Computer Science/Operating System
8. Memory Management
- -
728x90
반응형
Memory Management
왜 memory management를 고민해야하는가?
기본적으로 여러 개의 process를 concurrent하게 돌려야 한다.
Multiprogramming의 요구사항은 무엇인가?
- Protection : 한 프로세스가 다른 프로세스의 메모리 공간을 건드려서는 안됨💡paging의 경우에는 해당 process에 대응되는 frame만 page table을 통해 접근이 가능하므로 protection issue가 해결이 된다.
- 메모리 하드웨어를 적절한 시점에 업데이트를 해줘야함 (주소 변환/ 보호이슈). 따라서 이 작업이 효율적으로 수행되어야 함.
- Protection : 한 프로세스가 다른 프로세스의 메모리 공간을 건드려서는 안됨
Memory management의 정의는 무엇인가?
여러 개의 프로세스가
OS와 하드웨어에 의해 메인 메모리에 존재할 수 있게끔 하는 작업이다.
Memory management의 목표
- 프로세스 사이의 isolation을 제공 (Protection을 제공)
- 부족한 메모리에 프로세스를 할당해야함에도 불구하고, 성능은 효율적이면서 오버헤드가 작게끔하는 것이 목표
Issues
- 여러 process를 concurrent하게 실행시킬 수 있도록 지원해야함.
- 특히 각 프로세스별로 크기가 다르다는 것도 고려해야 한다.
- 특정 process의 경우 physical memory보다 더 큰 주소공간을 가질 수 있다. 어떻게 해야 돌릴 수 있을 것일까?
→ virtual memory에 대한 motivation
💡폰 노이만 아키텍쳐의 개념을 잘 생각해보면 physical한 메모리 공간안에 전부 다 있지 않아도 된다. CPU가 필요하는 타이밍에만 있으면 충분하다. 또한 메모리참조는 공간상/시간상 locality를 가진다는 점도 하나의 이유가 된다.
- Process의 image에는 여러 영역이 존재한다. (Heap, stack, code, etc). 각각의 영역을 어떻게 잘 관리할 것인가
- Protection 및 Sharing
- 성능
Address Spaces
Physical address space (Absolute address)
Supported by the hardware
→ Absolute address라고 불림
Logical address space (process address space / CPU address space / Virtual address / Linear address)
A process’s view of its own memory
그래서 Logical address를 Physical address로 바뀌어가는 것인가?
→ User program은 logical address를 다루는 것 (실제로 physical address를 볼 수 없음. logical address를 physical address로 변환시키는 것은 CPU 내에 있는 MMU가 담당한다.)
💡
Instructions executed by the CPU issue “logical addresses” : 기말 시험
Address Generation

Assembly를 거치면서 Machine code가 나옴. (여기서 0~ 75는 logical address이다.) 만약 library를 호출하게 되면 linking이라는 작업을 통해 코드와 기존의 라이브러리를 엮고 logical address로 변환하게 된다. 이것을 통해 physical memory에 loading하게 됨.
💡
CPU가 generate하는 PC는 logical address이고, MMU와 OS에 의해서 physical address로 변환된다.
Hardware for Address Translation

여러 개의 프로세스가 존재할 수 있기 때문에 protection이 중요해짐. (한 프로세스가 다른 프로세스를 방해해서는 안됨)
→ 이를 위해서 몇 개의 register가 존재한다. (Limit register, Base register. Limit register는 이미지의 크기를 체크하는 역할을 담당)
즉 logical address/physical address의 범위를 벗어나는지 runtime에 확인을 한다.
💡
paging system상에서는 이러한 기능을 paging이 대체한다고 생각해주면 된다. 각 프로세스의 limit는 페이지 테이블의 크기를 통해 결정될 수 있다.즉, 프로세스가 접근할 수 있는 주소 공간의 범위는 해당 프로세스의 페이지 테이블에 의해 결정됩니다.
Swapping

Definition
A process can be swapped temporarily out of memory to a backing store(swap space) , and then brought back into memory for continued execution. 여러 개의 process가 돌아가면서 main memroy가 부족한 경우에 발생하게 됨. process가 끝나지 않았음에도 불구하고 runtime 도중에 프로세스의 이미지를 하드디스크(backing store)로 복사함.
리눅스의 경우 swap partition을 확보함 (해당 영역에 swap out 된 데이터가 들어감)
→ 가상 메모리의 아이디어는 전체 이미지가 메모리에 다 있을 필요가 없다는 것에서 출발. 필요한 페이지만 메모리상에 있으면 됨 (1024byte 정도)
💡
나중에 file system에서 배우겠지만, swap space는 file system이 들어가 있지 않다. 아래 링크를 참조하도록 하자.
→ Medium term scheduling은 swap out 된 것 중 어느 것을 swap in 시킬지 판단함
→ Swapping에 걸리는 시간은 swap하는 메모리의 크기에 비례한다.
만약 해당 페이지가 메모리에 없으면 어떻게 되는가?
MMU가 exception을 발생시키고, 하드디스크에 있는 page를 업데이트하고 계속 진행됨.
Simple Memory Management
가상 메모리를 사용하지 않는 management를 의미
💡
수행하고 있는 process 전부 다 main memory에 로딩되어야 한다는 개념 (만약 overlays가 이용되지 않는다면)
이러한 기법은 현재 존재하는 OS에서는 사용하지 않는다. 하지만 고급 management를 구현하는데 요소로 가용됨.
💡
그럼에도 불구하고, micro-processor firmware에 이러한 간단한 형태의 메모리 관리기법이 자주 사용된다.
종류가 어떻게 되는가?
- Fixed partitioning
- Dynamic partitioning
- Simple paging
- Simple segmentation
1. Partitioning
Fixed partitioning
Main memory를 고정된 사이즈로 자름 (한번 자른 사이즈는 유지)

Principle
- 프로세스의 크기보다 더 큰 partition에 loading할 수 있음.
- 만약 모든 partition이 다 차있으면 swapping
- 만약 partition보다 프로세스의 크기가 많이 큰 경우, 프로그래머가 overlay 기법을 통한 프로그램 디자인을 해야한다.
Equal-size partitions
빈 partition이 있으면, 해당 partition에 process가 loaded되면 된다. (크기가 동일하므로 어느 partition에 들어가든 상관이 없다.). 만약 빈 partition이 없는 경우, 그 중 1개를 swap out시키고 할당시킨다.
문제는 없는가?
Internel fragmentation: 확보한 크기보다 일부만 사용할 경우에 발생하는 문제 (즉 utilization 문제가 발생할 수 있음). Unequal-size partition이 위 문제를 완화할수는 있지만, 여전히 문제가 된다.→ 그래서 가변으로 하자. 각 방마다 큐를 두고! 그래서 나온 개념이 Unequal-size partitions
Unequal-size partitions (Use of a multiple queue)
이 경우에는 multiple queue를 사용한다. 프로세스의 이미지 크기를 바탕으로 적절한 queue에 삽입한다.
→ 즉 들어갈 수 있는 partition 중 가장 작은 partition에 할당한다. 이를 통해 internal fragmentation 문제를 일부 완화할 수 있게 된다.
위 방식에 문제는 없는가?
예를 들어 이미지 사이즈가 작은 process들만 들어오고 있다고 가정하자. 위 경우에는 다른 queue는 비어있음에도 불구하고, 큐에서 기다리고 있는 문제점이 존재한다. 그래서 등장한 개념이 single queue를 이용하자는 것
Unequal-size partitions (Use of a single queue)

극단적으로 특정 partition만 사용하려고 하는 문제점을 해결할 수 있음. multiple queue때와 마찬가지고 들어갈 수 있는 partition 중 가장 작은 partition에 할당하는 작업을 거치게 된다. 이를 통해 동시에 수행할 수 있는 process(level of multiprogramming)이 증가되어 throughput이 증가하지만, multiple-queue를 쓸 때에 비해서는 internal fragmentation 문제가 더 발생하게 된다.
Dynamic partitioning
고정 partition은 결과적으로 internal fragmentation 문제를 피할 수 없음
→ 그래서 등장한 개념이 dynamic partitioning (각 프로세스가 요구하는 만큼만 할당하자는 것)

하지만 external fragmentation 문제가 발생하게 된다. (가용할 수 있는 메모리 공간이 줄어드는 문제가 발생함)
💡
Internel fragmentation은 해결되었지만, external fragmentation 문제가 발생하게 됨
→ 그래서 Compaction 을 통해 이러한 문제를 해결하려고 함
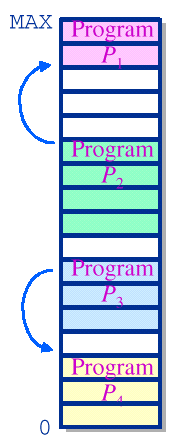
→ 사실 overhead가 굉장히 큼. 왜냐하면 수행중인 프로세스를 멈추고 reallocation을 하는 과정을 수행해야하기 때문
💡
Compaction은
dynamic relocation이 가능할 때 에만 수행될 수 있다. 이때 dynamic relocation은 프로그램이 실행되는 동안에 메모리 주소를 변경할 수 있는 기능을 의미한다. 하지만, I/O를 하고 있는 프로세스의 경우에는 문제가 발생할 수 있는데, 프로세스가 I/O 연산을 수행하는 동안에는 그 프로세스를 메모리에 고정하는 것이 좋기 때문이다. 그렇지 않으면, I/O 연산 중에 프로세스가 이동되거나 종료되면 데이터 일관성 문제가 발생할 수 있다.그래서 어떠한 기준으로 빈 공간 중 어디를 설정할 것인가?
- Best fit : 넣을 수 있는 것 중에 가장 작은 공간
- First fit : 가장 낮은 주소부터 보면서 넣을 수 있는 최초 공간에 배치
- Next fit :
마지막으로 할당한 위치보다 큰 주소들 중 넣을 수 있는 최초 공간에 배치
- Worst fit : 넣을 수 있는 공간들 중 공간이 제일 큰 곳에 배치. 이를 통해서 external fragmentation을 줄이겠다는 것
💡일단 공통적으로 compaction을 최대한 안하는 것이 목표이다.
Fragmentation
External fragmentation
메모리 남는 공간이 파편화 되어있어 나타나는 문제점
Internal fragmentation
할당된 영역을 다 못쓰는 상황때문에 memory utilization이 떨어지는 상황
Overlays
메모리 공간이 없는 상황에서 프로그래머가 여러개의 모듈로 쪼개서 의도적으로 메모리에 넣었다가 뺐다가 하겠다는 것. 위 방법을 통해 작은 메모리 위에 큰 program이 돌 수 있게끔하게 됨.
(Program의 sequence를 프로그래머가 지정해둔 것)

