Computer Science/Operating System
12. Storage Structure
- -
728x90
반응형
Why Disks?

여전히 가격 차이는 대략 100배 정도
→ storage가 RAM보다 저렴하기는 하다.
추가적으로 memory는 volatile이지만, disk는 non-volatile이다.
그래서 어떻게 구성을 할 것 인가에 대한 고민을 하기 시작함
→ 파일이 커져서 모든 파일을 다 RAM에 담을 수 없다.
Anatomy of a Disk

sector들이 partition된 것이 track이다.
그리고 각 platter들은 여러 개의 track으로 구분된다.
cylinder : 각 platter에 존재하는 동일한 반지름을 가진 track들의 집합
💡
platter의 윗면/아랫면 모두 다 사용할 수 있다.
💡
추가적으로 track의 반지름이 다르므로, 1개의 track에 들어가있는 sector의 개수가 다를 수 있다.
💡
Positioning time : seek time(원하는 track으로 head가 옮겨가는데까지 걸리는 시간) + rotational latency (회전하면서 걸리는 시간)
Read/Write Operations to a Disk

Disk를 읽고 쓰는 시간은 결국 seek time + rotational latency + transfer time
Disk Addressing
어떻게 파일을 저장할 것인가?
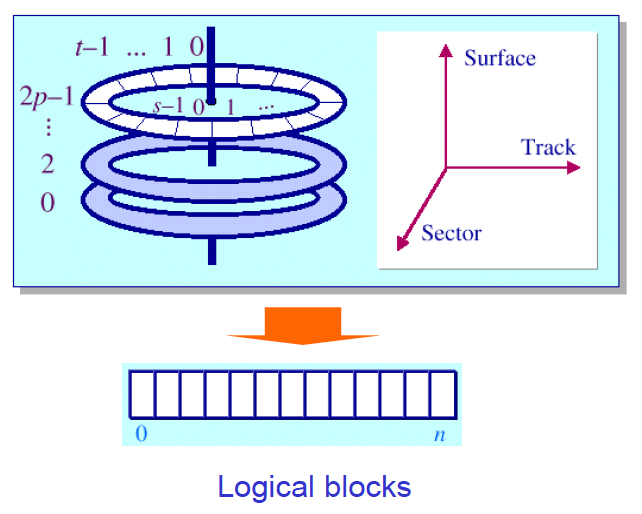
하고 싶은 것은 를 1차원의 logical block에 대응하고 싶은 것이다.
Cylinder-based Mapping

Let , the value of the logical block address is
💡
s * p = sectors per cylinder
💡
Modern disk drives handle the mapping between Logical Block Addresses (LBAs) and physical sectors internally, and there is not a direct and visible relationship between the LBAs used by the operating system and the physical sectors on the disk.
→ 즉 실제로는 cylinder based mapping을 사용하지 않는다.
Disk (Head) Scheduling
여러 프로세스가 disk access를 요청할 경우, 어느 process의 task부터 처리할 것인지에 대한 기준이 필요하게 된다.

💡
여기서 다루는 Disk scheduling algorithm은 disk arm이 이미 원하는 cylinder에 도착했다고 가정한다.
FCFS

Fair but inefficient
SSTF (Shortest Seek Time First)

job queue에 들어있는 것 중에 현재 위치 기준으로 가장 가까운 것을 다음 스케줄 대상으로 생각하겠다.
하지만, starvation이 가능하다.
SCAN (Elevator algorithm)

SSTF의 문제를 해결한 algorithm. 한 방향으로 끝까지 이동했다가 반대로 이동한다.
끝까지 간다는 것 이 문제가 됨
C-SCAN (Circular SCAN)

Scan을 한쪽 방향으로 하겠다. 한쪽 방향으로 끝까지 갔다가 다시 처음부터 다시 시작
💡
SCAN보다 uniform한 wait time을 제공한다.
Look / C-LOOK (Circular Look)
SCAN과 CSAN은 끝까지 이동하게 되는데, LOOK은 큐에 존재하는 것 중에 최소와 최대값까지만 이동하자는 것.

