경우 6개의 opcode, 26개의 immediate가 존재하는데 branch 주소는 pc |(immediate << 2)를 통해서 결정된다. 즉 상위 4비트는 “현재 pc값”에 의해서 결정되고, 나머지 28bit는 immediate << 2에 의해서 결정된다.
Decoding the Machine Language
Instruction decoding : 32bit의 명령어가 들어왔을 때 해당 명령어가 시키는 것이 무엇인가?
결국 R, I, J타입 중 하나이다.
- 상위 6개는 무조건 Op code field임을 이용
→ 상위 6개를 보고 op code를 뽑아낼 수 있음 (가능한 operation의 수는 )
- op code에 따라서 R, I, J인지 알 수 있음 (테이블로 이미 정의해놓음)
- Split the 32bit instruction into the format’s fields
- Calculate the values of the identified fields
결론 : ISA manual이 있어야 한다.
만약 architecture가 다르면 encoding하는 과정도 달라지게 된다.
Decoding Procedure
- 2진수로 먼저 바꾼다. (매우 중요)
- 맨 앞 6자리를 보고 type을 찾는다. (해당 내용을 기준으로 해당 숫자가 무슨 정보인지 추측할 수 있음)


- 이런 경우 또 다른 format이 있음

op와 funct를 보고 add라는 것은 알았음
- 매핑 (5, 15, 16을 찾아야 함)


→ add $s0, $a1, $t7 (순서 주의)
💡
R type과 I type에서 맨 앞에 오는 친구들이 명령어 상으로는 레지스터 가장 뒤에 온다는 점을 주의해야한다.
Supporting Parallelism
MIPS 명령어 중에 특별한 명령어들
→ parallelism을 지원하기 위해 만들어진 명령어
병렬적으로 처리하면 퍼포먼스가 올라간다.
문제는 없는가?
Data races(Race condition)가 일어날 수 있다. (즉 동기화 문제가 발생할 수 있다.)
→ 2개의 thread가 동일한 메모리 주소에 접근하려고 할 때가 그 예시
이 문제를 해결하기 위해 lock-unlock을 해서 mutual exclusion 시킨다.
→ 순서를 보장하지는 않지만 어떤 프로세스가 먼저 접근하고 있을 때는 다른 프로세스가 접근이 안되게끔
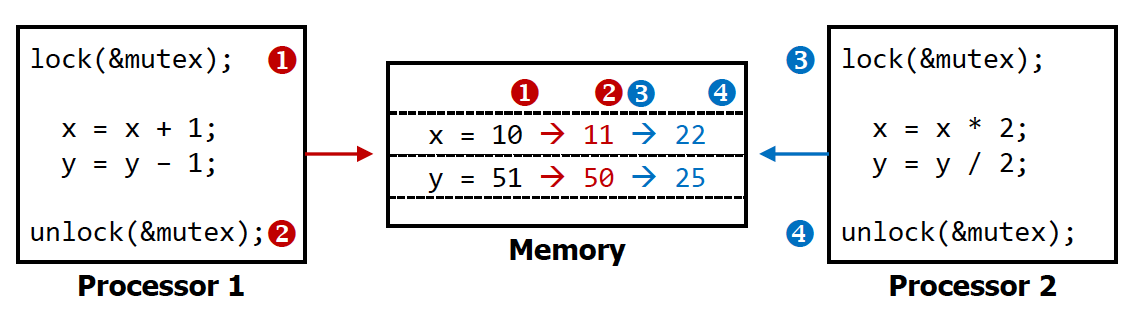
주의 : 프로세서1과 프로세서2 들이 어떤 순서로 실행될 것인지는 보장하지 않음.
MIPS : Atomic Instructions (공부가 부족함)
결국 mutual exclusion을 하려면 하드웨어 적에서도 해야함
Atomic instruction은 결국 synchronization primitive를 제공하는 것. 값을 변경했을 때 그것이 바로 반영이 되어야함. 하드웨어적으로 1개만 바꿀 수 있게끔 지원하는 것. (순차적으로 진행하게끔)
ex ) single atomic exchange / swap operation
Load linked (ll instruction)
예시 : ll $t1 0($s1)
t1 = memory[s1 + 0]을 한다는 점에서는 load와 다르지 않다. 단, exclusive bit를 1로 설정한다.
💡
ll instuction은 메모리에서 값을 읽어와 레지스터에 저장할 때, 해당 값을
캐시 에다가도 저장한다.Store conditional (sc instruciton)
예시 : sc $t0 0($s1)
memory[s1 + 0] = t0를 한다는 점에서는 store와 다르지 않다. 하지만 exclusive bit의 값에 따라 경우가 나뉘게 된다.(만약 다른 코어가 해당 데이터 접근을 시도했다면 exclusive bit가 1에서 0으로 바뀌게 된다.)
- Case 1 : Exclusive bit == 1
memory[s1 + 0] = t0를 수행하고, t0에는 1이 대입된다.
- Case 2 : Exclusive bit == 0
memory[s1 + 0]에 t0를 저장하지
못하고, t0에 0이 대입된다.
Example
아래 예시는 s1과 s4 사이의 데이터를 atomic swap하는 코드임
- move : 우선 s4의 데이터를 t0으로 옮김 (s4 => t0)
- ll : s1에 있던 데이터를 t1으로 빼놓으면서 exclusive bit를 1로 설정 (s1 => t1)
- sc
- sc가 성공 : t0에 1이 저장되고 t0에 있는 데이터를 memory[s1]에 넣는다.
- sc가 실패 : t0에 0이 저장됨 (memory[s1] = t0는 진행되지 않음)
- beq : 만약 실패했다면 (t0=0) 처음으로 되돌아가서 다시 진행
- move : 만약 성공했다면 ll때 옮겨놓은 t1을 s4로 옮기고 종료
main:
li $s1 100
li $s4 200
jal swap
li $v0 10
syscall
swap:
move $t0 $s4
ll $t1 0($s1)
sc $t0 0($s1)
beq $t0 $zero swap
move $s4 $t1
jr $raStarting a Program
Linker
독립적인 machine language를 하나로 연결해서, 하나의 큰 machine language로 만들어주는 역할
→ 이를 통해 컴퓨터에서 돌아갈 수 있는 executable 을 만든다.
Loader
운영체제의 일부분으로, 운영체제의 자신이나 응용프로그램을 찾아 주기억장치에 적재하고 프로그램을 실행하는 역할
- address space을 만든다.
- 명령어나 데이터를 해당 address space로 옮긴다.
- 프로그램을 실행한다.
Linking libraries
Traditional approach
Linking libraries before the program is run
→ 장점 : 빠름
→ 단점 : 라이브러리가 executable code의 일부로 들어가 있는 상황이기 때문에 라이브러리가 버그 등의 이유로 업데이트가 된 경우 반영이 되지 않을 수 있음.
Dynamically linked libraries (DLL)
The library routines are not linked and loaded until the program is run.
→ Enable lazy linking and loading of library functions
Java Program
자바의 경우 Just-In-Time compilation을 한다.
→ machine code가 JVM(java virtual machine)을 도는 동안 생성된다.
장점 : high portability
단점 : low performance
반응형
Contents
소중한 공감 감사합니다