실제 physical memory가 작은 상황에서 큰 프로그램을 돌릴 수 있게 됨
예를 들어 프로그래머 입장에서는 A와 B가 동시에 수행되지 않는다는 것을 알고 있음. 그래서 A, B를 동시에 메모리를 넣지 않아도 됨.
Buddy System (Combining fixed/dynamic partitioning)
Principle
앞서 살펴본 것처럼 Fixed partition은 Internal fragmentation문제가 발생하고 Dynamic partition은 external fragmentation이 발생한다. 2개의 단점을 조금이라도 해결하고자 등장한 개념이 Buddy system. 즉 Dynamic allocation의 문제를 해결하기 위해서 등장한 개념이라고 생각하면 됨. (Internal fragmentation 문제는 있지만, external fragmentation 문제를 해결하고자 함)
Algorithm
2의 거듭제곱 단위 만큼만 메모리를 할당시켜 줌
이때, 상한선(U)과 하한선(L)을 결정해주어야 한다. 이 하한선은 저장하는데 발생되는 오버헤드를 최소화하고 비어있는 메모리 공간을 최소화 하기 위해서 필요하다
- 메모리가 할당되면
- 적당한 크기의 메모리 슬롯을 찾는다.(최소한 요청된 메모리와 동일하거나 큰 블록)
- 적당한 크기의 메모리 슬롯이 발견되면, 프로그램에 할당한다.
- 적당한 크기의 메모리 슬롯이 발견되지 않으면, 적당한 메모리 슬롯을 만들기를 시도한다. 시스템은 아래의 일들을 시도한다.
- 요청된 메모리 크기보다 크게 절반씩 빈 메모리 슬롯을 자른다.
- 하한선에 도착하게 되면, 해당 메모리(하한선 크기의 메모리)를 할당한다.
- 다시 첫 번째 단계로 돌아간다.(적당한 크기의 메모리를 찾기 위해서)
- 적당한 메모리 슬롯이 발견될 때까지, 이 과정을 반복한다.
- 메모리가 해제되면
- 메모리 블록을 해제한다.
- 주변의 블록들을 살펴 본다 - 주변 블록들도 해제된 상태인가? (정확하게는 buddy가 해제된 상태인지를 확인한다.)
- 만약 그렇다면, 두 메모리 블록을 조합하고 다시 두 번째 단계로 돌아간다. 그리고 해제된 모든 메모리들이 상한선에 도달할 때까지 이 과정을 반복하거나, 해제되지 않은 주변 블록들을 마주칠 때까지 반복한다.
💡
주의할 점은 아무 블록이나 합칠 수 있는 것은 아니고, buddy끼리만 합칠 수 있다. buddy끼리면 address가 정확히 1bit만 차이난다. (물론 그 역은 성립하지 않는다.)
Limitation
실제 현대 OS의 경우에는 buddy system보다는 paging과 segmentation을 기반으로 한 virtual memory를 사용하고 있다. 하지만, kernel memory allocation(KMA) 에서는 buddy system이 아직까지 잘 사용되고 있다.
Example

→ Release C를 잘 봐둘 것. 빈 것 2개가 합쳐짐 (2개의 똑같은 빈 블럭이 존재할 때 따로 있는 것이 아니라 합치는 것) 그래야 external fragmentation 문제를 해결할 수 있음. (즉 release한 경우에도 합칠 수 있는 경우라면 계속 합치는 것)
D가 끝나고 왜 왼쪽과 합치지 않고, 오른쪽에 합친 것인가?
임의대로 합치는 것이 아니라, Buddy끼리만 merge할 수 있다.
💡
Buddy system을 통해 External fragmentation 문제가 많이 최소화됨.
Note
해당 block과 그 buddy는 정확히 1 bit 만큼만 차이가 발생한다.

논리적으로 생각해보면 자명하다.
💡
역은 성립하지 않는다. 1 bit 차이가 난다고해서 buddy를 의미하지는 않는다. 예를 들어 010과 110은 buddy가 아니다.
Case study (Linux)
리눅스 커널에 buddy가 쓰임. KMA(kernel memory allocation) 을 잘 설계하는 과정에서 사용된다. kernel의 경우 연속적인 physical memory allocation을 원한다는 특성때문에 paging과 segmentation을 활용한 virtual memory를 이용하기보다는 buddy system을 이용하게 된다.
이때 KMA란 커널이 사용하는 메모리 할당 기법으로, kernel 모드에서 메모리를 할당받고 return하는 과정에서 주로 사용한다.
💡
Kernel process에 대한 memory관리는 일반적으로 buddy system이나 slab allocation을 통해 진행하게 된다.
💡
Buddy system은 기본적으로 파티션 크기를 2의 지수 배로 유지하는 특징 때문에 dynamic partitioning과는 차별화됩니다. 이 특징 덕분에 buddy system은 효율적인 파티션 분할과 병합을 가능하게 하면서도 메모리 관리의 복잡성을 최소화합니다.
하지만, 이것은 동시에 buddy system이 고정된 크기의 파티션만을 사용하는 fixed partitioning과도 다르게 만듭니다. fixed partitioning은 고정된 크기의 파티션을 사용하므로 프로세스의 크기에 따라 파티션을 동적으로 분할하거나 병합하는 것이 불가능합니다.
2. Simple Paging
모든 OS의 memory management의 기본이 되는 방법. 기본적으로는 process에 대응되는 physical address space가 연속될 필요가 없게끔 해주는 방법론을 제시하는 것이다. (이러한 concept위에 virtual memory가 더해져서 더 강력해진 것이다.)
💡
4KB를 일반적으로 사용함 (4096 = ). 이 경우에는 offset를 다루는 bit는 12개
Page가 크면 page table의 entry가 작아짐. 반대로 page가 작아지면 page table의 entry가 커짐.
→ 그래서 page의 크기를 정하는 것이 중요하다.
💡
Simple paging은 기본적으로 모든 page가 memory 상에 있는 것을 전제로 한다. 결과적으로는 demand paging을 활용하여, 일부의 페이지만 memory에 올리는 방향으로 나아갈 것이지만 아직까지는 physical memory에 contiguous하게 저장하지 않아도 되게끔하는 기능만 수행한다고 이해해야 한다.
Paging의 단점은 무엇인가?
동일한 크기로 자르는 과정에서 internal fragmentation 문제가 발생할 수 있다.
Procedure
- Physical address space of a process can be
noncontiguous💡이전까지는 logical space가 physical space에 contiguous하게 mapping이 되어야하는 constraint가 존재했었음.사실 모든 이미지를 다 저장해 둘 필요가 없음. 현재 PC가 사용하는 영역에 대해서만 physical memory에 위치시키면 충분하다.
💡Simple paging의 경우에는 기본적으로 physical memory가 logical memory보다 크기가 더 크고, 실행하고자하는 process에 대응되는 page를 모두 다 physical memory에 저장한다고 생각하면 된다. (실제로는 logical address의 bit size와 physical address의 bit size가 다르다. 그래서 크게 문제가 되지는 않는다.)장점이 무엇인가?
External fragmentation 문제를 해결할 수 있음
- Divide
logicalmemory into blocks of same size calledpages(즉 page의 크기로 image를 자르는 것)
→ 몇 번째 page에 몇 번 째 줄인지를 기준으로 주소를 매핑시킴.
→ 그래서 logical address를 로 표현할 수 있음
( : page size)
💡
physical address와 logical address에서 page offset는 동일. 즉 특정 page를 특정 frame에 매핑만 잘해주면 된다. 그래서 logical address를 physical address로 바꾸기 위한
page table 과 같은 정보가 필요하게 된다.💡
즉 사실상 page table을 통해 page number를 frame number로 변환하는 작업을 수행하는 것이다.
- Divide
physicalmemory into fixed-sized blocks calledframes
→ physical memory를 frame의 크기와 동일하게 자름
→ 마찬가지로 physical address를 로 표현할 수 있음
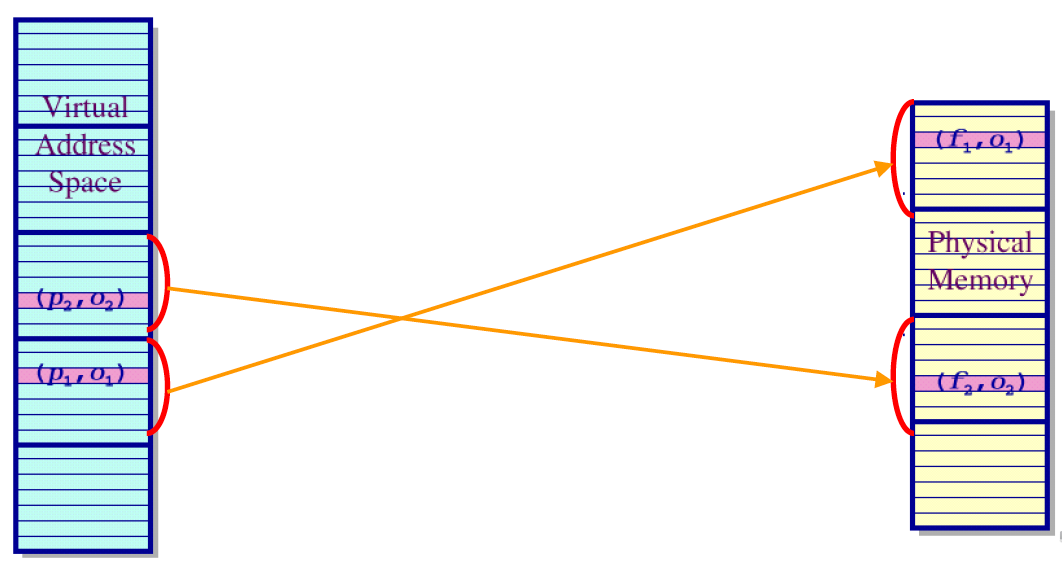
💡
All pages are not necessarily mapped to frames. 이 개념은 가상 메모리의 개념과 연결되어 있다.
앞서 살펴본 것처럼, logical address는 page number + offset으로 나눠진다.
💡
offset에 몇 비트를 할당할 것인지는, page의 크기에 따라서 결정된다. 따라서 32bit machine의 경우, 기존처럼 PC + 4가 다음 명령어가 된다.(page의 크기가 4KB인 경우에는 offset에 해당하는 bit가 12개이다.)
그렇다면 실제로 어떤 방식으로 address translation이 진행되는지 살펴보도록 하자.
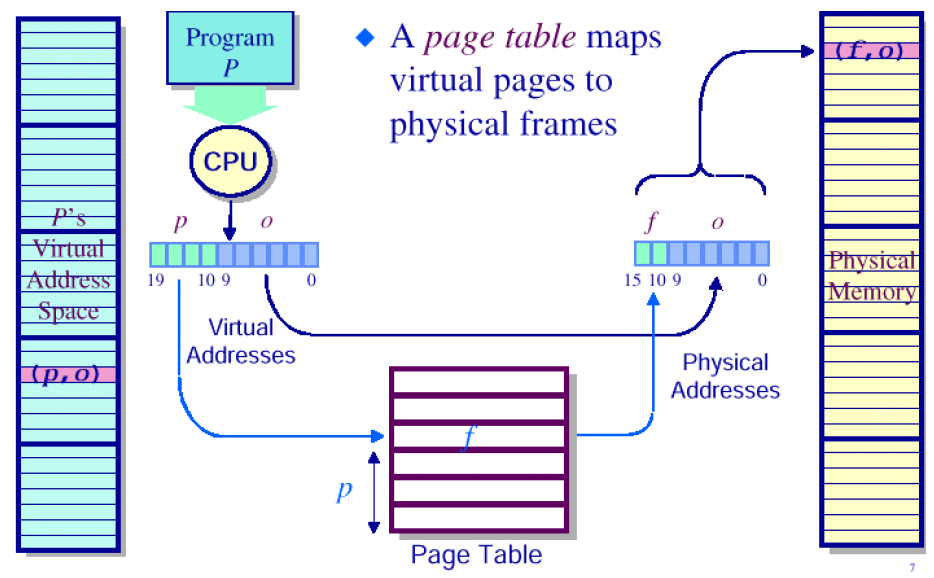
특정 page를 특정 frame에 mapping하고, 해당 mapping정보를 저장해두어야 한다. 해당 정보를 저장하고 있는 것이 page table이다.
위 그림에서는 20bit의 주소공간을 가질 수 있다고 가정. 여기에서 하위 10bit를 offset, 상위 10bit를 페이지의 넘버로 정함. (여기에서는 총 개 만큼의 page가 존재한다.)
또한 추가적으로 각 프로세스마다 page table을 가진다는 점을 매우 주의해야 한다. 그래야 logical address를 physical address로 바꿀 수 있다.
💡
offset는 동일하게 사용해주면 된다.
Example