위 사진은 C-SCAN의 변형인 C-LOOK scheduling이다.
→ SSTF나 LOOK이 기본적으로는 좋은 결과를 낸다.
현실에서는 optimal한 방법을 찾을 수 없다. (미래의 일을 알 수 없기 때문이다.) 일반적으로 disk-sccheduling algorithm은 module로 구현이 된다. (즉 kernel에 넣었다 뺐다 할 수 있음)
→ 일반적으로 SSTF나 LOOK을 쓰면 무난하다.
→ 만약 disk에 load가 많이 된 경우에는 SCAN이나 C-SCAN이 좋다.
Disk Management
A single disk can have multiple partitions
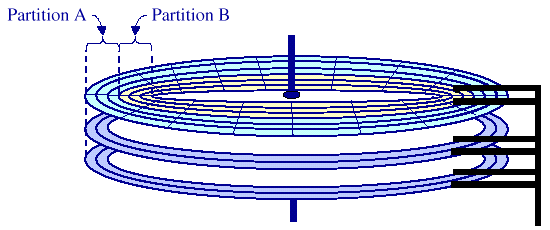
- low-level formatting(physical formatting) 작업을 수행한다. (Low-level formatting 과정에서 각 platter의 표면은 여러 개의 트랙으로 구분된다.)
- Disk partition
- Logical formatting (파일 시스템을 설치)
- 특정한 partition에 OS를 설치한다.
💡
이때 boot block은 bootstrap을 저장한다. (Bootstrap은 컴퓨터 부팅 과정에서 처음으로 실행되는 코드입니다. 컴퓨터를 부팅할 때는 부트 로더가 시스템의 시작 주소에 위치한 부트스트랩 코드를 찾아 실행합니다. 이 부트스트랩 코드는 컴퓨터의 초기화 및 시작에 필요한 기본적인 설정과 작업을 수행합니다.)
💡
이때 partition은
collection of consecutive cylinder 로 구성된다.이때 formatting을 하는 과정에서 bad sector가 있다고 하면 이를 처리하기 위해서 sector sparing에 remapping을 진행하게 된다. 이러한 작업을 bad sector remapping 이라고 부른다.
sector sparing이 무엇인가?
Sector sparing은 하드 디스크 드라이브에 미리 예비 섹터(spare sector)를 할당하는 과정을 의미합니다. 예비 섹터는 기본적으로 사용되지 않고 비어 있는 상태로 유지됩니다. 하지만 원본 섹터에 물리적인 손상이 발생했을 때, 예비 섹터가 해당 섹터의 기능을 대신하게 됩니다.
일반적으로, 하드 디스크 드라이브는 일부 섹터를 예비 섹터로 할당하여 보유하고 있습니다. 이러한 예비 섹터는 내장된 컨트롤러와 관련 알고리즘에 의해 관리됩니다. 컨트롤러는 데이터를 저장하고 있는 원본 섹터에 물리적인 손상이 발견되면, 예비 섹터로 교체합니다. 이렇게 되면 손상된 섹터에 저장된 데이터는 예비 섹터로 복사되어 복구됩니다.
Swap space Management
physical memory가 부족하기 때문에 잠시 빠져야 한다. (즉 on-demand paging을 수행하기 위해서는 swap space가 반드시 필요하다.)
Swap File Approach
하나의 file로 swap에 필요한 정보를 담자. 즉 기존의 file-system을 활용해서 swap-out 목적으로 사용하자는 것
💡
편리하긴 하지만, normal file system의 interface를 그대로 쓰기 때문에 해당 위치를 찾아나가는 과정에서 overhead가 커진다.
Swap Partition Approach
Disk formatting할 때 애초에 따로 swap space용 partition을 확보하는 것 (즉 file-system을 이용하는 공간과 완전히 분리)
→ 즉 해당 partition은 순전히 swap space목적으로 사용하는 것
Swap File Approach에 비해서는 속도가 빠르다는 장점이 존재
💡
하지만, 너무 크게 잡으면 해당 공간을 낭비하게 되는 문제가 발생한다.
Example
초창기 4.3BSD 운영체제를 보게되면 virtual address가 만들어질 때, 해당하는 공간을 아얘 swap space에 잡는다. The kernel uses swap maps to track swap-space use.