이 상황에서는 Page table의 값 중 5개만 사용
(offset은 page와 frame의 크기가 같기때문에 그대로 사용)

근데 이 그림에서 볼 수 있는 것처럼, Page table에는 변환되는 주소 말고도 다른 정보(bit flag)들도 같이 존재한다. (present/valid bit, dirty bit, reference bit, protection bits …) 페이지의 state를 표현하는 정보를 담는 것.
→ 오른쪽 사진의 경우, 32bit Intel architecture 상에서 page table이 어떻게 사용되는지에 대한 정보를 담고 있다. (이러한 정보의 관리는 OS 가 담당하게 됨. 해당 정보를 기준으로 page replacement 등을 결정하게 된다. MMU는 단순히 address translation을 담당하는 역할을 수행한다)
예를 들어 page를 swap out하는 기준은 dirty bit에 대한 정보를 기준으로 결정한다. (Dirty bit : 실제로 페이지의 내용이 수정되었는지)
Page table의 entry 개수는 어떻게 정할 것인가?
모든 page에 대해서 정보를 다 page table이 들고 있어야 함. 개에 대한 entry를 전부 가지고 있어야 함. 즉 page의 개수와 동일하다.
Process당 unique한 page table을 가지고 있어야 하는가?
당연하다. 프로세스마다 다 다를 것이므로
💡
One table for each process. 위 문제 때문에 메모리 문제가 발생할 수 있음. 왜냐하면 CPU는 main memory에 있는 정보만을 처리할 수 있기 때문에, page table을 이용하려면 결국 해당 내용이 memory상에 있어야 하기 때문이다.
Page Sharing

서로 다른 process가 동일한 page table을 공유할 수 있다. (ex : shared library) 이를 통해 메모리를 효율적으로 사용할 수 있는 가능성이 존재.
Problem of Paging
- process마다 각각 다른 page table을 가지고 있어야 한다.
- page table은 memory상에 있어야 하는데, 이 과정에서 memory access가 2번 발생하게 된다. (일반적으로 memory access는 속도가 느리므로 overhead가 발생하게 된다.)💡Page-table base register (PTBR) : page table의 주소를 담고 있는 register
Page-table length register (PTLR) : page table 안에 있는 entry의 개수를 담고 있는 register
Solution for memory access overhead
앞서 살펴본 것처럼 paging 기법은 2번의 memory access를 해야한다는 문제점이 발생한다. (address translation을 하기 위해 1번, data/instruction을 하기 위해 1번)
그래서 등장한 개념이
TLB(Translation look-aside buffer. 즉, 캐시를 써서 속도를 빠르게 하겠다는 것이다. (즉 자주 address translation하는 것에 대해서는 translation에 대한 정보를 cache를 써서 속도를 올리겠다는 것이다.)What is TLB(Associative memory)?
Associative register로 구성이 되어있고, 병렬 search가 가능한 메모리구조. key, value pair를 가지고 있는 여러 개의 entry를 가지고 있음.
💡content-addressable memory (CAM) 으로도 불림
해당 테이블에 정보를 넣겠다는 것.
→ CAM은 병렬 search가 가능하다. key값을 넣으면 value를 O(1)에 바로 구할 수 있음. 이러한 병렬 처리를 가능하게 하는 하드웨어가 associative memory
→ 즉 p(key)값을 주면 f(value)값을 아주 빠르게 구할 수 있게 됨
→ TLB는 레지스터로 구현되기 때문에 굉장히 빠르게 정보를 얻을 수 있다.
💡단, HW cost가 굉장히 비싸다.Procedure of Paging with TLB

- TLB를 먼저 검사하고 해당 key에 대응되는 value가 있는지를 검사한다.
- TLB에 해당 내용이 없으면, page table을 통해 조사한다.
→ TLB에 모든 page table 정보를 다 넣을 수 없음 (메모리가 제한되어 있기 때문)
💡TLB에 어떤 값을 넣는 지에 따라 성능과 직접적으로 관련이 있게 된다. 이를 위해 고려할 수 있는 것이 spacial/temporal locality이고, 이를 활용하게 되면 hit 확률을 높일 수 있다.Effective Access Time (EAT)
대략적으로 어느정도의 access time이 걸리는지
Associative lookup time : time unit(이걸 줄이는건 hardware영역)
Memory lookup time: 1 microsecond
Hit ratio : (해당 페이지 number가 TLB안에 들어있을 확률)
💡EAT를 줄이기 위해서는 현실적으로 hit ratio를 높여야 한다. 가장 쉬운 방법은 TLB의 크기를 키우는 것.💡주의해야할 지점은 TLB에 translation에 필요한 정보가 담기는 것이지 page가 담기는 것이 아니라는 것이다.
- 고정된 크기의 page로 나눔으로써 Internal fragmentation이 발생할 수 있다. (기존 fixed partitioning에서의 문제점이 그대로 나타나게 된다.)
Handling Large Page Table

→ 즉 process당 4MB를 확보해야하는 문제점이 발생
(1개의 process당 page entry의 개수는 , 즉 100만개)
여기에 만약 1000개의 process가 있다고 하면, 무려 4GB를 Page table을 저장하는데 사용해야 한다.
추가적으로 64bit machine의 경우에는 문제가 더 심각해지는데 왜냐하면 무려 개의 page entry가 필요하기 때문이다. 따라서 이렇게 큰 page table를 어떻게 다룰 것인지에 대한 방법론이 필요하게 된다.
💡
즉 단순히 page table을 구현하게 되면, 그 크기가 굉장히 커질 수 있는 문제가 발생하게 된다.
Observation
page table이 큰 경우에 일반적으로 사용하는 방법은 3가지가 존재한다.
- Multi-level paging
- Hashed page table
- Inverted page table
💡
결과적으로 page table도 메모리 상에 있어야 하는데, 이거를 contiguous하게 저장하는 것도 문제가 발생할 수 있음.
물론 virtual memory까지 배우게 되면, 결과적으로는 전체 page의 일부분만 physical memory에 저장하는 쪽으로 나아가게 된다.
Multi-level paging
Page table의 level을 여러 개 둬서 필요한 entry만 RAM에 적재하자는 것. 이를 통해 outer-page table과 관련된 page of page table만 RAM에 넣으면 됨.
💡
Multi-level paging을 하게 되면, 32bit machine 기준으로 4MB에 해당하는 page table을 contiguous하지 않게 메모리에 저장할 수 있다는 장점이 존재한다. 계속 강조하지만, virtual memory까지 엮게되면 page table도 swap-out시킬 수 있다.
22. 페이징(Paging)과 페이지 테이블(Page table)
페이징과 페이지 테이블은 현대 운영체제 메모리 관련 컨셉에서 아주 중요한 것이므로 잘 정리해두자! 1. 페이징(Paging) address space를 연속적으로 할당하지 말고, 페이지라는 단위로 쪼개서 사용하는 것이다. 먼저, 프로세스의 메모리를 page 단위로 자르고, 실제 physical 메모리도 page 단위로 쪼갠다. 이 때 쪼개진 physical memory를 page나 page frame이라고 부른다. 그리고 Virtual address의 프레임을 Physical 메모리의 프레임으로 mapping 하는 방법이다. 이렇게 paging으로 메모리를 관리하면, external fragmentation이 발생하지 않는다. 물론 internal fragmentation은 발생할 수 있지만, 치명적인 ..
 https://ddongwon.tistory.com/49
https://ddongwon.tistory.com/49