code에 대한 map과 data에 대한 map을 따로 관리
Solaris의 경우에는 page fault가 날 때 swap 공간을 할당하게 된다.
Redundant Array of Inexpensive Disks (RAID)
싸고 덜 신뢰할 수 있는 disk들을 모아서 큰 용량의 storage를 만들고 싶은 것이 목표이다. 왜냐하면 하드디스크가 굉장히 비쌌음.
Personal computer가 나오게 되면서 하드디스크의 용량이 적었음.
→ 즉 여러 개의 작고 independent한 disk를 묶어서 하나의 대용량 storage로 활용을 하자는 것.
Key mechanisms
Striping: 하나의 logical file을 쪼개서 여러 개의 disk에 돌아가면서 쓰는 것 (이걸 통해서 높은 throughput을 얻고자 하는 것)→ 독립적인 disk이므로 쪼개면 그만큼 throughput이 늘 것이다.
- 여러 개의 disk를 쓰게 되면서 disk failure에 대한 문제가 부각됨
→ 그래서 Data
redundancy를 주게 됨 (compromise하기 위한 기술)Redundancy는 다음과 같은 방법으로 얻게 된다.
Mirroring: 한 디스크의 내용을 그대로 복사
Parity: 이 방법의 경우에는 여러 disk가 망가지는 경우 사용할 수 없다는 문제가 있음
Design goals of RAIDS
- Increased data reliability
- Increased I/O performance
→ Reliability를 높이면 performance가 떨어지는 문제가 있긴하다.
RAID levels
RAID 0 (striped disks)
Stripping만 하는 것 (parity 고려 x)
즉 redundancy에 대한 고려는 되어있지 않음.

여러개의 disk를 번갈아가면서 하는 것. modulo 현산을 취하는 것
→ 이렇게 하면 속도를 올릴 수 있다. 동시에 읽고 쓰면 된다.
💡
단, 1개가 망가지면 굉장히 큰 문제가 발생할 수 있음. (redundancy를 고려하지 않으므로)
RAID 1 (disk mirroring)
2개의 disk를 써서 mirroring하는 것 (parity x)

단, capacity의 활용은 떨어진다는 점이 단점이다.
Read할 때는 빠르게 진행할 수 있다는 장점도 고려해볼 수 있다.
💡
백업을 하는 과정에서는 RAID1을 많이 사용한다. Runtime에 disk 내용을 복제한다.
RAID 3 (Striped set with dedicated parity)
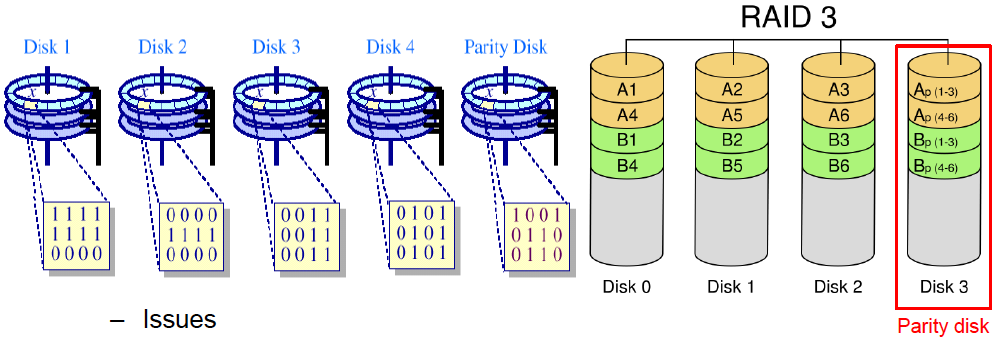
💡
stripping과 parity 모두를 사용
하드 디스크 5개를 쓴다고 가정. 이중 4개는 stripping하는 것에 사용함. 마지막 disk는 4개의 block의 parity block을 담음
이중 디스크 1개가 날라가도 복구할 수 있음 (나머지 block들에 대한 정보와 parity disk의 정보를 가지고 복구가능)

하지만 parity를 계산하는 과정에서 overhead가 올라간다. 즉 parity disk 가 bottleneck로 작용하게 된다. 예를 들어 위 그림에서 D0의 값을 업데이트 하게 되면 parity값을 계산하기 위해서는 굉장히 많은 연산을 수행하게 되는 문제가 발생한다. 이러한 문제를 small write problem 이라고 부른다.
💡
만약 2개 이상이 망가지면? : 버려야함
RAID 5 (Striped set with distributed parity)
striping도 하고 parity도 고려해서 redundancy와 성능을 같이 고민하겠다는 것. 즉 parity block을 모든 disk에 분배해서 RAID3에서 나타난 bottleneck 문제를 해결해보고자 하는 것