실제 아이디어를 관찰해보자.
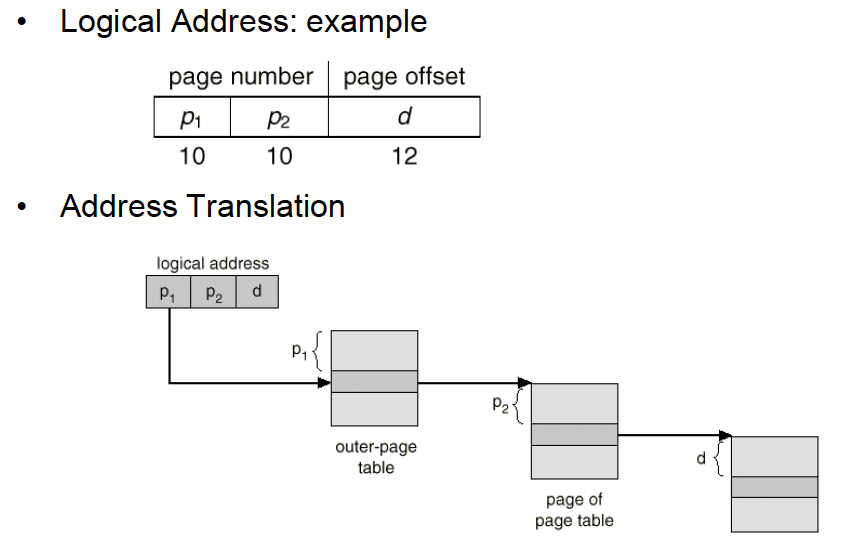
사실상 해석하는 방법은 비슷함.
초기 outer-page table의 주소는 default로 잡고, 이후의 주소부터는 해당 table에 저장되어있는 값을 기준으로 설정한다. 기존의 p값을 순서로 해석한다는 측면에서는 완전히 동일하다. 즉 logical address에 있는 정보들을 모두 offset으로 쓰게 됨.
💡
기존에는 20개의 bit를 page table의 index로 사용했다면, 10개씩 찢은 것
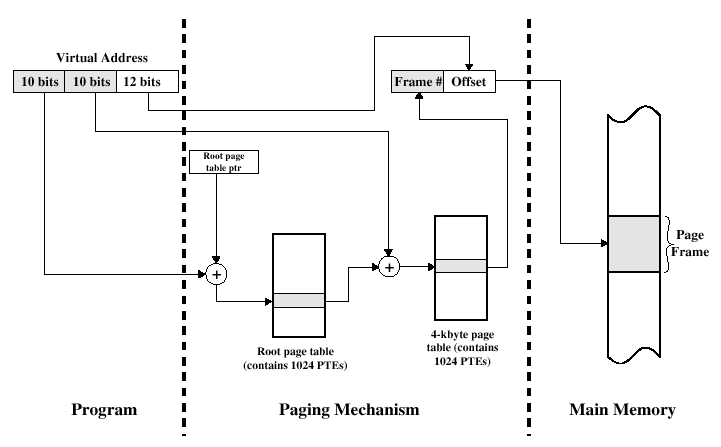
💡
CR3 register의 상위 20bit는 page Directory Base address에 대한 정보를 가지고 있다. (실행중인 process와 관련된 page Directory Base address이고, 해당 process의 PCB가 항상 가지고 있다. context switch할 때 해당 정보를 바꿔줘야 한다.)
💡
사실 virtual address 측면에서도 말이 되는 이유가 page table의 entry의 수는 이고, 1개의 entry당 크기는 byte이다. 따라서 page table의 크기는 byte이고, 각 page table을 정확하게 지정하기 위해서는 , 총 20개 bit가 필요하다.
💡
64bit machine은 주소 공간이 크기 때문에 2단계의 paging만으로 부족하므로 3단계 paging을 구축한다. Linux의 경우, 4단계 paging으로 구현되어 있다. 물론 이중 몇 개는 건너뛰는 방식을 사용하고 있음.
Problem
위 방법을 통해 runtime에 유지해야하는 page table의 storage overhead를 줄일 수 있지만, 추가적인 메모리 access를 해야한다는 점에서는 overhead가 증가하게 된다.
Hashed page table
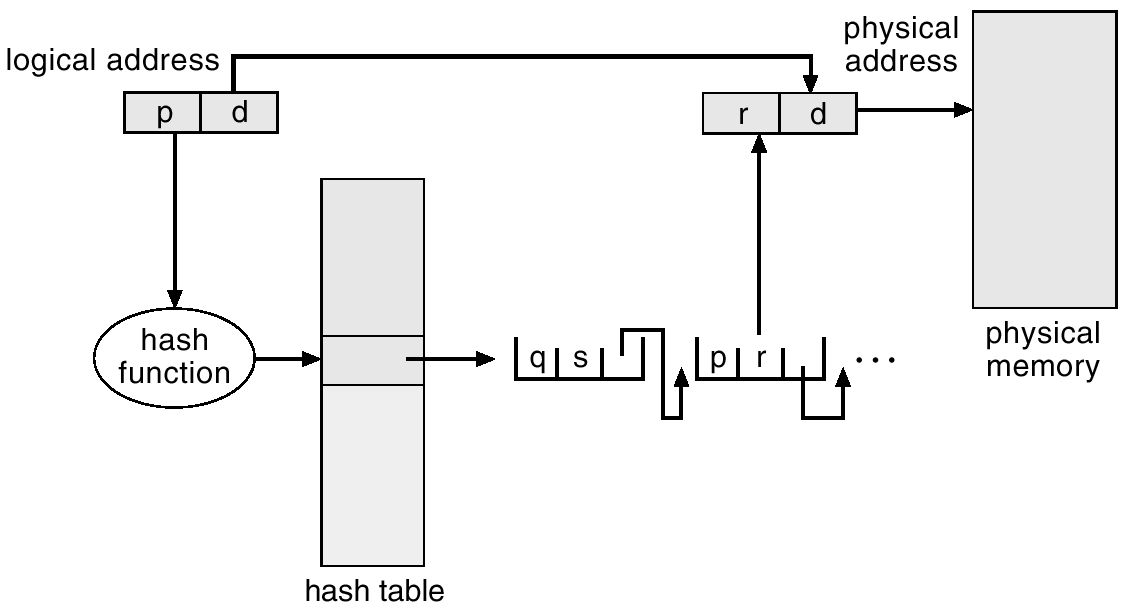
64bit machine처럼 큰 주소 공간을 가지는 상황에서 자주 사용되는 방법이다.
- hash function에 key를 input으로 줘서 hash value를 구한다.
- hash value를 hash table의 index로 활용하여, frame number를 구한다. (이때, hash collision때문에 hash table의 entry는 여러 값을 가질 수 있다는 점을 유의해야 한다. 따라서 p값에 대한 frame number가 맞는지 추가적으로 확인을 해주어야 한다.)
💡
현실적으로 큰 주소공간을 가지는 상황에서는 대부분이 비어있는 공간으로 남아있을 가능성이 높아짐. 그래서 사용할 수 있는 것이 hash table의 크기를 줄이고 공유하는 방식으로 사용 (Collision을 handling해주면 된다.)
💡
크게보면 page number를 table의 index를 구하는데 활용한다는 점에서는 기존 방법과 유사하다. 일종의 page table을 hash table로 대체했다고 이해해도 괜찮다.
위 방식을 통해 page table의 entry를 줄일 수 있게됨.
Inverted page table
프로세스당 하나의 테이블을 가져야한다는 가정을 깨는 것.
→ System 전체에 하나의 page table을 유지를 하자. 즉 frame 1개 당 하나의 page table entry를 만들자는 역발상
💡
기존에는 page에 대응되는 frame를 찾았다면, 이제는 반대로 frame에 대응되는 page를 찾는 방식이라서 inverted paging이라고 이해하면 된다.
이때 page table의 각 entry에는 pid와 logical address가 저장되어있다. (즉, 해당 frame의 소유자가 누구인지를 저장해둔 것)
💡
pid는 동일한 프로그램이여도 unique 하기 때문에 정확하게 구분할 수 있다.
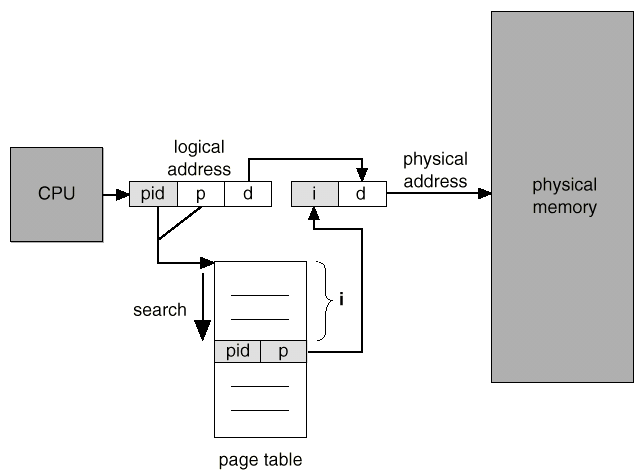
→ 그리고 그 순서를 이용해서 주소를 정의하자. (index를 주소를 쓰겠다는 것) 위 상황에서는 frame이 i로 대응됨.
💡
frame number가 index로 바뀐 것
각 process마다 page table을 저장할 필요가 없으므로 필요한 메모리가 줄어들게 된다.
Procedure
- page table에서 pid와 p가 동일한 entry를 탐색
- 해당하는 index (i)가 frame number이다.
- 해당 frame number와 offset를 이용해서 physical address로 바꾸게 된다.
page table의 entry의 개수는 몇개인가?
Physical memory의 frame의 개수와 동일하다. 예를 들어 physical memory가 2GB이고 page의 크기를 4KB로 잡았다고 하면, 개 필요하게 된다.
Problem
- Search 하는데 걸리는 시간이 걸림
→ Hash table을 사용함으로서 위 문제를 해결할 수 있다.
💡단 이렇게 되면 memory reference가 증가되는 단점이 발생한다. 한번은 hash table을 참조하는데, 다른 한번은 page table을 참조하는데 필요하게 된다.
- 만약 page fault가 되면 어떻게 할 것인가
→ 굉장히 복잡해짐. 그래서 storage에 전통적인 page table를 바탕으로 정보를 update하는 과정을 거쳐야함. 해당 page table은 메모리에 있는 것이 아니라, 하드디스크에 있기 때문에 overhead가 커지긴하지만 RAM에 가지고 있는 상황은 아니기 때문에 RAM 공간에 대한 이슈를 줄일 수 있다.
- Search 하는데 걸리는 시간이 걸림
💡
기존에는 page table entry의 주인이 page number로 결정되었다. 반대로 inverted page table의 경우에는 page table entry의 주인이 frame number로 바뀐 것. (즉 대응되는 index가
frame index가 된다.)3. Simple Segmentation