💡
일종의 parity block 자체도 stripped하는 것
Tertiary Storage
장기적으로 데이터를 저장해야하는 storage

싸고 용량이 큼
일반적으로는 removable media 를 활용해서 만들어진다. 예를 들면 주크박스가 그 대표적인 예시이다. removable media의 예시로는 DVD와 CD-ROM이다.
Hierarchical Storage Management
언제 storage간에 정보를 이동할 것인가에 대한 기준을 제공해야하는 것이 문제가 된다. 빈번히 쓰는 것을 storage에 가져다 놓고, 크고 잘 안쓰는 것을 tertiary에 놓겠다는 것
💡
예전에는 tertiary storage를 싸서 이용했지만, 현재는 optical disk와 같이 안정적이기 때문에 사용하는 추세이다. (단, 많이 비싸짐)
Performance issue
일반적으로 느려지고 용량은 커지는 형태로 가게 됨.
Storage-Centric Infrastructure
Traditional Architecture

이전에는 client가 server에 접속해서 해당 storage에 있는 자료를 접근하는 방식으로 이용했었다.


하지만 많은 overhead가 존재한다. client입장에서 data file을 access를 하기 위해서는 많은 interface를 많이 거쳐야 한다.
→ 그래서 전용으로 storage server를 만들자는 생각으로 이어지게 됨.
NAS (Network Attached Storage)

- TCP/IP와 같은 통신 프로토콜을 사용하는 message network에 storage system이 통합되어 결합된 것
→ 유저의 network 망에 특정 storage를 붙이는 것
장점은 그냥 기존 네트워크에 연결하면 된다는 것이다.
💡
storage와 더불어
filesystem 도 제공해준다는 점을 기억해야 한다.💡
즉 any storage device attached to the network and offering storage functionality
SAN (Storage Area Network)

- Shared access network에 storage device를 붙인 것
- Accessed via private network dedicated for storages.
→ NAS처럼 message network를 사용하는 것이 아니라 아주 고성능의 전용 통신망을 내부적으로 써서 여러 storage와 서버를 엮는 것이다.
SCSI나Fibre channel같은 storage protocol을 사용한다.→ 이러한 전용 망의 bandwidth는 아주 크다. 이에 따라 아주 고성능으로 access할 수 있다.
💡
Provides only block based storage (not filesystem). 즉 단지 block만을 제공하는 것이므로 file system은 직접 설치해야 한다.
💡
SAN 방식은 여러 스토리지들을 하나의 네트워크에 연결시킨 다음 이 네트워크를 스토리지 전용 네트워크로 구성하는 방식이다.
Advantages of NAS and SAN
전통적인 client와 server architecture는 bandwidth가 제한적일 수 밖에 없고, bottleneck 문제가 발생할 수 있다.
이에 NAS와 SAN을 사용하게 되면
Availability: 이들은 네트워크를 통해 다른 컴퓨터 시스템에 스토리지를 제공하므로, 한 시스템에서 문제가 발생하더라도 다른 시스템에서 데이터에 접근하는 것이 가능합니다. 이는 중요한 데이터를 보호하고, 장애 시스템의 영향을 최소화하는데 도움이 됩니다.
Scalability: 필요에 따라 추가 스토리지 용량을 쉽게 추가하거나 제거할 수 있습니다. 이는 사용 중인 스토리지 용량을 유연하게 관리하고, 용량에 따라 비용을 최적화하는 데 도움이 됩니다.
Centralized storage management: NAS와 SAN은 중앙 집중식 스토리지 관리를 제공합니다. 이는 여러 시스템에서 사용되는 스토리지를 하나의 장소에서 통합적으로 관리할 수 있게 해줍니다. 이를 통해 스토리지 용량을 더 효과적으로 활용하고, 관리 작업을 단순화하는 데 도움이 됩니다.
반응형
Contents
소중한 공감 감사합니다