Paging은 근본적으로 logical address space와 physical address space를 고정된 크기 로 자르고, 이를 mapping시키는 작업을 수행하는 것이다. (Paging이 나오기 전에 등장한 개념)
Paging의 문제점
고정된 크기로 자르는 과정에서 이미지의 다른 부분의 영역이 섞일 수 있다. 예를 들어 일부분은 코드이고, 일부분은 data일 수 있다. Protection의 관점에서 봤을 때는 자연스럽지는 않음. 예를 들어 code 영역은 read-only인 반면 data는 read 뿐만 아니라 write도 가능해야 한다. 즉 paging은 안에 들어가 있는 객체의 특성을 무시하게 된다는 문제점을 가짐.
그래서 segment 단위로 메모리 관리를 하자는 관점에서 등장한 것이 segmentation 기법이다.
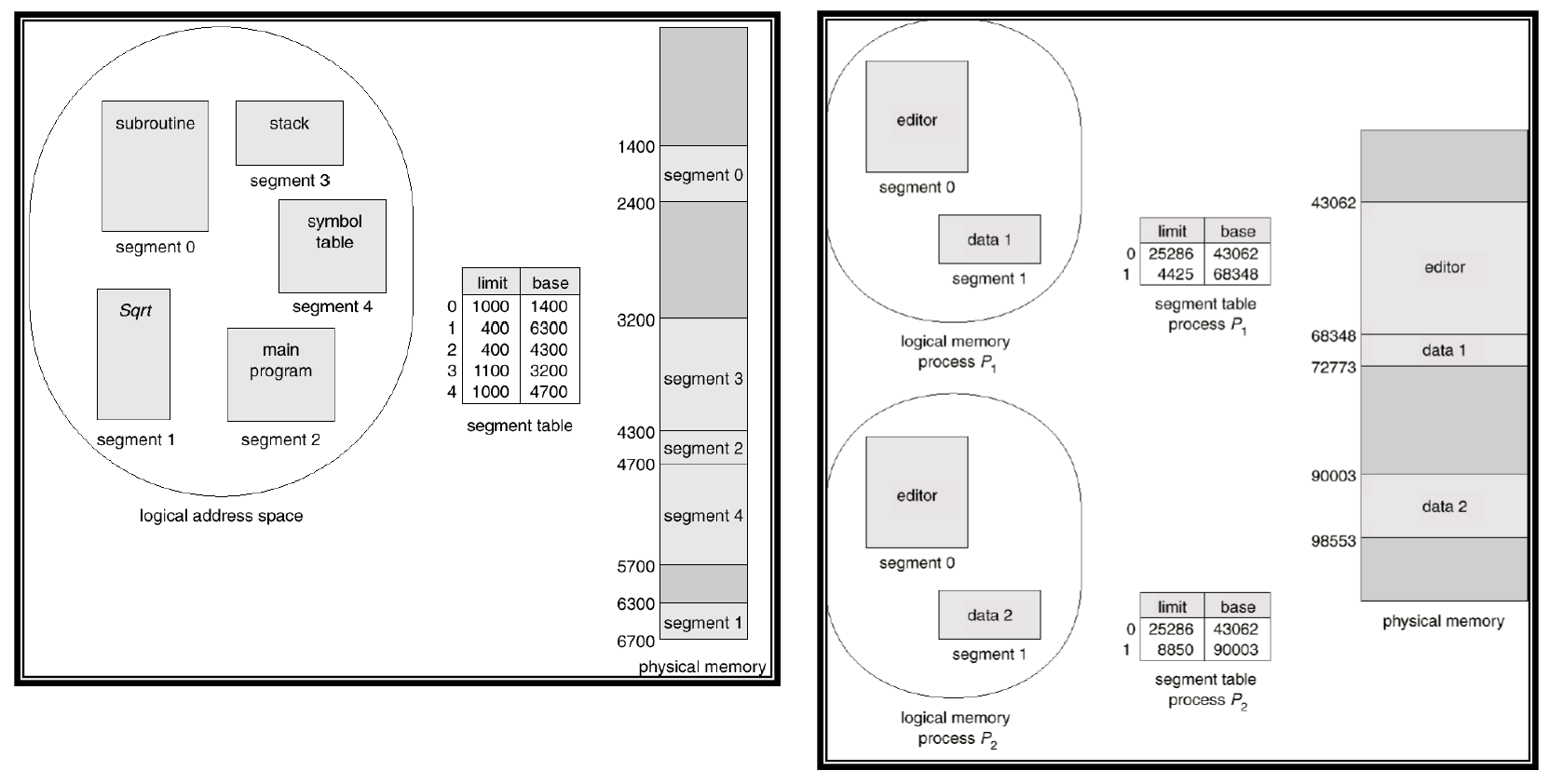
segment table을 사용해서 mapping을 하게 된다. (segment table의 entry는 base 와 limit 에 대한 정보를 가지고 있음)
오른쪽은 2개의 process가 동일한 physical memory를 사용하고 있는 상황. 각각 process마다 segment에 대한 정보가 있음.
💡
paging에서는 여러 segment가 섞일 수 있는 반면, segmentation을 하게 되면 동일한 segment끼리만 묶이게 된다. 이를 통해 특히 동일한 프로세스들 끼리의 segment에 대한 공유가 쉬워진다.
Segmentation Architecture
logical address가 다음과 같이 나타나게 된다.

segment table은 limit과 base로 구성됨. 예를 들어 segment가 10개 있다고 하면, segment table의 entry의 개수는 10개.
- Base : 해당 segmentation에 대한 정보를 담고 있는 영역이 physical memory상에서 어디에 위치하는지
- Limit : segment의 길이 (Limit을 벗어났는지 체크하는 용도로 사용)
→ segment의 크기에 대한 정보를 담고 있음
이를 지원하기 위해 2가지의 Register가 필요함.
💡
Segment-table base register (STBR) : segment table의 주소를 담고있는 register
Segment-table length register (STLR) : segment table안에 있는 entry의 개수를 담고 있는 register
Paging에서의 register와 구분해서 정리해야한다.
Property
- Relocation/allocation
- Dynamic하게 할당하는 상황과 거의 유사
- Segment가 context의 특징에 따라서 서로 다른 크기로 정의되기 때문에 결과적으로 Dynamic partitioning의 특성과 유사할 수 밖에 없다. 즉
external fragmentation문제가 발생하게 된다.
- 따라서 dynamic partitioning과 마찬가지로 어떠한 기준으로 넣을 것인지가 중요하게 된다. (First fit, Best fit, etc)
- Sharing
Segment별로 protection을 다르게 설정해야하는 상황이 존재할 수 있다. 예를 들어 code는 read only만 되게끔 설정해야 한다. 이러한 상황을 segmentation에서는 반영할 수 있고, 이를 통해 프로세스 간 segment 공유가 쉬워지게 된다.
💡
segmentation은 결국 dynamic allocation과 거의 유사하므로 external fragmentation문제가 발생한다.
Comparison between Segmentation and Paging
Segmentation은 Dynamic allocation의 특수한 경우로 생각할 수 있다. 즉, External fragmentation 문제를 겪을 수 있다.
반면, Paging은 Internal fragmentation 문제를 겪을 수 있다. (External fragmentation에서는 자유로움)
→ Segmentation을 protection의 정도를 다르게 할 수 있는 일종의 tool로 볼 수 있다. (paging에서는 protection bit를 설정함으로써 해당 기능을 제공할 수 있다.)
추가적으로 Segmentation과 Paging 모두 sharing에 대한 부분은 장점으로 가지고 있다는 점에서 공통점을 가지고 있다.
💡
이후에 등장한 개념이 segmentation와 paging을 결합해보자는 것
Segmentation with paging
Segmentation와 Paging을 잘 섞어보자!
Segmentation은 segment별로 access를 제한할 수 있는 장점이 있고, Paging은 external fragmentation이 발생하지 않는다는 장점이 있으니까 장점을 잘 살려보자는 것.
💡
실제로 x86의 경우에는 segmentation과 paging 모두를 지원한다.
기본적으로 segment 단위로 찢고 따로 처리를 해서 access 권한을 잘 처리하고, 각 segment별로 paging을 하자는 것. (즉 fixed size된 chunk에 segment를 넣는 paging을 처리하게 됨)
→ 이를 통해 segment가 pageable 하게 되는 것.

위 그림에서 볼 수 있는 것처럼 각 segment별로 page가 나눠져 있음. 이 과정을 통해서 paging의 특성을 활용할 수 있게 됨.
💡
추가적으로 이렇게함으로써 필요한 segment에 해당하는 page들의 일부만 메모리에 있을 수 있게 됨. 나중에 virtual memory를 배우고 오면, demand paging을 통해 필요한 page만 physical memory에 존재하게끔 할 수 있다.
Procedure
logical address는 로 구성됨

일종의 two-level paging과 거의 유사하게 이해할 수 있음.
💡
logical address의 상위 몇 bit를 segment number를 지정하는데 사용하게 된다.
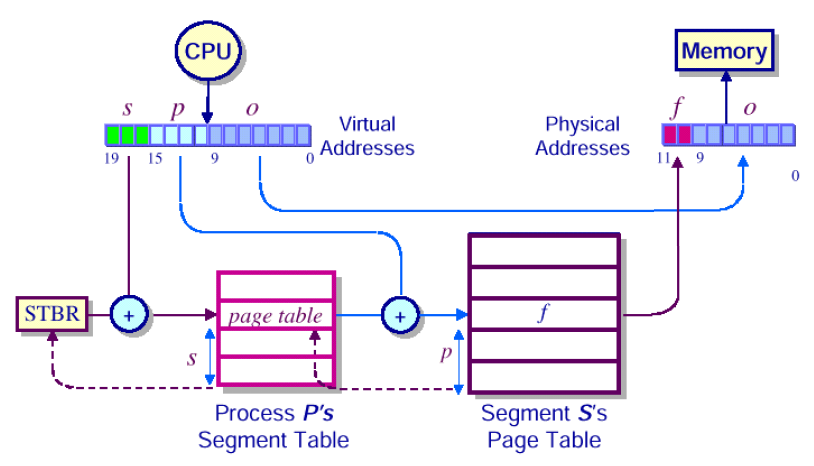
Segment Table의 위치를 어떻게 알 수 있는가?
system이 segment table에 대한 base address를 가지고 있어야하는데, 해당 정보는
STBR이 가지고 있다.
segment table에 저장된 값은 해당 segment에 대응되는 page table의 base address이다. 해당 값을 logical address에 있는 p값을 index로 해서 frame 번호를 알아내게 된다.
→ 최종적으로 frame번호와 offset번호를 토대로 physical address로 변환하게 된다.
💡
기존에 page table entry number로 사용하던 bit를 일부 segment table entry number로 사용한다는 점만 살짝 차이가 있다.
Additional Benefits

- Protection : 각 segment별로 protection을 다르게 설정할 수 있음 (Segmentation의 장점)
- Sharing : 하나의 segment로 구성된 page table을 공유할 수 있음 (원래 paging이나 segmentation이 가지고 있던 장점이기는 하다.)
- Segmentation의 문제점인 external fragmentation 문제를 해결할 수 있다.
Problem
logical memory가 physical memory의 어느 부분에 매핑되었는지 확인하기 위해서는 segment table → page table 순서로 접근해야하기때문에 메모리 접근 에 대한 overhead가 발생하게 된다.
💡
결과적으로 multi-level paging에서의 단점이 그대로 발생하게 된다.
Segmentation with Paging (Intel x86)
여기서부터는 HW dependent한 개념 (이후에 Linux가 이 개념을 어떻게 이용하는지 볼 예정)
3가지의 address가 존재한다.
- Logical (virtual) address
process 관점의 address
16bitsegment selector,32bitoffset💡실질적으로 offset은 32bit에 해당하는 범위를 전부 사용하는 것이 아니라, 대응되는 segment의 크기에 의존해서 사용할 수 있는 범위가 결정되게 된다.💡Logical address는process가 사용하는 address이다.
- Linear address
segmentation unit이라는 것을 거쳐서 logical address가 linear address로 바뀜
💡Linear address는CPU가 사용하는 address이다.
- Physical address
linear address가 paging을 통해 physical address로 바뀜


여기에서 GDT(Global Descriptor Table)가 실질적으로 segmentation table 역할을 수행하고 있음. 그래서 logical address가 몇 번째 segment의 몇 번째 offset에 있는지를 의미하고 이를 통해 linear address를 구함. 이후 2단계 paging을 통해 physical address로 바꿈 (page의 크기가 4kB라서 offset bit가 12개)
→ 위 개념은 MMU에 들어가있음. 그래서 OS개발자는 해당 개발자는 위 개념을 얼마나 사용할 것인지를 결정해야 한다.
Segmentation
Logical address <segment identifier, offset>
Segment identifier : 16bit, called Segment Selector
Process가 segmentation register를 제공한다.
- cs (code segment register) : program instruction에 해당하는 segment를 가지고 있는 주소를 저장
- ds (data segment register) : static and external data에 해당하는 segment를 가지고 있는 주소를 저장
- ss (stack segment register) : current program stack에 해당하는 segment를 가지고 있는 주소를 저장
- es, fs, gs : general purpose and refer to arbitrary segments
💡
프로세스가 특정 세그먼트를 사용해야 할 때마다 매번 GDT를 조회하는 대신, 세그먼트 레지스터에 저장된 정보를 활용해 빠르게 메모리 접근을 수행하겠다는 것. 일종의 캐싱을 수행하고 있다고 생각해주면 된다. 즉 GDT에서 정보를 찾아서 해당 내용을 segment register에다가 저장한다.
→ intel의 경우에는 각각의 image를 따로 지정하겠다.
💡
위에서 언급한 내용은 Architecture적으로 지원한다는 것이지 OS에서 활용하는 것은 다른 문제이다. Windows의 경우에는 segmentation을 정교하게 사용하는 반면, Linux의 경우에는 가급적 segmentation을 사용하지 않는다.
왜 Linux의 경우 segmentation을 최소한으로 사용할까?
Linux의 kernel 철학과 관련이 있음. 어떤 HW든 linux가 돌아가게끔 하는 것이 목적(Portability와 관련). 즉 kernel 코드를 최대한 바꾸지 않는 것이 목표이다. 특정 CPU의 경우에는 segmentation을 거의 지원하지 않기 때문에, 최소한으로 사용하고자 하는 것. (Paging의 경우에는 거의 모든 CPU architecture가 다 사용하고 있기 때문이다.)
Paging in Hardware (Intel x86)

Segmentation을 거치게 되면, linear address가 만들어지게 된다.
→ 32bit machine의 경우, byte (즉 4GB만큼의 영역에 해당)
이러한 linear address를 paging을 거쳐서 physical address로 변환하게 된다.

CR0, CR1, CR2, CR3라는 control register라 불리는 레지스터가 있음. 이 중 CR0와 CR3가 memory management에 많은 관여를 하고 있다.
그 중, CR0에 PG(paging enabling bit)가 있다. 해당 bit는 운영체제를 재부팅하고 초기화하는 과정에서 PG bit를 1로 세팅을 하면, 그 순간부터 CPU가 paging 모드로 바뀐다. 즉 MMU가 동작을 하게 된다.(그전까지는 real mode라고 해서, 기본적인 메모리 관리모드로 돈다. 16bit로 돈다.)
CR3 상위 20비트는 page Directory Base address로 사용된다. 즉 첫번째 page table의 base address가 저장되어 있다.
→ 모든 process는 자기 자신의 page table을 가지고 있어야 한다.
→ 그렇다면 process switch를 할 때 register만 바뀌는 것이 아니라, access하는 page table도 바뀌어야 한다. (즉 process만 단순히 바뀌는 것이 아니라 memory management가 바뀌어야 한다.) 그래서 해당 process의 PCB안에 내 process에 속한 page table이 어디에 속하고 있는지 알고 있다. (task_struct안에 해당 정보를 가지고 있는 것)
→ 예를 들어 특정 process가 schedule이 되었으면, PCB안에 들고 있는 page table에 대한 정보를 Page Directory Base Address에 써놓는 것.
💡
OS가 CR3 register 상위 20bit 즉 Page Directory Base Address에 정보를 써놓으면, 하드웨어적으로 physical address로 바꿔준다. 정확한 내부적인 메커니즘은 하드웨어적으로 접근해야함.
Regular Paging (Intel x86)
Page size : 4KB (4096 byte) (4MB로 두는 경우는 Extended paging라고 한다.)
Linear address : 32-bit
→ 따라서 page를 담당하는 offset bit는 12bit.
최상의 10bit는 첫 번째 table의 index, 그 다음 10bit는 두 번째 table의 index로 사용함.
💡
two-level paging을 사용한다
첫 번째 page table : page Directory라고 부름
두 번째 page table : page Table이라고 부름
💡
맨 마지막으로 Page라고 표기된 것은 frame이다.

위 사진은 segmentation을 거치고 나온 linear address이다. cr3 의 상위 20bit에 있는 page Directory Base address(해당 프로세스가 사용하고 있는 첫번째 page table의 base address)를 사용한다.
💡
Scheduling을 할 때 마다 해당 프로세스의 PCB 안에 있는 page Directory Base address를 cr3의 상위 20bit에 써야 한다.
최종 Page Table에는 Frame number가 있다. 해당 정보와 offset를 이용해서 physical address로 최종적으로 변환이 완료되게 된다.
💡
맨 마지막 page table에 들어있는 정보는 frame number에 대한 정보이다.
Page Directory and Page Table
Page Table의 entry의 모습에 대해서 구체적으로 살펴보고자 하는 것

위 그림은 실제로 page Directory나 page Table의 entry에 무엇이 들어가 있는지를 보여주는 그림이다.
💡
Process당 1개의 Page Directory table을 가지고 있음

Page Directory의 entry의 개수는 몇 개인가?
Page Directory index를 담당하는 bit가 10개이므로 총 개 만큼 존재한다.
Page Table의 entry의 개수는 몇 개인가?
마찬가지 이유로 총 개 만큼 존재한다.
그렇다면 Process당 Page Table의 개수는 몇 개인가?
1024개. 왜냐하면 Page Directory의 entry마다 Page Table이 1개씩 존재하므로
그래서 하나의 Process와 관련된 page Directory와 page Table의 총 합은?
1025개 (1 + 1024)
그렇다면 1개의 page table의 용량은 얼마인가?
1024 * 4byte = 4KB
그렇다면 하나의 process와 관련된 page table의 총 용량은?
4KB * 1025 = 4MB 근방
나머지 12bit는 bit-flag. 즉 page의 특성을 가지고 있는 bit로 사용하게 된다.
💡
page의 하위 12bit에 대한 정보를 기준으로 page swap하는 기준의 정책을 결정한다.
- Page Present bit : 이 값이 1이면 실제로 physical memory에 있다고 하는 것이고, 0이면 없다는 의미 (page fault와 관련되어있는 bit이다.)
- Read/Write bit : 이 값이 0이면 이 page는 read only이다. 1이면 read/write를 할 수 있는 page
- User/Supervisor bit : 이 page가 user에 속한 페이지인가, kernel에 속한 페이지인가 판단하는 bit
- Accessed bit : 해당 page가 한번이라도 읽기/쓰기(Access)를 했는지 (했으면 1, 아니면 0)
- Dirty Bit : 해당 페이지의 내용이 수정(쓰기)이 되었는지. 즉 RAM에 올라와서 수정이 되었다는 의미 (했으면 1, 아니면 0)💡Demand paging을 하다보면 특정 page를 swap-out시켜야 한다. 그렇다면 어떤 기준으로 swap-out될 것인가? 사실 생각해보면 access bit가 0인 경우를 먼저 고려하고, dirty bit이 0인 경우를 나중에 고려해야한다. 왜냐하면 swap space에 수정된 것을 반영해서 저장해야하기 때문이다. (dirty bit가 0인 것은 그냥 바로 swap-out시킬 수 있다.)
→ 즉, process가 가지고 있는 page Directory Base address만 알게되면, 나머지 모든 것은 HW적으로 translation을 해서 physical address로 변환이 된다. 그리고 page Table에 있는 bit를 기준으로 여러 가지 semantic을 가질 수 있게 됨.
Extended Paging (Intel x86)
Page 크기를 바꿀 수 있다. 어떤 경우에는 4KB가 아니라 4MB 단위의 page 크기를 줄 수 있다. (offset이 22bit가 된다.)
→ 이런 것을 Extended paging이라고 함
그러면 logical address를 어떤 기준으로 offset를 12bit를 줄지 22bit를 줄지 어떻게 아는가?
page Directory entry의 control bit 중 page size bit를 읽는다.

그래서 offset를 22bit로 두게 됨. (10 + 12) : page의 크기는 4MB(byte)
💡
page table의 크기와 page의 크기를 구분할 것 (page의 크기는 offset의 크기와 관련이 되어있고, page table의 크기는 index의 크기와 관련이 되어있다.) 또한 추가적으로 크기를 고려할 때는 각 page table의 entry는 4byte라는 것을 고려해야하고, page는 1byte 단위라는 것을 고려해야 한다. 그래서 결과적으로 크기가 page table의 크기와 page의 크기가 같아지게 된다.
💡
page table의 크기 : byte = byte = 4KB
💡
page의 크기 : byte = 4MB
💡
Extended여부는 page Directory Entry안에 있는 page size bit를 기준으로 판단하게 된다. 1이면 Extended paging을 사용하는 것
그렇다면 page Directory의 entry의 개수는?
개
그렇다면 page Directory의 크기는?
4byte * 1024개 → 4KB
즉 process당 4KB page table이 존재
그러면 아키텍쳐 입장에서는 page를 4MB를 써야할지 4KB를 써야할지 정확히 어떻게 구분할 것인가?
- 하위 12bit에 있는 정보들 중 page size bit를 점검한다.
- 만약 page size bit가 1이라면, 상위 20bit를 frame index로 취급한다.
→ offset는 자연스럽게 virtual address에서 나머지 22bit를 잡아주면 된다.
- 만약 page size bit가 0이라면, 상위 20bit를 page table의 base address로 취급한다.
- 만약 page size bit가 1이라면, 상위 20bit를 frame index로 취급한다.
💡물론 page extend bit가 1이라면, 상위 20bit 중 하위 10개만 frame index에 대한 정보를 가지고 있어야 한다.- 하위 12bit에 있는 정보들 중 page size bit를 점검한다.

일반적인 방식
💡
맨 마지막에 있는 page는 frame이라고 이해하면 된다.

나머지 bit는 hardware information을 담고 있음
Question 1
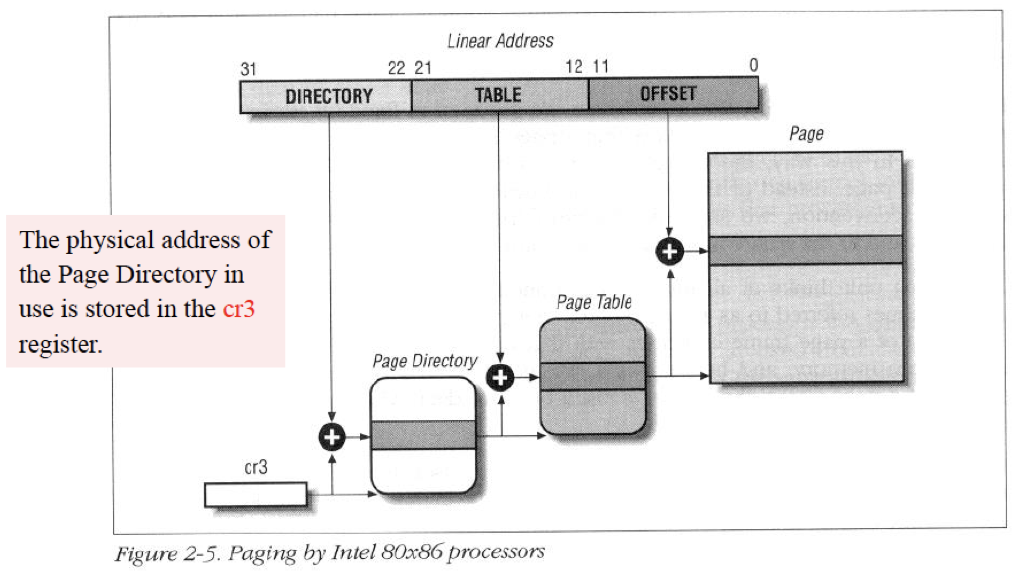
- page Directory base address에 해당하는 bit는 몇 개이고, 정확히 어디에 저장되어있는가
- 1번의 문항에서 왜 해당 bit가 나오게 되었는지 구체적으로 서술하시오
- page directory의 entry는 총 몇 bit로 구성되어있는지 서술하시오. 또한 page directory의 entry는 총 2개의 part로 찢어질 수 있는데, 각 몇 bit로 찢어지고 왜 그렇게 찢어지는지에 대해서 서술하시오
- Intel x86에서는 4KB page 뿐만 아니라 4MB page도 지원한다. architecture입장에서 4KB page를 사용하는지, 4MB를 사용하는지 어떻게 구체적으로 알 수 있을 것인지를 서술하시오
Answer
- cr3의 상위 20bit에 해당 정보가 들어가 있다.
- page directory의 총 entry는 총 개이고 각 entry의 크기는 4byte이다. 따라서 총 크기는 byte이므로 정확히 주소를 찍으려면 개의 bit가 존재해야 한다. 그래서 20bit이다.
- 2번과 비슷한 논리로 page table의 entry의 개수는 개이고 크기는 4byte이므로 이를 표현하기 위해서는 개의 bit가 존재해야 한다. 따라서 page table base address를 담는 bit는 20개, page에 대한 attribute를 담고 있는 bit가 12bit이다.
- 3번에서 언급한 12개의 bit중에 page extend bit가 있다. 해당 정보를 보고 상위 20bit를 “frame index”로 읽을 것인지 아니면 page table의 base address로 읽을 것인지를 판단해주면 된다.
Question 2
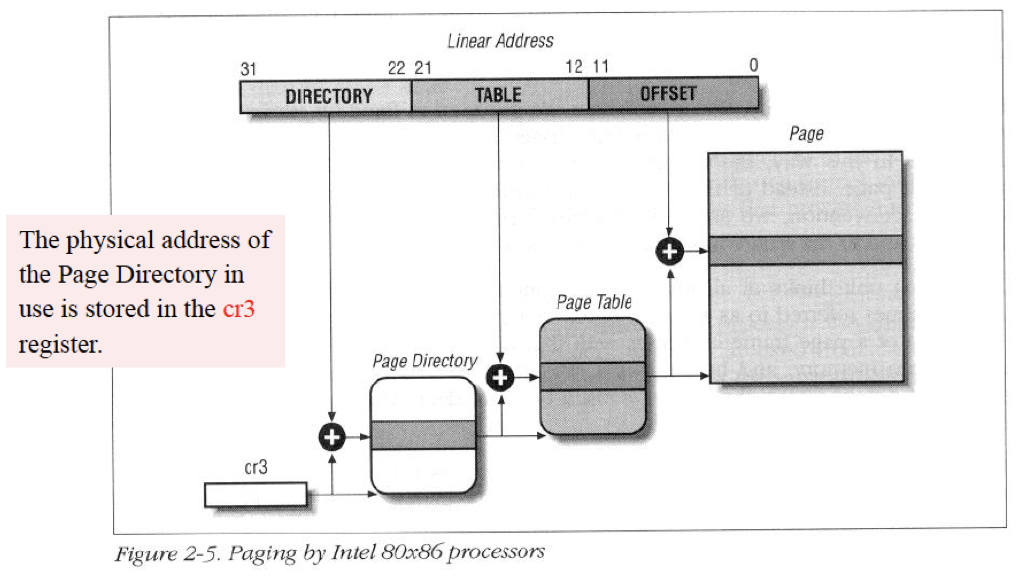
Directory에 해당하는 bit를 12bit, table에 해당하는 bit를 10bit으로 설정했다고 가정하자.
(단, page directory와 page table의 entry의 크기는 32bit라고 가정하고, page directory base address는 여전히 cr3가 가지고 있다고 가정하자.)
- page Directory base address에 해당하는 bit는 몇 개이고, 정확히 어디에 저장되어있는가. 왜 해당 bit가 나오게 되었는지 구체적으로 서술하시오
- page directory의 entry는 총 2개의 part로 찢어질 수 있는데, 각 몇 bit로 찢어지고 왜 그렇게 찢어지는지에 대해서 서술하시오
- page table의 entry는 총 2개의 part로 찢어질 수 있는데, 각 몇 bit로 찢어지고 왜 그렇게 찢어지는지에 대해서 서술하시오
Answer
- page directory의 entry의 개수가 이고 각 크기가 byte이므로, 해당 page directory의 주소를 표현하기 위해서는 = 18개의 bit가 필요하다.
→ 즉 cr3의 상위 18개의 bit에 저장되어있어야 한다.
- page table의 entry의 개수가 이고 각 크기가 4byte이므로, 해당 page table의 주소를 표현하기 위해서는 = 20개의 bit가 필요하다.
→ 즉 상위 20bit에 page table base address가 저장될 것이고, 하위 12bit에는 page에 대한 attribute가 저장될 것이다.
- page directory가 12bit, page table가 10bit로 설정했다는 의미는 offset이 10bit로 설정했다는 의미이다. 즉 page의 크기는 1KB이다. 따라서 frame의 주소를 표현하기 위해서는 = 22개의 bit가 필요하다
→ 즉 상위 22bit에 frame number가 저장될 것이고, 하위 10bit에는 해당 page에 대한 attribute가 저장될 것이다.
Paging in Linux (Intel x86)
이전까지는 intel architecture에 대한 HW적인 이야기
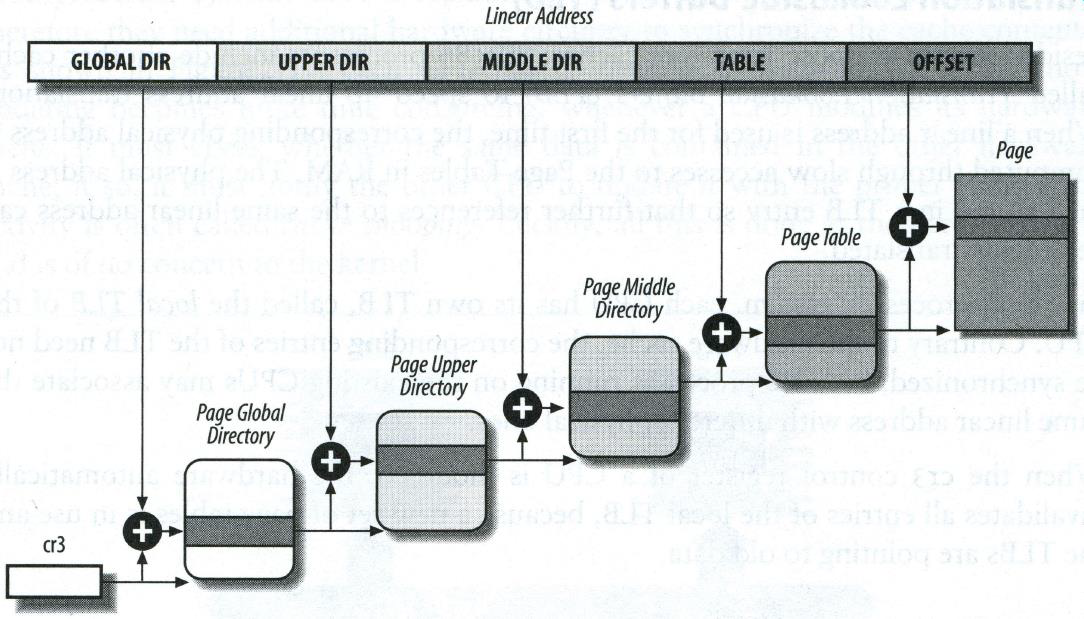
각각은 kernel의 자료구조
리눅스 커널은 Linux 2.6.11부터 4단계 paging을 지원하고 있다.
왜 이렇게 했을까?
Scalability때문이다. 즉, 리눅스 커널의 목적 중 하나가 모든 CPU architecture를 지원하고, 미래에 나올 것도 지원하면서 HW dependancy를 줄여서 커널의 코드를 최대한 바꾸지 않는 것이다. 그래서 이렇게 generic하게 만들어진 것. 리눅스의 portability의 이식성에 대한 철학과 관련이 있음.
만약 32bit Intel architecture이라고 하면 page Directory와 page Table이 해당 kernel의 자료구조와 대응되어야할 것 같은데 어떻게 되는가?
가운데 2개를 쓰지 않는다. page Global Directory를 page Directory에 대응하고, page Table을 page Table에 대응시킨다.
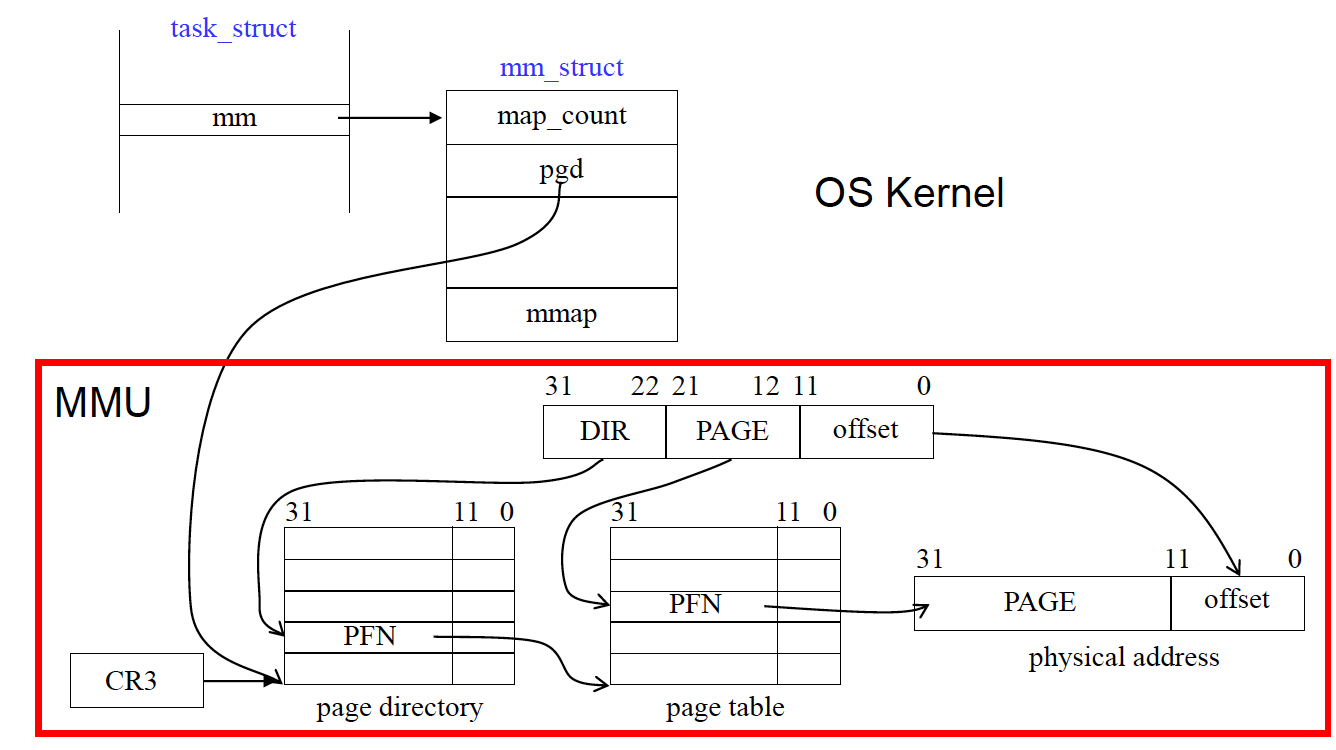
실제로는 다음과 같은 과정으로 진행됨. 이러한 과정은 kernel이 관여하는 것이 아닌 MMU라는 CPU안에 있는 HW가 translation하는 것.
task_struct : PCB
PCB안에 mm이라는 자료구조가 있는데, 이것은 mm_struct를 가리키는 포인터이다.
→ mm_struct안에 pgd에는 해당 process와 관련된 page Directory의 base address를 가지고 있음.
→ 만약 해당 process가 schedule이 되면 해당 내용을 CR3의 상위 20비트에 loading을 한다.
→ 그 이후에는 MMU가 physical address로 바꾸는 작업을 해주게 된다. (해당 작업은 hardware가 처리해주는 것) OS입장에서는 CR3의 상위 20bit에 loading만 해주면 된다. 나머지는 MMU가 해당 작업을 수행하게 된다. (즉 kernel 입장에서는 PCB를 잘 관리만 해주면 된다.)
💡
위 그림에서 볼 수 있는 것처럼 HW와 OS가 협력해서 physical address로 변환이 되게 된다.
💡
process의 image에 대한 정보를 담고 있는 것이 mm이다. mm에 대응되는 자료구조는 mm_struct이다.
반응형
Contents
소중한 공감 감사합니다